前言
像 Apache Lucene 这样的全文搜索引擎是为应用程序添加高效的自由文本搜索功能的非常强大的技术。但是,Lucene 在处理对象域模型时存在几个不匹配之处。除其他事项外,必须保持索引的最新状态,并且必须避免索引结构和域模型之间的不匹配以及查询不匹配。
Hibernate Search 解决了这些缺点:它借助于一些注释来索引您的域模型,负责数据库/索引同步,并从自由文本查询中带回常规的托管对象。
为了实现这一点,Hibernate Search 结合了 Hibernate ORM 和 Apache Lucene/Elasticsearch/OpenSearch 的强大功能。
1. 兼容性
1.1. 依赖项
版本 |
注意 |
|
|---|---|---|
Java 运行时 |
11、17 或 21 |
|
Hibernate ORM(用于 Hibernate ORM 映射器) |
6.6.0.Final |
|
Jakarta Persistence(用于 Hibernate ORM 映射器) |
3.1 |
|
Apache Lucene(用于 Lucene 后端) |
9.11.1 |
|
Elasticsearch 服务器(用于 Elasticsearch 后端) |
7.10+ 或 8.x |
大多数旧的次要版本(例如 7.11 或 8.0)不会优先考虑错误修复和新功能。 |
OpenSearch 服务器(用于 Elasticsearch 后端) |
1.3 或 2.x |
其他次要版本可能有效,但不会优先考虑错误修复和新功能。 |
|
如果您从 Maven 获取 Hibernate Search,建议将 Hibernate Search BOM 作为依赖项管理的一部分导入,以使所有其工件版本保持一致 |
|
Elasticsearch 7.11+ 许可
虽然 Elasticsearch 7.10 之前是根据 Apache 许可证 2.0 发布的,但请注意,Elasticsearch 7.11 及更高版本是根据 Elastic 许可证和 SSPL 发布的,它们 不被开源计划视为开源。 只有 Hibernate Search 依赖的低级 Java REST 客户端仍然是开源的。 |
|
OpenSearch
虽然它历史上针对的是 Elastic 的 Elasticsearch 发行版,但 Hibernate Search 也与 OpenSearch 兼容,并定期针对它进行测试;有关更多信息,请参见 兼容性。 本文档中所有引用 Elasticsearch 的部分也适用于 OpenSearch 发行版。 |
1.2. 框架支持
1.2.1. Quarkus
Quarkus 为使用 Elasticsearch 后端 的 Hibernate Search 与 Hibernate ORM 提供了官方扩展,这是一种与其他功能、不同依赖项和不同配置属性紧密集成的扩展。
作为在 Quarkus 中使用 Hibernate Search 的第一步,我们建议您遵循 Quarkus 的 Hibernate Search 指南:它是对 Hibernate Search 的极好的实践介绍,并且它涵盖了 Quarkus 的具体细节。
1.2.2. WildFly
WildFly 包含用于使用 Lucene 后端 或 Elasticsearch 后端 的 Hibernate Search 与 Hibernate ORM 的模块。
要开始在 WildFly 中使用 Hibernate Search,请参见 WildFly 开发者指南中的 Hibernate Search 部分:它涵盖了 WildFly 的所有具体细节。
1.2.3. Spring Boot
Hibernate Search 可以轻松地集成到 Spring Boot 应用程序中。只需阅读以下关于 Spring Boot 的具体细节,然后按照 入门指南 进行操作。
配置属性
application.properties/application.yaml 是 Spring Boot 配置文件,而不是 JPA 或 Hibernate Search 配置文件。在该文件中直接添加以 hibernate.search. 开头的 Hibernate Search 属性将不起作用。
- 当 将 Hibernate Search 与 Hibernate ORM 集成 时
-
使用
spring.jpa.properties.作为 Hibernate Search 属性的前缀,以便 Spring Boot 将这些属性传递给 Hibernate ORM,Hibernate ORM 会将它们传递给 Hibernate Search。例如
spring.jpa.properties.hibernate.search.backend.hosts = elasticsearch.mycompany.com - 当使用 独立 POJO 映射器 时
-
您可以将属性以编程方式传递给
SearchMappingBuilder#property。
依赖项版本
Spring Boot 会在您不知情的情况下自动设置依赖项的版本。虽然这通常是件好事,但有时 Spring Boot 依赖项会稍微过时。因此,建议至少为一些关键依赖项覆盖 Spring Boot 的默认值。
使用 Maven,有几种方法可以覆盖这些版本,具体取决于将 Spring 添加到应用程序的方式。如果您的应用程序的 POM 文件使用 spring-boot-starter-parent 作为其父 POM,那么只需将版本属性添加到您的 POM 的 <properties> 中即可。
<properties>
<hibernate.version>6.6.0.Final</hibernate.version>
<elasticsearch-client.version>8.15.0</elasticsearch-client.version>
<!-- ... plus any other properties of yours ... -->
</properties>|
如果在设置了上面的属性后,您仍然遇到相同版本的库,请检查 Spring Boot 的 BOM 中属性名称是否已更改,如果是,请使用新的属性名称。 |
或者,如果 spring-boot-dependencies 或 spring-boot-starter-parent 被导入到依赖项管理(<dependencyManagement>)中,那么可以通过导入列出我们想要覆盖的依赖项的 BOM,或者通过显式列出具有我们想要使用的版本的依赖项来覆盖版本。
<dependencyManagement>
<dependencies>
<!--
Overriding Hibernate ORM version by importing the BOM.
Alternatively, can be done by adding specific dependencies
as shown below for Elasticsearch dependencies.
-->
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-platform</artifactId>
<version>${version.org.hibernate.orm}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>3.3.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--
Since there is no BOM for the Elasticsearch REST client,
these dependencies have to be listed explicitly:
-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.15.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client-sniffer</artifactId>
<version>8.15.0</version>
</dependency>
<!-- Other dependency management entries -->
</dependencies>
</dependencyManagement>对于其他构建工具,请参阅其文档以了解详细信息。
|
Maven 的 |
|
如果在设置了上面的属性后,您仍然遇到一些 Hibernate Search 依赖项的问题(例如 |
应用程序在启动时挂起
Spring Boot 2.3.x 及更高版本受一个 bug 的影响,该 bug 会导致应用程序在使用 Hibernate Search 时启动时挂起,尤其是在使用自定义组件(自定义桥接器、分析配置器等)时。
这个问题并不局限于 Hibernate Search,已报告,但在 Spring Boot 2.5.1 中尚未修复。
作为一种解决方法,您可以将属性spring.data.jpa.repositories.bootstrap-mode设置为deferred,如果这不起作用,则设置为default。有趣的是,使用@EnableJpaRepositories(bootstrapMode = BootstrapMode.DEFERRED)据报道即使在将spring.data.jpa.repositories.bootstrap-mode设置为deferred不起作用的情况下也能正常工作。
或者,如果您不需要在自定义组件中进行依赖注入,您可以使用前缀constructor:引用这些组件,这样 Hibernate Search 甚至不会尝试使用 Spring 来检索组件,从而避免 Spring 中的死锁。有关更多信息,请参阅此部分。
Spring Boot 的 Elasticsearch 客户端和自动配置
如您所知,Spring Boot 包含“自动配置”,它会在类路径中检测到依赖项后立即触发。
在某些情况下,当应用程序使用依赖项但不通过 Spring Boot 使用时,这可能会导致问题。
特别是,Hibernate Search 会传递性地引入对 Elasticsearch 的低级 REST 客户端的依赖。Spring Boot 通过ElasticsearchRestClientAutoConfiguration,将在检测到对 Elasticsearch REST 客户端 JAR 的依赖后,自动设置一个指向(默认情况下)https://:9200 的 Elasticsearch REST 客户端。
如果您的 Elasticsearch 集群无法在https://:9200访问,这可能会导致启动时出现错误。
要消除这些错误,请手动配置 Spring 的 Elasticsearch 客户端,或禁用此特定自动配置。
|
Spring Boot 的 Elasticsearch 客户端与 Hibernate Search 完全独立:一个的配置不会影响另一个。 |
2. Hibernate Search 入门
要开始使用 Hibernate Search,请查看以下指南
-
如果您的实体在 Hibernate ORM 中定义,请参阅在 Hibernate ORM 中使用 Hibernate Search 入门。
-
如果您的实体不在 Hibernate ORM 中定义,请参阅使用 Hibernate Search 的独立 POJO 映射器入门。
3. 迁移
如果您要将现有应用程序从早期版本的 Hibernate Search 升级到最新版本,请务必查看迁移指南。
|
对于 Hibernate Search 5 用户 如果您从 Maven 存储库中提取我们的工件,并且您来自 Hibernate Search 5,请注意,仅仅将版本号提升是不够的。 特别是,组 ID 从 此外,请注意,许多 API 已经改变,有些仅仅是因为包的改变,而另一些则是由于更根本的改变(例如,不再在 Hibernate Search API 中使用 Lucene 类型)。因此,建议您首先使用6.0 迁移指南迁移到 Hibernate Search 6.0,然后迁移到更高版本(这将容易得多)。 |
4. 概念
4.1. 全文搜索
全文搜索是一组用于在文本文档语料库中搜索最匹配给定查询的文档的技术。
与传统搜索(例如在 SQL 数据库中)的主要区别在于,存储的文本不被视为单个文本块,而是被视为标记(词语)的集合。
Hibernate Search 依赖于Apache Lucene或Elasticsearch来实现全文搜索。由于 Elasticsearch 在内部使用 Lucene,因此它们共享许多特征,并且它们对全文搜索的总体方法也类似。
为了简化,这些搜索引擎基于倒排索引的概念:一个字典,其中键是文档中找到的标记(词语),值是包含此标记的每个文档的标识符列表。
仍然简化,一旦所有文档都被索引,搜索文档将涉及三个步骤
-
从查询中提取标记(词语);
-
在索引中查找这些标记以查找匹配的文档;
-
聚合查找结果以生成匹配文档列表。
|
Lucene 和 Elasticsearch 不仅限于文本搜索:还支持数值数据,从而支持整数、双精度数、长整数、日期等。这些类型使用稍微不同的方法进行索引和查询,显然不涉及文本处理。 |
4.2. 实体类型
在应用程序的域模型方面,Hibernate Search 区分了被视为实体的类型(Java 类)和那些不被视为实体的类型。
Hibernate Search 中实体类型的决定性特征是它们的实例具有不同的生命周期:实体实例可以保存到数据存储中,也可以从数据存储中检索,而无需保存或检索其他类型的实例。为此,假设每个实体实例都带有不可变的唯一标识符。
这些特征允许 Hibernate Search 将实体类型映射到索引,但只能映射实体类型。“嵌入式”类型从实体中引用或包含在实体中,但其生命周期完全与实体相关联,不能映射到索引。
Hibernate Search 的多个方面涉及实体类型的概念
-
每个实体类型都有一个实体名称,它与类型名称不同。例如,对于名为
com.acme.Book的类,实体名称可以是Book(默认值)或任何任意选择的字符串。 -
指向实体类型的属性(称为关联)具有特定的机制;特别是,为了处理重新索引,Hibernate Search 需要了解关联的逆向。
-
为了在重新索引时进行更改跟踪(例如,在索引计划中),实体类型代表 Hibernate Search 考虑的最小范围。
这意味着代表“已更改属性”的路径始终以实体为起点,并且这些路径中的组件永远不会进入另一个实体(但可能指向一个实体,当关联更改时)。
-
Hibernate Search 可能需要额外的配置来启用从外部数据存储中加载实体类型,无论是从外部源加载匹配查询的实体,还是从外部源加载所有实体实例以进行完全重新索引。
4.3. 映射
Hibernate Search 的目标应用程序使用基于实体的模型来表示数据。在这个模型中,每个实体都是一个具有几个原子类型属性(String、Integer、LocalDate等)的单个对象。每个实体可以包含非根聚合(“嵌入式”类型),并且每个实体也可以与一个或多个其他实体建立多个关联。
相比之下,Lucene 和 Elasticsearch 使用文档。每个文档都是“字段”的集合,每个字段都被分配一个名称(一个唯一的字符串)和一个值(可以是文本,也可以是数值数据,例如整数或日期)。字段也具有类型,这不仅决定了值的类型(文本/数值),而且更重要的是决定了该值存储的方式:索引、存储、使用文档值等。每个文档可以包含嵌套的聚合(“对象”/“嵌套文档”),但实际上不能在顶层文档之间建立关联。
因此
-
实体被组织成一个图,其中每个节点都是一个实体,每个关联都是一条边。
-
文档被组织成一个树的集合(充其量),其中每棵树都是一个文档,可以选择包含嵌套文档。
实体模型和文档模型之间存在多个不匹配:简单属性类型与更复杂的字段类型,关联与无关联,图与树的集合。
在 Hibernate Search 中,映射的目标是通过定义如何将一个或多个实体转换为文档,以及如何将搜索命中解析回原始实体来解决这些不匹配。这是 Hibernate Search 的主要附加值,是其他所有内容的基础,从索引到各种搜索 DSL。
映射通常使用实体模型中的注释进行配置,但这也可以通过编程 API 实现。要详细了解如何配置映射,请参阅 将实体映射到索引。
要了解如何索引生成的文档,请参阅 索引实体(提示:对于Hibernate ORM 集成,它是自动的)。
要了解如何使用利用映射更接近实体模型的 API 进行搜索,特别是通过返回实体作为命中而不是仅返回文档标识符,请参阅 搜索。
4.4. 绑定
虽然映射定义是声明性的,但这些声明需要被解释并实际应用于域模型。
这就是 Hibernate Search 所谓的“绑定”:在启动时,给定的映射指令(例如 `@GenericField`)将导致一个“绑定器”实例化并被调用,使其有机会检查应用于域模型的那一部分,并“绑定”(分配)一个组件到该模型部分——例如一个“桥”,负责在索引过程中从实体中提取数据。
Hibernate Search 为许多常见用例提供了绑定器和桥梁,并且还提供了插入自定义绑定器和桥梁的功能。
有关更多信息,特别是关于如何插入自定义绑定器和桥梁,请参阅 绑定和桥梁。
4.5. 分析
如 全文搜索 中所述,全文引擎在词元上工作,这意味着文本必须在索引时(文档处理,用于构建词元 → 文档索引)和搜索时(查询处理,用于生成要查找的词元列表)进行处理。
但是,处理不仅仅是“词元化”。索引查找是**精确**查找,这意味着查找 `Great`(大写)不会返回仅包含 `great`(全小写)的文档。在处理文本时执行一个额外的步骤来解决此问题:词元过滤,它会规范词元。由于这种“规范化”,`Great` 将被索引为 `great`,因此对查询 `great` 进行索引查找将按预期匹配。
在 Lucene 世界(Lucene、Elasticsearch、Solr,…)中,在索引和搜索阶段期间对文本进行处理被称为“分析”,并且由“分析器”执行。
分析器由三种类型的组件组成,它们将依次按以下顺序处理文本
-
字符过滤器:转换输入字符。替换、添加或删除字符。
-
词元化器:将文本拆分为几个词,称为“词元”。
-
词元过滤器:转换词元。替换、添加或删除词元中的字符,从现有词元中派生新词元,根据某些条件删除词元,…
词元化器通常在空格处分割(尽管还有其他选项)。词元过滤器通常是自定义发生的地方。它们可以删除带重音符号的字符,删除无意义的后缀(`-ing`、`-s`,…)或词元(`a`、`the`,…),用选定的拼写替换词元(`wi-fi` ⇒ `wifi`)等。
|
字符过滤器虽然有用,但很少使用,因为它们不了解词元边界。 除非你知道你在做什么,否则你通常应该优先考虑词元过滤器。 |
在某些情况下,需要将文本以一个块的形式进行索引,而不进行任何词元化
-
对于某些类型的文本,例如 SKU 或其他业务代码,词元化根本没有意义:文本是一个单一的“关键字”。
-
对于按字段值排序,词元化是不必要的。在 Hibernate Search 中它也是被禁止的,因为性能问题;只有非词元化的字段才能排序。
为了解决这些用例,提供了一种特殊类型的分析器,称为“规范化器”。规范化器只是保证不使用词元化器的分析器:它们只能使用字符过滤器和词元过滤器。
在 Hibernate Search 中,分析器和规范化器通过其名称引用,例如 在定义全文字段时。分析器和规范化器具有两个单独的命名空间。
某些名称已经分配给内置分析器(特别是在 Elasticsearch 中),但可以(也建议)将名称分配给自定义分析器和规范化器,这些分析器和规范化器使用内置组件(词元化器、过滤器)组装起来以满足您的特定需求。
每个后端都公开其自己的 API 来定义分析器和规范化器,以及通常配置分析。有关更多信息,请参阅每个后端的文档
4.6. 提交和刷新
为了在索引和搜索时获得最佳吞吐量,Elasticsearch 和 Lucene 都依赖于在写入和读取索引时的“缓冲区”。
-
在写入时,更改不会直接写入索引,而是写入一个“索引写入器”,它在内存中或临时文件中缓冲更改。
当写入器提交时,更改会被“推送到”实际的索引。在提交发生之前,未提交的更改处于“不安全”状态:如果应用程序崩溃或服务器发生断电,未提交的更改将丢失。
-
在读取时,例如执行搜索查询时,数据不会直接从索引中读取,而是从“索引读取器”中读取,该读取器公开索引在过去某个时间点的视图。
当读取器刷新时,视图会被更新。在刷新发生之前,搜索查询的结果可能略微过时:自上次刷新后添加的文档将缺失,自上次刷新后删除的文档仍然存在,等等。
不安全的更改和不同步的索引显然是不可取的,但它们是提高性能的折衷方案。
不同的因素会影响刷新和提交的时间
-
监听器触发的索引 和 显式索引 默认情况下将要求在每组更改后执行索引写入器的提交,这意味着更改在 Hibernate ORM 事务提交返回后是安全的(对于 Hibernate ORM 集成)或 `SearchSession` 的 `close()` 方法返回后(对于 独立 POJO 映射器)。但是,默认情况下不会请求刷新,这意味着更改可能只在稍后,当后端决定刷新索引读取器时才可见。此行为可以通过设置不同的 同步策略 来自定义。
-
批量索引器 在批量索引结束之前不会要求任何提交或刷新,以最大限度地提高索引吞吐量。
-
无论何时没有特定的提交或刷新要求,都会应用后端默认设置
-
可以通过 `flush()` API 显式强制执行提交。
-
可以通过 `refresh()` API 显式强制执行刷新。
|
即使我们使用“提交”一词,但这与关系数据库事务中的提交概念不同:没有事务,并且无法“回滚”。 也没有隔离的概念。刷新后,所有对索引的更改都会被考虑在内:那些提交到索引的更改,以及那些仍然缓存在索引写入器中的更改。 因此,提交和刷新可以被视为完全正交的概念:某些设置偶尔会导致提交的更改在搜索查询中不可见,而其他设置则允许甚至未提交的更改在搜索查询中可见。 |
4.7. 分片和路由
分片是指将索引数据拆分为多个“更小的索引”,称为分片,以便在处理大量数据时提高性能。
在 Hibernate Search 中,与 Elasticsearch 类似,另一个与分片密切相关的概念是路由。路由是指将文档标识符或通常称为“路由键”的任何字符串解析到相应的分片。
在索引时
-
从被索引的实体生成一个文档标识符,以及可选的路由键。
-
文档及其标识符以及可选的路由键传递给后端。
-
后端将文档“路由”到正确的分片,并将路由键(如果有)添加到文档中的特殊字段(以便进行索引)。
-
文档在该分片中被索引。
在搜索时
-
搜索查询可以选择传递一个或多个路由键。
-
如果没有传递路由键,查询将在所有分片上执行。
-
如果传递了一个或多个路由键
-
后端将这些路由键解析为一组分片,并且查询只会在所有分片上执行,忽略其他分片。
-
一个过滤器被添加到查询中,以便只匹配使用给定路由键之一进行索引的文档。
-
因此,分片可以通过两种方式来提高性能
-
在索引时:分片索引可以将“压力”分散到多个分片,这些分片可以位于不同的磁盘(Lucene)或不同的服务器(Elasticsearch)上。
-
在搜索时:如果一个属性,我们称之为 `category`,经常被用来选择一个文档子集,这个属性可以 在映射中定义为路由键,以便它被用来路由文档而不是文档 ID。因此,具有相同 `category` 值的文档将被索引到同一个分片中。然后在搜索时,如果一个查询已经过滤了文档,以便已知命中将具有相同的 `category` 值,则该查询可以手动 路由到包含具有此值的文档的分片,并且可以忽略其他分片。
要启用分片,需要一些配置
|
分片本质上是静态的:预期每个索引都具有相同的分片,以及相同的标识符,从一个启动到另一个启动。更改分片的数量或它们的标识符将需要完全重新索引。 |
5. 架构
5.1. Hibernate Search 的组件
从用户的角度来看,Hibernate Search 包含两个组件
- 映射器
-
映射器将用户模型“映射”到索引模型,并提供与用户模型一致的 API 来执行索引和搜索。
大多数应用程序依赖于 Hibernate ORM 映射器,它提供了索引 Hibernate ORM 实体属性的功能,但还有一个 独立 POJO 映射器,可以在没有 Hibernate ORM 的情况下使用。
映射器部分通过域模型上的注释进行配置,部分通过配置属性进行配置。
- 后端
-
后端是全文引擎的抽象,在这里“事情得到完成”。它实现通用的索引和搜索接口,供映射器通过“索引管理器”使用,每个索引管理器提供对一个索引的访问。
例如,Lucene 后端 委托给 Lucene 库,而 Elasticsearch 后端 委托给远程 Elasticsearch 集群。
后端配置部分由映射器完成,它告诉后端哪些索引必须存在以及它们必须包含哪些字段,部分通过配置属性完成。
映射器和后端协同工作以提供三个主要功能
- 批量索引
-
这是 Hibernate Search 根据数据库内容从零开始重建索引的方式。
映射器查询数据库以检索每个实体的标识符,然后分批处理这些标识符,加载实体,然后处理它们以生成发送到后端进行索引的文档。后端将文档放入内部队列,并将分批在后台进程中索引文档,并在完成时通知映射器。
有关详细信息,请参阅 使用
MassIndexer索引大量数据。 - 显式和侦听器触发的索引
-
显式和侦听器触发的索引依赖于索引计划(
SearchIndexingPlan)以索引特定实体,因为它们受到有限更改的影响。使用 显式索引,调用者显式地将有关实体更改的信息传递给 索引计划;使用 侦听器触发的索引,实体更改由 Hibernate ORM 集成(存在一些例外)透明地检测到,并自动添加到索引计划中。
侦听器触发的索引仅在 Hibernate ORM 集成 的上下文中才有意义;独立 POJO 映射器中没有此功能。 在这两种情况下,索引计划 都将根据这些更改推断出是否需要重新索引实体,无论是更改的实体本身还是 索引中嵌入更改实体的其他实体。
在事务提交时,索引计划中的更改将被处理(在同一线程中或在后台进程中,具体取决于 协调策略),并生成文档,然后发送到后端进行索引。后端将文档放入内部队列,并将分批在后台进程中索引文档,并在完成时通知映射器。
有关详细信息,请参阅 隐式,侦听器触发的索引。
- 搜索
-
这是 Hibernate Search 提供查询索引的方法。
映射器公开对搜索 DSL 的入口点,允许选择要查询的实体类型。选择一个或多个实体类型后,映射器将委托给相应的索引管理器以提供搜索 DSL 并最终创建搜索查询。在查询执行时,后端向映射器提交一个实体引用的列表,映射器加载相应的实体。然后,查询返回这些实体。
有关详细信息,请参阅 搜索。
5.2. 架构示例
5.2.1. 概述
| 架构 | 带有 Lucene 的单节点 | 与 Elasticsearch 无协调 | 带有 Elasticsearch 的出站箱轮询 |
|---|---|---|---|
兼容 映射器 |
同时支持 Hibernate ORM 集成 和 独立 POJO 映射器 |
仅支持 Hibernate ORM 集成 |
|
应用程序拓扑 |
单节点 |
单节点或多节点 |
|
需要维护的额外内容 |
文件系统上的索引 |
Elasticsearch 集群 |
|
索引更新保证 |
|||
索引更新可见性 |
|||
原生功能 |
主要面向专家 |
面向所有人 |
|
应用程序线程开销 |
|||
数据库开销 |
|||
对数据库模式的影响 |
无 |
||
侦听器触发的索引忽略:JPQL/SQL 查询,非对称关联更新 |
|||
在极少数情况下,索引可能不同步:并发 |
没有其他已知局限性 |
||
5.2.2. 带有 Lucene 后端的单节点应用程序
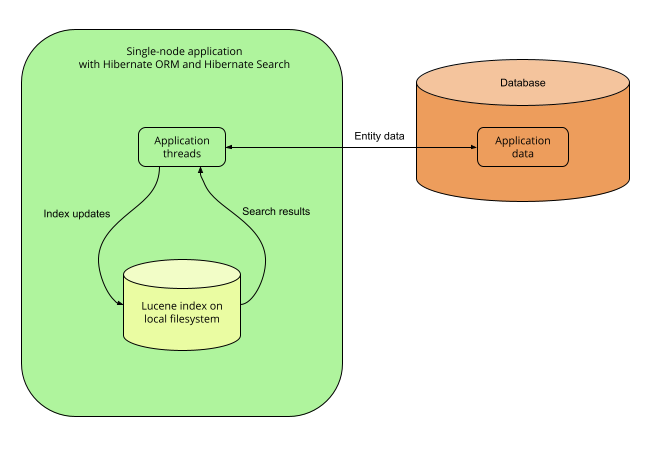
优缺点
优点
-
简单:不需要外部服务,所有内容都位于同一台服务器上。
-
索引更新的即时可见性(〜毫秒)。虽然其他架构在大多数用例中也能表现出类似的性能,但对于需要在数据库更改后立即可见更改的索引,单节点 Lucene 后端是最佳选择。
缺点
-
不太容易扩展:经验丰富的开发人员可以访问很多 Lucene 功能,即使是 Hibernate Search 未公开的那些功能,也可以通过提供原生 Lucene 对象来访问;但是,对于不熟悉 Lucene 的开发人员来说,Lucene API 并不容易理解。如果你感兴趣,请参阅 基于
Query的谓词。 -
应用程序线程开销:重新索引直接在应用程序线程中完成,并且可能需要额外的时间从数据库中加载必须索引的数据。根据要加载的数据量,这可能会增加应用程序的延迟和/或降低其吞吐量。
-
没有横向可扩展性:只能有一个应用程序节点,所有索引都必须位于同一台服务器上。
入门
要实现此架构,请使用以下 Maven 依赖项
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm</artifactId>
<version>7.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-backend-lucene</artifactId>
<version>7.2.0.Final</version>
</dependency>- 使用 独立 POJO 映射器(没有 Hibernate ORM)
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-pojo-standalone</artifactId>
<version>7.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-backend-lucene</artifactId>
<version>7.2.0.Final</version>
</dependency>5.2.3. 单节点或多节点应用程序,没有协调,并使用 Elasticsearch 后端
描述
使用 Elasticsearch 后端,索引不会绑定到应用程序节点。它们由一个单独的 Elasticsearch 节点集群管理,并通过对 REST API 的调用来访问。
因此,可以设置多个应用程序节点,以便它们以一种方式独立地执行索引更新和搜索查询,而无需相互协调。
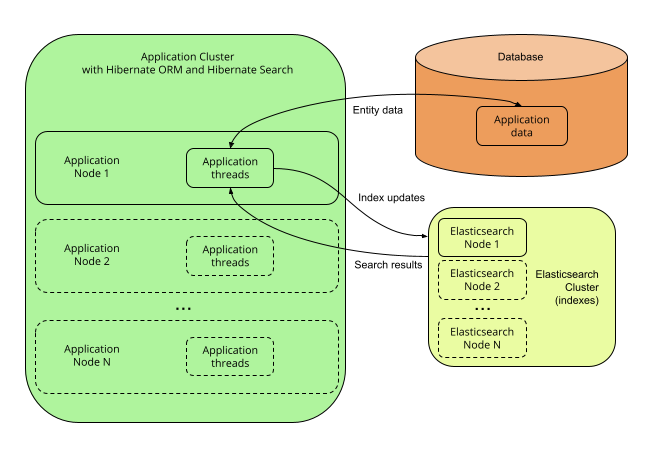
| Elasticsearch 集群可以是一个单节点,它与应用程序位于同一台服务器上。 |
优缺点
优点
-
易于扩展:您可以轻松地访问大多数 Elasticsearch 功能,即使是 Hibernate Search 未公开的那些功能,也可以通过提供自己的 JSON 来访问。例如,请参阅 JSON 定义的谓词,或 JSON 定义的聚合,或 利用 JSON 操作高级功能。
-
索引的横向可扩展性:您可以根据需要调整 Elasticsearch 集群的大小。请参阅 "Elasticsearch 文档中的可扩展性和弹性"。
-
应用程序的横向可扩展性:您可以根据需要拥有任意多个应用程序实例(尽管高并发会增加此架构出现某些问题的可能性,请参阅下面的“缺点”)。
缺点
-
需要管理一项额外的服务:Elasticsearch 集群。
-
应用程序线程开销:重新索引直接在应用程序线程中完成,并且可能需要额外的时间从数据库中加载必须索引的数据。根据要加载的数据量,这可能会增加应用程序的延迟和/或降低其吞吐量。
-
索引更新的延迟可见性(〜1 秒)。虽然可以在数据库更改后尽快使更改可见,但 Elasticsearch 本质上是 近实时,如果你需要在数据库更改后立即可见更改,那么它的性能不会很好。
入门
要实现此架构,请使用以下 Maven 依赖项
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm</artifactId>
<version>7.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-backend-elasticsearch</artifactId>
<version>7.2.0.Final</version>
</dependency>- 使用 独立 POJO 映射器(没有 Hibernate ORM)
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-pojo-standalone</artifactId>
<version>7.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-backend-elasticsearch</artifactId>
<version>7.2.0.Final</version>
</dependency>5.2.4. 带有出站箱轮询和 Elasticsearch 后端的多节点应用程序
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
描述
使用 Hibernate Search 的 outbox-polling 协调策略,实体更改事件不会在产生它们的 ORM 会话中立即处理,而是被推送到数据库中的出站箱表中。
一个后台进程轮询该出站箱表以获取新事件,并异步处理它们,根据需要更新索引。由于该队列 可以进行分片,因此多个应用程序节点可以共享索引的工作负载。
这需要 Elasticsearch 后端,以便索引不会绑定到单个应用程序节点,并且可以从多个应用程序节点进行更新或查询。
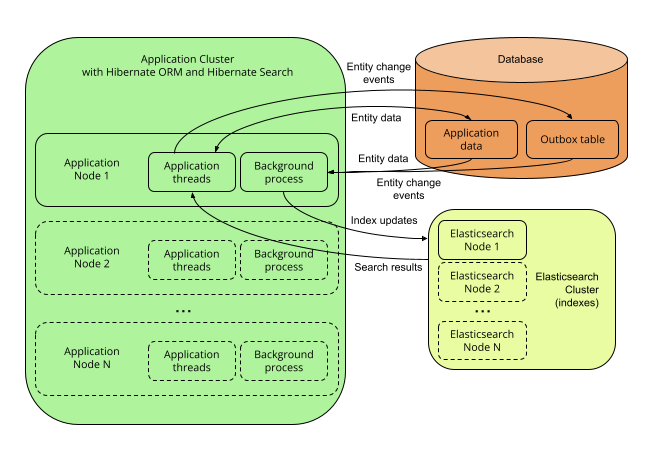
优缺点
优点
-
最安全
-
这里消除了其他架构中由于 后端中的索引错误 而导致索引不同步的可能性,因为实体更改事件 在与实体更改相同的事务中持久化,允许无限次重试。
-
这里消除了其他架构中由于 并发更新 而导致索引不同步的可能性,因为 在重新索引之前,每个实体实例都在一个新事务中从数据库中重新加载。
-
-
易于扩展:您可以轻松地访问大多数 Elasticsearch 功能,即使是 Hibernate Search 未公开的那些功能,也可以通过提供自己的 JSON 来访问。例如,请参阅 JSON 定义的谓词,或 JSON 定义的聚合,或 利用 JSON 操作高级功能。
-
应用程序线程开销最小:应用程序线程 只需要将事件追加到队列中,它们本身不执行重新索引。
-
索引的横向可扩展性:您可以根据需要调整 Elasticsearch 集群的大小。请参阅 "Elasticsearch 文档中的可扩展性和弹性"。
-
应用程序的横向可扩展性:您可以根据需要拥有任意多个应用程序实例。
缺点
-
需要管理一项额外的服务:Elasticsearch 集群。
-
索引更新的延迟可见性(〜1 秒或更长,具体取决于负载和硬件)。首先是因为 Elasticsearch 本质上是 近实时,但也是因为 事件队列引入了额外的延迟。
-
对数据库模式的影响:必须在数据库中创建额外的表格 以保存协调所需的数据。
-
数据库开销:读取实体更改并执行重新索引的后台进程 需要从数据库中读取已更改的实体。
入门
outbox-polling 协调策略需要额外的依赖项。要实现此架构,请使用以下 Maven 依赖项
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm</artifactId>
<version>7.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm-outbox-polling</artifactId>
<version>7.2.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-backend-elasticsearch</artifactId>
<version>7.2.0.Final</version>
</dependency>- 使用 独立 POJO 映射器(没有 Hibernate ORM)
-
目前,无法使用独立 POJO 映射器实现此架构,因为此映射器 不支持协调。
此外,请按照outbox-polling: 后台处理器中的附加事件表和轮询中所述配置协调。
6. Hibernate ORM 集成
6.2. 启动
Hibernate Search 集成到 Hibernate ORM 中,将在 Hibernate ORM 同时启动,只要它存在于类路径中。
如果由于某种原因需要阻止 Hibernate Search 启动,请将 布尔属性 hibernate.search.enabled 设置为 false。
6.3. 关闭
Hibernate Search 集成到 Hibernate ORM 中,将在 Hibernate ORM 同时停止。
在关闭时,Hibernate Search 将停止接受新的索引请求:新的索引尝试将抛出异常。Hibernate ORM 关闭将阻塞,直到所有正在进行的索引操作完成。
6.4. 映射 Map 驱动的模型
"动态映射" 实体模型,即基于 java.util.Map 而不是自定义类的模型,无法使用注释进行映射。但是,它们可以使用 编程映射 API 进行映射。您只需使用 context.programmaticMapping().type("thename") 按名称引用类型即可
-
传递动态实体类型的实体名称。
-
传递动态嵌入/组件类型的“角色”,即拥有实体的名称,后跟一个点("."),后跟该实体中组件的点分隔路径。例如
MyEntity.myEmbedded或MyEntity.myEmbedded.myNestedEmbedded。
6.5. 使用非字符串租户标识符的多租户
虽然使用 Hibernate ORM 中的字符串租户标识符在 Hibernate Search 中具有内置支持,但使用非字符串租户标识符需要配置自定义租户标识符转换器。这可以通过将 TenantIdentifierConverter 类型的 bean 引用传递给 hibernate.search.multi_tenancy.tenant_identifier_converter 配置属性来完成。
6.6. 其他配置
其他配置属性在本文档的相关部分中提到。您可以在 ORM 集成配置属性附录 中找到可用属性的完整参考。
7. 独立 POJO 映射器
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
7.1. 基础
独立 POJO 映射器 使得能够将任意 POJO 映射到索引。
与 Hibernate ORM 集成 相比,其主要功能是可以不使用 Hibernate ORM 或关系数据库运行。
它可用于索引来自任意数据存储的实体,甚至(尽管这通常不推荐)使用 Lucene 或 Elasticsearch 作为主要数据存储。
因为独立 POJO 映射器除了实体以 POJO 的形式表示之外,对要映射的实体没有假设任何东西,因此它可能比 Hibernate ORM 集成 更复杂。特别地
-
此映射器 无法自行检测实体更改:所有索引 必须是显式的。
-
此映射器 目前不提供节点之间的协调。
7.2. 启动
使用独立 POJO 映射器启动 Hibernate Search 是显式的,并涉及一个构建器
CloseableSearchMapping searchMapping =
SearchMapping.builder( AnnotatedTypeSource.fromClasses( (1)
Book.class, Associate.class, Manager.class
) )
.property(
"hibernate.search.backend.hosts", (2)
"elasticsearch.mycompany.com"
)
.build(); (3)
| 1 | 创建一个构建器,传递一个 AnnotatedTypeSource,让 Hibernate Search 知道在哪里查找注释。 |
| 2 | 设置其他配置属性(另请参见 配置)。 |
| 3 | 构建 SearchMapping。 |
7.3. 关闭
您可以通过在映射上调用 close() 方法来关闭使用独立 POJO 映射器的 Hibernate Search
CloseableSearchMapping searchMapping = /* ... */ (1)
searchMapping.close(); (2)| 1 | 检索 Hibernate Search 启动时 返回的 SearchMapping。 |
| 2 | 调用 close() 以关闭 Hibernate Search。 |
在关闭时,Hibernate Search 将停止接受新的索引请求:新的索引尝试将抛出异常。close() 方法仅在所有正在进行的索引操作完成后才会返回。
7.4. Bean 提供程序
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
独立 POJO 映射器可以 从 CDI/Spring 中检索 bean,但这种支持需要通过 bean 提供程序显式实现。
您可以在两个步骤中插入自己的 bean 提供程序
-
定义一个实现
org.hibernate.search.engine.environment.bean.spi.BeanProvider接口的类。 -
通过将配置属性
hibernate.search.bean_provider设置为指向实现的 bean 引用(例如class:com.mycompany.MyMappingConfigurer)来配置 Hibernate Search 以使用该实现。显然,bean 提供程序的引用无法使用 bean 提供程序解析。
7.5. 多租户
在启动独立 POJO 映射器时,需要显式启用多租户
CloseableSearchMapping searchMapping = SearchMapping.builder( AnnotatedTypeSource.fromClasses( (1)
Book.class
) )
// ...
.property( "hibernate.search.mapping.multi_tenancy.enabled", true ) (2)
.build(); (3)| 1 | 创建一个构建器。 |
| 2 | 启用多租户。 |
| 3 | 构建 SearchMapping。 |
SearchSessionSearchMapping searchMapping = /* ... */ (1)
Object tenantId = "myTenantId";
try ( SearchSession searchSession = searchMapping.createSessionWithOptions() (2)
.tenantId( tenantId ) (3)
.build() ) { (4)
// ...
}| 1 | 检索 SearchMapping. |
| 2 | 开始创建一个新会话。 |
| 3 | 为新会话设置租户标识符。 |
| 4 | 构建新会话。 |
|
使用非字符串租户标识符时,必须提供自定义
|
7.6. 映射
虽然 Hibernate ORM 集成 可以从 Hibernate ORM 映射推断出映射的一部分,但独立 POJO 映射器不能。因此,独立 POJO 映射器需要对其映射进行更显式的配置
7.7. 索引
7.7.2. 在实体更改事件上显式索引
独立 POJO 映射器可以处理实体更改事件(添加、更新、删除)并相应地执行索引,尽管必须将事件显式传递给 Hibernate Search。有关 API 的更多信息,请参见 索引计划。
与 Hibernate ORM 集成 的一个主要区别是,事务(JTA 或其他)不受支持,因此索引是在 会话关闭 时执行的,而不是在事务提交时执行的。
7.7.3. 批量索引
因为默认情况下,独立 POJO 映射器对实体数据来自哪里一无所知,因此 批量索引 需要插入一种从其他数据存储中加载实体的方式:批量加载策略。
7.7.4. 搜索查询中的实体加载
因为默认情况下,独立 POJO 映射器对实体数据来自哪里一无所知,因此 搜索查询中的实体加载 需要插入一种从其他数据存储中加载实体选择的方式:选择加载策略。
|
使用独立 POJO 映射器,如果您希望从索引加载实体,而不是从外部数据源加载实体,请在您的实体类型中添加一个 投影构造函数。 当此部分描述的配置缺失并且需要加载时(例如,当不在搜索查询中使用 |
7.8. 协调
独立 POJO 映射器目前不提供任何在节点之间进行协调的方法,因此其行为大致类似于 无协调 中描述的行为,除了实体数据提取是在会话关闭时发生的,而不是在 Hibernate ORM 会话刷新时发生的,并且索引是在此之后立即发生的,而不是在事务提交时发生的。
7.9. 从文件读取配置属性
独立 POJO 映射器 SearchMappingBuilder 还可以从与 java.util.Properties#load(Reader) 兼容的 Reader 中获取属性
Reader 从文件加载配置属性try (
Reader propertyFileReader = /* ... */ (1)
) {
CloseableSearchMapping searchMapping = SearchMapping.builder( AnnotatedTypeSource.empty() ) (2)
.properties( propertyFileReader ) (3)
.build();
}| 1 | 获取表示包含配置属性的属性文件的读取器。 |
| 2 | 开始配置独立 POJO 映射器。 |
| 3 | 将属性文件读取器传递给构建器。 |
7.10. 其他配置
其他配置属性在本文档的相关部分中提到。您可以在 独立 POJO 映射器配置属性附录 中找到可用属性的完整参考。
8. 配置
8.1. 配置来源
8.1.1. 集成到 Hibernate ORM 中时的配置来源
当在 Hibernate ORM 中使用 Hibernate Search 时,配置属性将从 Hibernate ORM 中获取。
这意味着无论您在何处设置 Hibernate ORM 属性,您都可以设置 Hibernate Search 属性。
-
在您类路径根目录下的
hibernate.properties文件中。 -
在
persistence.xml中,如果您使用 JPA API 启动 Hibernate ORM。 -
在 JVM 系统属性中(传递给
java命令的-DmyProperty=myValue)。 -
在您的框架的配置文件中,例如
application.yaml/application.properties。
|
当通过您的框架的配置文件设置属性时,配置属性的键可能与本文档中提到的键不同。 例如, 有关更多信息,请参见 框架支持。 |
8.1.2. 使用独立 POJO 映射器的配置源
当在 独立 POJO 映射器(不使用 Hibernate ORM)中使用 Hibernate Search 时,必须在构建映射时以编程方式设置配置属性。
有关更多信息,请参见 本节。
8.2. 配置属性
8.2.1. 配置属性的结构
配置属性都分组在一个公共根目录下。在 ORM 集成中,此根目录为 hibernate.search,但其他集成(Infinispan 等)可能使用不同的根目录。本文档将在所有示例中使用 hibernate.search。
在该根目录下,我们可以区分三类属性。
- 全局属性
-
这些属性可能会影响所有 Hibernate Search。它们通常位于
hibernate.search根目录的正下方。全局属性在本文档的相关部分中解释。
-
以及更多。
- 后端属性
-
这些属性会影响单个后端。它们分组在一个公共根目录下
-
hibernate.search.backend用于默认后端(最常见的用法)。 -
hibernate.search.backends.<backend-name>用于命名后端(高级用法)。
后端属性在本文档的相关部分中解释。
-
- 索引属性
-
这些属性会影响一个或多个索引,具体取决于根目录。
使用根目录
hibernate.search.backend,它们为后端的所有索引设置默认值。使用根目录
hibernate.search.backend.indexes.<index-name>,它们为特定索引设置值,覆盖默认值(如果有)。后端和索引名称必须与映射中定义的名称匹配。对于 Hibernate ORM 实体,默认索引名称是索引类的名称,不包括包:org.mycompany.Book的默认索引名称为Book。索引名称可以在映射中自定义。或者,也可以通过名称引用后端,即上面的根目录也可以是
hibernate.search.backends.<backend-name>或hibernate.search.backends.<backend-name>.indexes.<index-name>。示例
-
hibernate.search.backend.io.commit_interval = 500为默认后端的所有索引设置io.commit_interval属性。 -
hibernate.search.backend.indexes.Product.io.commit_interval = 2000为默认后端的Product索引设置io.commit_interval属性。 -
hibernate.search.backends.myBackend.io.commit_interval = 500为后端myBackend的所有索引设置io.commit_interval属性。 -
hibernate.search.backends.myBackend.indexes.Product.io.commit_interval = 2000为后端myBackend的Product索引设置io.commit_interval属性。
其他索引属性在本文档的相关部分中解释。
-
8.2.2. 以编程方式构建属性键
BackendSettings 和 IndexSettings 都提供工具来帮助构建配置属性键。
- BackendSettings
-
BackendSettings.backendKey(ElasticsearchBackendSettings.HOSTS)等效于hibernate.search.backend.hosts。BackendSettings.backendKey("myBackend", ElasticsearchBackendSettings.HOSTS)等效于hibernate.search.backends.myBackend.hosts。有关可用属性键的列表,请参见 Elasticsearch 后端配置属性附录 或 Lucene 后端配置属性附录。
- IndexSettings
-
IndexSettings.indexKey("myIndex", ElasticsearchIndexSettings.INDEXING_QUEUE_SIZE)等效于hibernate.search.backend.indexes.myIndex.indexing.queue_size。IndexSettings.indexKey("myBackend", "myIndex", ElasticsearchIndexSettings.INDEXING_QUEUE_SIZE)等效于hibernate.search.backends.myBackend.indexes.myIndex.indexing.queue_size。有关可用属性键的列表,请参见 Elasticsearch 后端配置属性附录 或 Lucene 后端配置属性附录。查找以
hibernate.search.backend.indexes开头的变体属性。
private Properties buildHibernateConfiguration() {
Properties config = new Properties();
// backend configuration
config.put( BackendSettings.backendKey( ElasticsearchBackendSettings.HOSTS ), "127.0.0.1:9200" );
config.put( BackendSettings.backendKey( ElasticsearchBackendSettings.PROTOCOL ), "http" );
// index configuration
config.put(
IndexSettings.indexKey( "myIndex", ElasticsearchIndexSettings.INDEXING_MAX_BULK_SIZE ),
20
);
// orm configuration
config.put(
HibernateOrmMapperSettings.INDEXING_PLAN_SYNCHRONIZATION_STRATEGY,
IndexingPlanSynchronizationStrategyNames.ASYNC
);
// engine configuration
config.put( EngineSettings.BACKGROUND_FAILURE_HANDLER, "myFailureHandler" );
return config;
}8.2.3. 配置属性的类型
属性值可以以编程方式设置为 Java 对象,或者通过配置文件设置为必须解析的字符串。
Hibernate Search 中的每个配置属性都分配了一个类型,此类型定义了两种情况下都接受的值。
以下是对所有属性类型的定义。
| 名称 | 接受的 Java 对象 | 接受的字符串格式 |
|---|---|---|
字符串 |
|
任何字符串 |
布尔值 |
|
|
整数 |
|
任何可以由 |
长整数 |
|
任何可以由 |
类型为 T 的 Bean 引用 |
|
参见 Bean 引用的解析 |
当上面任何类型的配置属性被记录为多值时,该属性接受以下任一项:
-
包含任何 Java 对象的
java.util.Collection,这些 Java 对象将被接受为相同类型(参见上文)的单值属性; -
或包含字符串的逗号分隔字符串,这些字符串将被接受为相同类型(参见上文)的单值属性;
-
或接受为相同类型(参见上文)的单值属性的单个 Java 对象。
8.3. 配置属性检查
Hibernate Search 将跟踪实际使用的提供配置的部分,如果任何以“hibernate.search.”开头的配置属性从未使用过,则会记录警告,因为这可能表明配置存在问题。
要禁用此警告,请将 hibernate.search.configuration_property_checking.strategy 属性设置为 ignore。
8.4. Bean
Hibernate Search 允许在各种地方插入对自定义 Bean 的引用:配置属性、映射注释、API 参数等。
本节描述了 支持的框架、如何引用 Bean、如何解析 Bean 以及 如何将其他 Bean 注入 Bean。
8.4.1. 支持的框架
集成到 Hibernate ORM 时支持的框架
当使用 Hibernate Search 集成到 Hibernate ORM 时,所有集成到 Hibernate ORM 的依赖项注入框架都会自动集成到 Hibernate Search 中。
这包括但不限于
当不使用依赖项注入框架,或者当它未集成到 Hibernate ORM 时,只能通过反射来检索 Bean,方法是调用引用的类型的公共无参数构造函数;参见 Bean 解析。
使用独立 POJO 映射器时支持的框架
当使用 独立 POJO 映射器 时,必须 手动插入 依赖项注入支持。
否则,只能通过反射来检索 Bean,方法是调用引用的类型的公共无参数构造函数;参见 Bean 解析。
8.4.2. Bean 引用
Bean 引用由两部分组成
-
类型,即
java.lang.Class。 -
可选的名称,作为
String。
当在配置属性中使用字符串值引用 Bean 时,类型会隐式设置为 Hibernate Search 为该配置属性期望的任何接口。
|
对于有经验的用户,Hibernate Search 还提供了 |
8.4.3. Bean 引用的解析
当在配置属性中使用字符串值引用 Bean 时,将解析该字符串。
以下是最常见的格式
-
bean:后跟 Spring 或 CDI Bean 的名称。例如bean:myBean。 -
class:后跟类的完全限定名称,如果可用,则通过 Spring/CDI 实例化,否则通过其公共无参数构造函数实例化。例如class:com.mycompany.MyClass。 -
不包含冒号的任意字符串:它将按 Bean 解析 中的解释进行解释。简而言之
-
首先,查找具有给定名称的内置 Bean;
-
然后尝试从 Spring/CDI(如果可用)中检索具有给定名称的 Bean;
-
然后尝试将字符串解释为完全限定的类名,并从 Spring/CDI(如果可用)中检索相应的 Bean;
-
然后尝试将字符串解释为完全限定的类名,并通过其公共无参数构造函数实例化它。
-
以下格式也被接受,但仅适用于高级用例
-
any:后跟任意字符串。在大多数情况下,等效于省略前缀。仅当任意字符串包含冒号时才有用。 -
builtin:后跟内置 Bean 的名称,例如,Elasticsearch 索引布局策略 的simple。这不会回退到 Spring/CDI 或直接构造函数调用。 -
constructor:后跟类的完全限定名称,通过其公共无参数构造函数实例化。这将忽略内置 Bean,并且不会尝试通过 Spring/CDI 实例化类。
8.4.4. Bean 解析
Bean 解析(即,将此引用转换为对象实例的过程)默认情况下按如下方式进行
-
如果给定的引用与内置 Bean 匹配,则使用该 Bean。
示例:当使用
simple作为属性hibernate.search.backend.layout.strategy的值来配置 Elasticsearch 索引布局策略 时,simple会解析为内置的simple策略。 -
否则,如果 支持的依赖项注入 (DI) 框架 可用,则使用 DI 框架解析引用。
-
如果存在具有给定类型(以及如果提供,名称)的托管 Bean,则使用该 Bean。
示例:名称
myLayoutStrategy用作属性hibernate.search.backend.layout.strategy的值,用于配置Elasticsearch 索引布局策略,解析为 CDI/Spring 中已知的任何类型为IndexLayoutStrategy且带有@Named("myLayoutStrategy")注解的 Bean。 -
否则,如果给定名称且该名称是完全限定类名,并且存在该类型的托管 Bean,则使用该 Bean。
示例:名称
com.mycompany.MyLayoutStrategy用作属性hibernate.search.backend.layout.strategy的值,用于配置Elasticsearch 索引布局策略,解析为 CDI/Spring 中已知的任何扩展com.mycompany.MyLayoutStrategy的 Bean。
-
-
否则,将使用反射来解析 Bean。
-
如果给定名称且该名称是完全限定类名,并且该类扩展了类型引用,则通过调用该类的公共无参数构造函数来创建实例。
示例:名称
com.mycompany.MyLayoutStrategy用作属性hibernate.search.backend.layout.strategy的值,用于配置Elasticsearch 索引布局策略,解析为com.mycompany.MyLayoutStrategy的实例。 -
如果没有给出名称,则通过调用引用类型的公共无参数构造函数来创建实例。
示例:类
com.mycompany.MyLayoutStrategy.class(一个java.lang.Class,而不是String),用作属性hibernate.search.backend.layout.strategy的值,用于配置Elasticsearch 索引布局策略,解析为com.mycompany.MyLayoutStrategy的实例。
-
|
可以通过选择 |
8.4.5. Bean 注入
所有由 Hibernate Search 解析的 Bean 使用支持的框架可以利用此框架的注入功能。
例如,一个 Bean 可以通过在桥的某个字段上使用@Inject注解来注入另一个 Bean。
诸如@PostConstruct之类的生命周期注解也应该按预期工作。
即使不使用任何框架,仍然可以利用BeanResolver。此组件在引导过程中传递到多个方法,它公开多个方法来解析引用到 Bean,以编程方式公开通常通过@Inject注解实现的功能。有关更多信息,请参阅BeanResolver的 javadoc。
8.4.6. Bean 生命周期
一旦 Bean 不再需要,Hibernate Search 将释放它们,并让依赖注入框架调用适当的方法(@PreDestroy,…)。
某些 Bean 只在引导期间需要,例如ElasticsearchAnalysisConfigurer,因此它们将在引导后立即被释放。
其他 Bean 在运行时需要,例如ValueBridge,因此它们将在关闭时被释放。
|
小心地根据需要定义 Bean 的范围。 不可变 Bean 或只使用一次的 Bean,例如 但是,某些 Bean 预计是可变的,并且会实例化多次,例如 |
所有由 Hibernate Search 解析的 Bean 使用支持的框架可以利用此框架的注入功能。
8.5. 全局配置
8.5.1. 背景故障处理
Hibernate Search 通常将发生在后台线程中的异常传播到用户线程,但在某些情况下,例如 Lucene 段合并失败或某些索引计划同步失败,后台线程中的异常无法传播。默认情况下,当发生这种情况时,失败将记录在ERROR级别。
要自定义背景故障处理,您需要
-
定义一个实现
org.hibernate.search.engine.reporting.FailureHandler接口的类。 -
通过将配置属性
hibernate.search.background_failure_handler设置为指向实现的Bean 引用,例如class:com.mycompany.MyFailureHandler,来配置后端以使用该实现。
Hibernate Search 将在每次发生故障时调用handle方法。
FailureHandlerpackage org.hibernate.search.documentation.reporting.failurehandler;
import org.hibernate.search.engine.common.EntityReference;
import org.hibernate.search.engine.reporting.EntityIndexingFailureContext;
import org.hibernate.search.engine.reporting.FailureContext;
import org.hibernate.search.engine.reporting.FailureHandler;
import org.hibernate.search.util.impl.test.extension.StaticCounters;
public class MyFailureHandler implements FailureHandler {
@Override
public void handle(FailureContext context) { (1)
String failingOperationDescription = context.failingOperation().toString(); (2)
Throwable throwable = context.throwable(); (3)
// ... report the failure ... (4)
}
@Override
public void handle(EntityIndexingFailureContext context) { (5)
String failingOperationDescription = context.failingOperation().toString();
Throwable throwable = context.throwable();
for ( EntityReference entityReference : context.failingEntityReferences() ) { (6)
Class<?> entityType = entityReference.type(); (7)
String entityName = entityReference.name(); (7)
Object entityId = entityReference.id(); (7)
String entityReferenceAsString = entityReference.toString(); (8)
// ... process the entity reference ... (9)
}
}
}| 1 | handle(FailureContext)用于不符合任何其他专用handle方法的通用故障。 |
| 2 | 从上下文中获取失败操作的描述。 |
| 3 | 从上下文中获取操作失败时抛出的异常。 |
| 4 | 使用上下文提供的信息以任何相关方式报告故障。 |
| 5 | handle(EntityIndexingFailureContext)用于在索引实体时发生的故障。 |
| 6 | 除了失败的操作和异常之外,上下文还列出了由于故障而无法正确索引的实体的引用。 |
| 7 | 实体引用公开实体类型、名称和标识符。 |
| 8 | 实体引用可以使用toString()转换为人类可读的字符串。 |
| 9 | 使用上下文提供的信息以任何相关方式报告故障。 |
hibernate.search.background_failure_handler = class:org.hibernate.search.documentation.reporting.failurehandler.MyFailureHandler使用 Hibernate Search 配置属性分配背景故障处理程序。
|
当故障处理程序的 |
8.5.2. 多租户
如果您的应用程序使用 Hibernate ORM 的多租户支持,或者如果您在独立 POJO 映射器中显式配置了多租户,Hibernate Search 应该检测到并透明地配置您的后端。有关详细信息,请参阅
在某些情况下,特别是在使用outbox-polling协调策略或期望批量索引器隐式地针对所有租户时,您需要显式列出应用程序可能使用的所有租户标识符。Hibernate Search 在生成应将操作应用于每个租户的后台进程时使用此信息。
标识符列表通过以下配置属性定义
hibernate.search.multi_tenancy.tenant_ids = mytenant1,mytenant2,mytenant3此属性可以设置为包含多个租户标识符(以逗号分隔)的字符串,也可以设置为包含租户标识符的Collection<String>。
9. 主 API 入口点
本节详细介绍了 Hibernate Search API 在运行时的主要入口点,即用于索引、搜索、查找元数据等的 API。
9.1. SearchMapping
9.1.1. 基础知识
SearchMapping是 Hibernate Search API 的最高级入口点:它表示实体到索引的整个映射。
SearchMapping是线程安全的:它可以安全地从多个线程并发使用。但是,这并不意味着它返回的对象(SearchWorkspace,…)本身是线程安全的。
|
Hibernate Search 中的 |
|
一些框架,例如Quarkus,允许您只需将 |
9.1.2. 使用 Hibernate ORM 集成检索SearchMapping
使用Hibernate ORM 集成,SearchMapping在Hibernate ORM 启动时自动创建。
要检索SearchMapping,请调用Search.mapping(…)并传递EntityManagerFactory/SessionFactory
SessionFactory检索SearchMappingSessionFactory sessionFactory = /* ... */ (1)
SearchMapping searchMapping = Search.mapping( sessionFactory ); (2)| 1 | 检索SessionFactory。详细信息取决于您的框架,但这通常通过将其注入到您自己的类中来实现,例如,通过使用@Inject或@PersistenceUnit注解某个该类型的字段。 |
| 2 | 调用Search.mapping(…),将SessionFactory作为参数传递。这将返回SearchMapping。 |
仍然使用Hibernate ORM 集成,可以从 JPA EntityManagerFactory执行相同的操作
EntityManagerFactory检索SearchMappingEntityManagerFactory entityManagerFactory = /* ... */ (1)
SearchMapping searchMapping = Search.mapping( entityManagerFactory ); (2)| 1 | 检索EntityManagerFactory。详细信息取决于您的框架,但这通常通过将其注入到您自己的类中来实现,例如,通过使用@Inject或@PersistenceUnit注解某个该类型的字段。 |
| 2 | 调用Search.mapping(…),将EntityManagerFactory作为参数传递。这将返回SearchMapping。 |
9.1.3. 使用独立 POJO 映射器检索SearchMapping
使用独立 POJO 映射器,SearchMapping是启动 Hibernate Search 的结果。
有关使用独立 POJO 映射器启动 Hibernate Search 的更多信息,请参阅本节。
9.2. SearchSession
9.2.1. 基础知识
SearchSession表示执行一系列相关操作的上下文。它通常应该用于很短的时间,例如处理单个 Web 请求。
SearchSession不是线程安全的:它不能从多个线程并发使用。
|
Hibernate Search 中的 |
|
一些框架,例如Quarkus,允许您只需将 |
9.2.2. 使用 Hibernate ORM 集成检索SearchSession
要使用Hibernate ORM 集成检索SearchSession,请调用Search.session(…)并传递EntityManager/Session
Session检索SearchSessionSession session = /* ... */ (1)
SearchSession searchSession = Search.session( session ); (2)| 1 | 检索Session。详细信息取决于您的框架,但这通常通过将其注入到您自己的类中来实现,例如,通过使用@Inject或@PersistenceContext注解某个该类型的字段。 |
| 2 | 调用Search.session(…),将Session作为参数传递。这将返回SearchSession。 |
仍然使用Hibernate ORM 集成,可以从 JPA EntityManager执行相同的操作
EntityManager检索SearchSessionEntityManager entityManager = /* ... */ (1)
SearchSession searchSession = Search.session( entityManager ); (2)| 1 | 检索EntityManager。详细信息取决于您的框架,但这通常通过将其注入到您自己的类中来实现,例如,通过使用@Inject或@PersistenceContext注解某个该类型的字段。 |
| 2 | 调用Search.mapping(…),将EntityManager作为参数传递。这将返回SearchSession。 |
9.2.3. 使用独立 POJO 映射器检索SearchSession
使用 独立 POJO 映射器 时,应显式创建和关闭 SearchSession。
SearchSessionSearchMapping searchMapping = /* ... */ (1)
try ( SearchSession searchSession = searchMapping.createSession() ) { (2)
// ...
}| 1 | 检索 SearchMapping. |
| 2 | 创建一个新会话。请注意,我们使用的是 try-with-resources 块,因此会话将在我们完成操作时自动关闭,这将特别触发 索引计划 的执行。 |
|
忘记关闭 |
SearchSession 也可以配置一些选项。
SearchSessionSearchMapping searchMapping = /* ... */ (1)
Object tenantId = "myTenant";
try ( SearchSession searchSession = searchMapping.createSessionWithOptions() (2)
.indexingPlanSynchronizationStrategy( IndexingPlanSynchronizationStrategy.sync() )(3)
.tenantId( tenantId )
.build() ) { (4)
// ...
}| 1 | 检索 SearchMapping. |
| 2 | 开始创建一个新会话。请注意,我们使用的是 try-with-resources 块,因此会话将在我们完成操作时自动关闭,这将特别触发 索引计划 的执行。 |
| 3 | 将选项传递给新会话。 |
| 4 | 构建新会话。 |
9.3. SearchScope
SearchScope 表示一组索引实体及其索引。
SearchScope 是线程安全的:它可以安全地从多个线程并发使用。但是,这并不意味着它返回的对象(SearchWorkspace 等)本身是线程安全的。
可以从 SearchMapping 以及 SearchSession 中检索 SearchScope。
SearchMapping 中检索 SearchScopeSearchMapping searchMapping = /* ... */ (1)
SearchScope<Book> bookScope = searchMapping.scope( Book.class ); (2)
SearchScope<Person> associateAndManagerScope = searchMapping.scope( Arrays.asList( Associate.class, Manager.class ) ); (3)
SearchScope<Person> personScope = searchMapping.scope( Person.class ); (4)
SearchScope<Person> personSubTypesScope = searchMapping.scope( Person.class,
Arrays.asList( "Manager", "Associate" ) ); (5)
SearchScope<Object> allScope = searchMapping.scope( Object.class ); (6)| 1 | 检索 SearchMapping. |
| 2 | 创建一个仅针对 Book 实体类型的 SearchScope。 |
| 3 | 创建一个同时针对 Associate 实体类型和 Manager 实体类型的 SearchScope。作用域的泛型类型参数可以是这些实体类型的任何公共超类型。 |
| 4 | 作用域始终会针对给定类的所有子类型,并且给定类本身不必是索引实体类型。这将创建一个 SearchScope,它针对 Person 接口的所有(索引实体)子类型;在我们的例子中,这将同时针对 Associate 实体类型和 Manager 实体类型。 |
| 5 | 对于高级用例,可以按名称针对实体类型。对于 Hibernate ORM,这将是 JPA 实体名称,对于 独立 POJO 映射器,这将是 实体定义 时分配给实体类型的名称。在这两种情况下,实体名称默认情况下都是 Java 类的简单名称。 |
| 6 | 传递 Object.class 将创建一个针对每个索引实体类型的作用域。 |
SearchSession 中检索 SearchScopeSearchSession searchSession = /* ... */ (1)
SearchScope<Book> bookScope = searchSession.scope( Book.class ); (2)
SearchScope<Person> associateAndManagerScope =
searchSession.scope( Arrays.asList( Associate.class, Manager.class ) ); (3)
SearchScope<Person> personScope = searchSession.scope( Person.class ); (4)
SearchScope<Person> personSubTypesScope = searchSession.scope( Person.class,
Arrays.asList( "Manager", "Associate" ) ); (5)
SearchScope<Object> allScope = searchSession.scope( Object.class ); (6)| 1 | 检索 SearchSession. |
| 2 | 创建一个仅针对 Book 实体类型的 SearchScope。 |
| 3 | 创建一个同时针对 Associate 实体类型和 Manager 实体类型的 SearchScope。作用域的泛型类型参数可以是这些实体类型的任何公共超类型。 |
| 4 | 作用域始终会针对给定类的所有子类型,并且给定类本身不必是索引实体类型。这将创建一个 SearchScope,它针对 Person 接口的所有(索引实体)子类型;在我们的例子中,这将同时针对 Associate 实体类型和 Manager 实体类型。 |
| 5 | 对于高级用例,可以按名称针对实体类型。对于 Hibernate ORM,这将是 JPA 实体名称,对于 独立 POJO 映射器,这将是 实体定义 时分配给实体类型的名称。在这两种情况下,实体名称默认情况下都是 Java 类的简单名称。 |
| 6 | 传递 Object.class 将创建一个针对每个索引实体类型的作用域。 |
10. 将实体映射到索引
10.1. 配置映射
10.1.1. 基于注释的映射
默认情况下,Hibernate Search 会自动处理实体类型的映射注释,以及这些实体类型中的嵌套类型,例如嵌入类型。
可以通过将 hibernate.search.mapping.process_annotations 设置为 Hibernate ORM 集成 的 false,或通过 AnnotationMappingConfigurationContext 设置为任何映射器来禁用基于注释的映射:请参阅 映射配置器 以访问该上下文,并参阅 AnnotationMappingConfigurationContext 的 javadoc 以了解可用选项。
|
如果禁用基于注释的映射,您可能需要以编程方式配置映射:请参阅 以编程方式映射。 |
Hibernate Search 还将尝试通过 类路径扫描 查找一些带注释的类型。
|
请参阅 实体定义、 实体/索引映射 和 使用 |
10.1.2. 类路径扫描
基础知识
Hibernate Search 会在启动时自动扫描实体类型的 JAR,查找使用“根映射注释”进行注释的类型,以便它可以自动将这些类型添加到应处理其注释的类型列表中。
根映射注释是充当映射入口点的映射注释,例如 @ProjectionConstructor 或 自定义根映射注释。如果没有此扫描,Hibernate Search 将在过晚时(当实际执行投影时)了解到投影构造函数,并且由于缺少元数据而失败。
扫描由 Jandex 支持,Jandex 是一个索引 JAR 内容的库。
扫描应用程序的依赖项
默认情况下,Hibernate Search 将仅扫描包含 Hibernate ORM 实体的 JAR。
如果希望 Hibernate Search 检测其他 JAR 中使用 根映射注释 进行注释的类型,则首先需要 访问 AnnotationMappingConfigurationContext。
从该上下文,您可以:
配置扫描
Hibernate Search 的扫描可能会在应用程序启动时通过 Jandex 触发 JAR 的索引。在一些更复杂的环境中,此索引可能无法访问要索引的类,或者可能会不必要地减慢启动速度。
在 Quarkus 或 Wildfly 中运行 Hibernate Search 有其优点,因为:
在其他情况下,根据应用程序需求,可以使用 Jandex Maven 插件在应用程序的构建阶段,以便在应用程序启动时索引已经构建并准备就绪。
或者,如果您的应用程序不使用 @ProjectionConstructor 或 自定义根映射注释,您可能希望完全或部分禁用此功能。
通常不建议这样做,因为它可能会导致引导失败或忽略映射注释,因为 Hibernate Search 将不再能够自动发现使用 根注释 进行注释的类型,这些类型位于没有嵌入式 Jandex 索引的 JAR 中。
为此,有两种选项可用:
-
将
hibernate.search.mapping.discover_annotated_types_from_root_mapping_annotations设置为false将禁用任何自动发现尝试,即使有可用的部分或完整的 Jandex 索引,这在根本没有使用根映射注释进行注释的类型,或者这些类型通过 映射配置器 或AnnotatedTypeSource显式列出时可能会有所帮助。 -
将
hibernate.search.mapping.build_missing_discovered_jandex_indexes设置为false将禁用启动时的 Jandex 索引构建,但仍将使用任何可用的预构建 Jandex 索引。这在需要部分自动发现时可能有所帮助,即可用的索引将用于发现,但没有可用索引的源将被忽略,除非它们的@ProjectionConstructor注释类型通过 映射配置器 或AnnotatedTypeSource显式列出。
10.1.3. 以编程方式映射
本文档中的大多数示例都使用基于注释的映射,这对于大多数应用程序来说通常已经足够了。但是,某些应用程序的需求超出了注释所能提供的范围:
-
单个实体类型必须针对不同的部署进行不同的映射(例如,针对不同的客户)。
-
许多实体类型必须以类似的方式进行映射,而无需代码重复。
为了满足这些需求,您可以使用以编程方式映射:通过将在启动时执行的代码定义映射。
以编程方式映射通过 ProgrammaticMappingConfigurationContext 配置:请参阅 映射配置器 以访问该上下文。
|
默认情况下,以编程方式映射将与基于注释的映射(如果有)合并。 要禁用基于注释的映射,请参阅 基于注释的映射。 |
|
以编程方式映射是声明性的,并公开了与基于注释的映射相同的特性。 为了实现更复杂的“命令式”映射,例如将两个实体属性组合成一个索引字段,请使用 自定义桥接。 |
|
或者,如果您只需要针对多个类型或属性重复相同的映射,则可以在这些类型或属性上应用自定义注释,并让 Hibernate Search 在遇到该注释时执行一些以编程方式映射的代码。此解决方案不需要特定于映射器的配置。 有关更多信息,请参阅 自定义映射注释。 |
10.1.4. 映射配置器
Hibernate ORM 集成
在 Hibernate ORM 集成中,可以将自定义 HibernateOrmSearchMappingConfigurer 插入 Hibernate Search,以便配置基于注释的映射(AnnotationMappingConfigurationContext)、以编程方式映射(ProgrammaticMappingConfigurationContext)等等。
插入自定义配置器需要两个步骤:
-
定义一个实现
org.hibernate.search.mapper.orm.mapping.HibernateOrmSearchMappingConfigurer接口的类。 -
通过将配置属性
hibernate.search.mapping.configurer设置为指向该实现的 bean 引用(例如class:com.mycompany.MyMappingConfigurer)来配置 Hibernate Search 以使用该实现。
| 您可以传递多个以逗号分隔的 bean 引用。请参阅 配置属性的类型。 |
Hibernate Search 将在启动时调用此实现的 configure 方法,配置器将能够利用 DSL 来配置基于注释的映射或定义以编程方式映射,例如:
public class MySearchMappingConfigurer implements HibernateOrmSearchMappingConfigurer {
@Override
public void configure(HibernateOrmMappingConfigurationContext context) {
ProgrammaticMappingConfigurationContext mapping = context.programmaticMapping(); (1)
TypeMappingStep bookMapping = mapping.type( Book.class ); (2)
bookMapping.indexed(); (3)
bookMapping.property( "title" ) (4)
.fullTextField().analyzer( "english" ); (5)
}
}独立 POJO 映射器
独立 POJO 映射器目前不提供 "映射配置器" (HSEARCH-4615)。但是,在构建 SearchMapping 时可以访问 AnnotationMappingConfigurationContext 和 ProgrammaticMappingConfigurationContext。
通过 Hibernate ORM 集成,可以将自定义的 StandalonePojoMappingConfigurer 插件到 Hibernate Search 中,以配置注解映射 (AnnotationMappingConfigurationContext)、编程映射 (ProgrammaticMappingConfigurationContext) 等。
插入自定义配置器需要两个步骤:
-
定义一个实现了
org.hibernate.search.mapper.pojo.standalone.mapping.StandalonePojoMappingConfigurer接口的类。 -
通过将配置属性
hibernate.search.mapping.configurer设置为指向该实现的 bean 引用(例如class:com.mycompany.MyMappingConfigurer)来配置 Hibernate Search 以使用该实现。
| 您可以传递多个以逗号分隔的 bean 引用。请参阅 配置属性的类型。 |
Hibernate Search 将在启动时调用此实现的 configure 方法,配置器将能够利用 DSL 来配置基于注释的映射或定义以编程方式映射,例如:
public class MySearchMappingConfigurer implements StandalonePojoMappingConfigurer {
@Override
public void configure(StandalonePojoMappingConfigurationContext context) {
context.annotationMapping() (1)
.discoverAnnotationsFromReferencedTypes( false )
.discoverAnnotatedTypesFromRootMappingAnnotations( false );
ProgrammaticMappingConfigurationContext mappingContext = context.programmaticMapping(); (2)
TypeMappingStep bookMapping = mappingContext.type( Book.class ); (3)
bookMapping.searchEntity(); (4)
bookMapping.indexed(); (5)
bookMapping.property( "id" ) (6)
.documentId(); (7)
bookMapping.property( "title" ) (8)
.fullTextField().analyzer( "english" ); (9)
}
}10.2. 实体定义
10.2.1. 基础知识
当 索引 Hibernate ORM 实体 时,实体类型由 Hibernate ORM 完全定义(通常通过 Jakarta 的 @Entity 注解),因此不需要显式定义:可以安全地跳过整个部分。
当使用 独立 POJO 映射器 时,需要 显式定义 实体类型。
10.2.2. 显式实体定义
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
|
对于 Hibernate ORM 实体, 请查看 HSEARCH-5076 跟踪允许在 Hibernate ORM 集成中使用 |
使用 独立 POJO 映射器 时,必须使用 @SearchEntity 注解显式标记 实体类型。
@SearchEntity 将一个类标记为实体@SearchEntity (1)
@Indexed (2)
public class Book {| 1 | 使用 @SearchEntity 注解该类型。 |
| 2 | @Indexed 是可选的:只有在打算 将该类型映射到索引 时才需要它。 |
|
并非所有类型都是实体类型,即使它们具有复合结构。 错误地将类型标记为实体类型可能会迫使您为域模型添加不必要的复杂性,例如 定义标识符 或 为 "关联" 这些类型定义反向端,而这些关联不会被使用。 请务必阅读 本节,以了解有关实体类型的更多信息以及它们为什么是必要的。 |
|
子类不继承 每个子类也必须使用 但是,对于也使用 |
默认情况下,使用 独立 POJO 映射器 时
-
实体名称 将等于类的简单名称 (
java.lang.Class#getSimpleName)。 -
实体不会被配置为加载,无论是为了 在搜索查询中返回实体作为命中,还是为了 批量索引。
请参阅以下部分以覆盖这些默认值。
10.2.3. 实体名称
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
与相应类名不同的 实体 名称,涉及多个地方,包括但不限于
-
作为
@Indexed的默认索引名称; -
使用 字符串来定位实体类型。
实体名称默认为类的简单名称 (java.lang.Class#getSimpleName)。
|
更改已 索引 实体的实体名称可能需要 完全重新索引,特别是在使用 Elasticsearch/OpenSearch 后端 时。 请参阅 本节 以了解详细信息。 |
通过 Hibernate ORM 集成,可以使用各种方法覆盖此名称,但通常是通过 Jakarta Persistence 的 @Entity 注解,即使用 @Entity(name = …)。
使用 独立 POJO 映射器 时,实体类型使用 @SearchEntity 定义,并且可以使用 @SearchEntity(name = …) 覆盖实体名称。
|
对于 Hibernate ORM 实体, 请查看 HSEARCH-5076 跟踪允许在 Hibernate ORM 集成中使用 |
@SearchEntity(name = …) 设置自定义实体名称@SearchEntity(name = "MyAuthorName")
@Indexed
public class Author {10.2.4. 批量加载策略
"批量加载策略" 使 Hibernate Search 能够加载给定类型的实体以进行 批量索引。
通过 Hibernate ORM 集成,会为每个 Hibernate ORM 实体自动配置批量加载策略,不需要任何其他配置。
使用 独立 POJO 映射器 时,实体类型使用 @SearchEntity 定义,为了利用批量索引,必须使用 @SearchEntity(loadingBinder = …) 显式应用批量加载策略。
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
|
对于 Hibernate ORM 实体, 请查看 HSEARCH-5076 跟踪允许在 Hibernate ORM 集成中使用 |
@SearchEntity(loadingBinder = @EntityLoadingBinderRef(type = MyLoadingBinder.class)) (1)
@Indexed
public class Book {| 1 | 为实体分配一个加载绑定器。 |
| 子类继承其父类的加载绑定器,除非它们使用自己的加载绑定器进行覆盖。 |
@Singleton
public class MyLoadingBinder implements EntityLoadingBinder { (1)
private final MyDatastore datastore;
@Inject (2)
public MyLoadingBinder(MyDatastore datastore) {
this.datastore = datastore;
}
@Override
public void bind(EntityLoadingBindingContext context) { (3)
context.massLoadingStrategy( (4)
Book.class, (5)
new MyMassLoadingStrategy<>( datastore, Book.class ) (6)
);
}
}| 1 | 绑定器必须实现 EntityLoadingBinder 接口。 |
| 2 | 将特定于实现的数据存储注入加载绑定器,例如这里使用 CDI(或 Spring 上的 @Autowired,或者 …)。 |
| 3 | 实现 bind 方法。 |
| 4 | 调用 context.massLoadingStrategy(…) 以定义要使用的加载策略。 |
| 5 | 传递加载实体的预期超类型。 |
| 6 | 传递加载策略。 |
使用 独立 POJO 映射器 在加载绑定器中进行注入需要 通过其他配置提供一个 BeanProvider。 |
以下是一个针对假想数据存储的 MassLoadingStrategy 实现示例。
MassLoadingStrategypublic class MyMassLoadingStrategy<E>
implements MassLoadingStrategy<E, String> {
private final MyDatastore datastore; (1)
private final Class<E> rootEntityType;
public MyMassLoadingStrategy(MyDatastore datastore, Class<E> rootEntityType) {
this.datastore = datastore;
this.rootEntityType = rootEntityType;
}
@Override
public MassIdentifierLoader createIdentifierLoader(
LoadingTypeGroup<E> includedTypes, (2)
MassIdentifierSink<String> sink, MassLoadingOptions options) {
int batchSize = options.batchSize(); (3)
Collection<Class<? extends E>> typeFilter =
includedTypes.includedTypesMap().values(); (4)
return new MassIdentifierLoader() {
private final MyDatastoreConnection connection =
datastore.connect(); (5)
private final MyDatastoreCursor<String> identifierCursor =
connection.scrollIdentifiers( typeFilter );
@Override
public void close() {
connection.close(); (5)
}
@Override
public long totalCount() { (6)
return connection.countEntities( typeFilter );
}
@Override
public void loadNext() throws InterruptedException {
List<String> batch = identifierCursor.next( batchSize );
if ( batch != null ) {
sink.accept( batch ); (7)
}
else {
sink.complete(); (8)
}
}
};
}
@Override
public MassEntityLoader<String> createEntityLoader(
LoadingTypeGroup<E> includedTypes, (9)
MassEntitySink<E> sink, MassLoadingOptions options) {
return new MassEntityLoader<String>() {
private final MyDatastoreConnection connection =
datastore.connect(); (10)
@Override
public void close() { (8)
connection.close();
}
@Override
public void load(List<String> identifiers)
throws InterruptedException {
sink.accept( (11)
connection.loadEntitiesById( rootEntityType, identifiers )
);
}
};
}
}| 1 | 该策略必须能够访问数据存储以打开连接,但它通常不应该有任何打开的连接。 |
| 2 | 实现一个标识符加载器以检索所有需要索引的实体的标识符。Hibernate Search 仅会对每个批量索引调用此方法一次。 |
| 3 | 检索在 MassIndexer 上配置的 批量大小。这定义了每次传递给接收器的 List 中最多必须返回多少个 ID。 |
| 4 | 检索要加载的实体类型列表:如果这些类型共享相似的批量加载策略,Hibernate Search 可能会从单个加载器请求加载多个类型(请参阅以下提示/警告)。 |
| 5 | 标识符加载器独占地拥有连接:它应该在创建时创建一个连接,并在关闭时关闭它。相关内容:标识符加载器始终在同一个线程中执行。 |
| 6 | 计算要索引的实体数量。这只是一个估计:它可能存在一定程度的偏差,但会导致 监视器(默认情况下,日志)中的报告不正确。 |
| 7 | 以连续的批次检索标识符,每次调用 loadNext() 时检索一个批次,并将它们传递给接收器。 |
| 8 | 当没有更多标识符要加载时,通过调用 complete() 让接收器知道。 |
| 9 | 实现一个实体加载器,以实际从上面检索到的标识符加载实体。Hibernate Search 将为单个批量索引调用此方法多次,以创建 多个加载器,这些加载器并行执行。 |
| 10 | 每个实体加载器独占地拥有一个连接:它应该在创建时创建一个连接,并在关闭时关闭它。相关内容:每个实体加载器始终在同一个线程中执行。 |
| 11 | 加载与传递给参数的标识符相对应的实体,并将它们传递给接收器。传递给接收器的实体不需要与传递给参数的标识符具有相同的顺序。 |
|
Hibernate Search 将通过将具有相同 当将类型分组在一起时,只会调用其中一个策略,并且它将获得一个包含所有应加载的类型的 "类型组"。 这种情况特别发生在从 "父" 实体类型配置的加载绑定器被子类型继承,并在子类型上设置相同的策略时。 |
|
小心继承树中非抽象(可实例化)的父类:当传递给 |
一旦所有要重新索引的类型都实现了其批量加载策略并被分配,就可以使用 批量索引器 来重新索引它们。
SearchMapping searchMapping = /* ... */ (1)
searchMapping.scope( Object.class ).massIndexer() (2)
.startAndWait(); (3)| 1 | 检索 SearchMapping. |
| 2 | 创建一个针对每个已索引实体类型的 MassIndexer。 |
| 3 | 启动批量索引过程,并在其结束后返回。 |
10.2.5. 选择加载策略
"选择加载策略" 使 Hibernate Search 能够加载给定类型的实体,以 在搜索查询中返回从外部来源加载的实体作为命中。
通过 Hibernate ORM 集成,会为每个 Hibernate ORM 实体自动配置选择加载策略,不需要任何其他配置。
使用 独立 POJO 映射器 时,实体类型使用 @SearchEntity 定义,为了在搜索查询中返回从外部来源加载的实体,必须使用 @SearchEntity(loadingBinder = …) 显式应用选择加载策略。
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
|
对于 Hibernate ORM 实体, 请查看 HSEARCH-5076 跟踪允许在 Hibernate ORM 集成中使用 |
@SearchEntity(loadingBinder = @EntityLoadingBinderRef(type = MyLoadingBinder.class)) (1)
@Indexed
public class Book {| 1 | 为实体分配一个加载绑定器。 |
| 子类继承其父类的加载绑定器,除非它们使用自己的加载绑定器进行覆盖。 |
@Singleton
public class MyLoadingBinder implements EntityLoadingBinder { (1)
@Override
public void bind(EntityLoadingBindingContext context) { (2)
context.selectionLoadingStrategy( (3)
Book.class, (4)
new MySelectionLoadingStrategy<>( Book.class ) (5)
);
}
}| 1 | 绑定器必须实现 EntityLoadingBinder 接口。 |
| 2 | 实现 bind 方法。 |
| 3 | 调用 context.selectionLoadingStrategy(…) 以定义要使用的加载策略。 |
| 4 | 传递加载实体的预期超类型。 |
| 5 | 传递加载策略。 |
以下是一个针对假想数据存储的 SelectionLoadingStrategy 实现示例。
SelectionLoadingStrategypublic class MySelectionLoadingStrategy<E>
implements SelectionLoadingStrategy<E> {
private final Class<E> rootEntityType;
public MySelectionLoadingStrategy(Class<E> rootEntityType) {
this.rootEntityType = rootEntityType;
}
@Override
public SelectionEntityLoader<E> createEntityLoader(
LoadingTypeGroup<E> includedTypes, (1)
SelectionLoadingOptions options) {
MyDatastoreConnection connection =
options.context( MyDatastoreConnection.class ); (2)
return new SelectionEntityLoader<E>() {
@Override
public List<E> load(List<?> identifiers, Deadline deadline) {
return connection.loadEntitiesByIdInSameOrder( (3)
rootEntityType, identifiers );
}
};
}
}| 1 | 实现一个实体加载器,以实际从 Lucene/Elasticsearch 返回的标识符加载实体。Hibernate Search 将为单个批量索引调用此方法多次, |
| 2 | 实体加载器不拥有连接,而是从传递给 SearchSession 的上下文中检索它(请参阅下一个示例)。 |
| 3 | 加载与传递给参数的标识符相对应的实体,并将其返回。返回的实体必须与传递给参数的标识符具有相同的顺序。 |
|
Hibernate Search 会通过将具有相同 当将类型分组在一起时,只会调用其中一个策略,并且它将获得一个包含所有应加载的类型的 "类型组"。 这种情况特别发生在从 "父" 实体类型配置的加载绑定器被子类型继承,并在子类型上设置相同的策略时。 |
一旦所有要搜索的类型都实现了并分配了它们的selection加载策略,就可以在查询时将其加载为命中项。
MyDatastore datastore = /* ... */ (1)
SearchMapping searchMapping = /* ... */ (2)
try ( MyDatastoreConnection connection = datastore.connect(); (3)
SearchSession searchSession = searchMapping.createSessionWithOptions() (4)
.loading( o -> o.context( MyDatastoreConnection.class, connection ) ) (5)
.build() ) { (6)
List<Book> hits = searchSession.search( Book.class ) (7)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (8)
}| 1 | 检索对特定于实现的数据存储的引用。 |
| 2 | 检索 SearchMapping. |
| 3 | 打开与数据存储的连接(这只是一个虚构的 API,用于此示例的目的)。请注意,我们使用 try-with-resources 块,以便在完成操作后自动关闭连接。 |
| 4 | 开始创建新的会话。请注意,我们使用 try-with-resources 块,以便在完成操作后自动关闭会话。 |
| 5 | 将连接传递给新会话。 |
| 6 | 构建新会话。 |
| 7 | 创建搜索查询:由于我们不使用select(),命中项将具有其默认表示形式:从数据存储加载的实体。 |
| 8 | 检索从数据存储加载的实体作为搜索命中项。 |
10.2.6. 编程映射
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
|
对于 Hibernate ORM 实体, 请查看 HSEARCH-5076 跟踪允许在 Hibernate ORM 集成中使用 |
您也可以通过编程映射将类型标记为实体类型。行为和选项与基于注释的映射相同。
.searchEntity()将类型标记为实体类型TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.searchEntity();
TypeMappingStep authorMapping = mapping.type( Author.class );
authorMapping.searchEntity().name( "MyAuthorName" );10.3. 实体/索引映射
10.3.1. 基础
为了索引实体,必须使用@Indexed对其进行注释。
@Indexed标记要索引的类@Entity
@Indexed
public class Book {|
子类继承 如果 |
默认情况下
-
索引名称将等于实体名称,在 Hibernate ORM 中,实体名称是使用
@Entity注释设置的,默认为简单类名。 -
使用Hibernate ORM 集成时,索引文档的标识符将从实体标识符生成。大多数用于实体标识符的常见类型都开箱即用地支持,但对于更奇特的类型,您可能需要特定的配置。
使用独立 POJO 映射器时,索引文档的标识符需要显式映射。
有关详细信息,请参阅映射文档标识符。
-
索引将不包含任何字段。必须将字段显式映射到属性。有关详细信息,请参阅使用
@GenericField、@FullTextField等将属性映射到索引字段。
10.3.2. 显式索引/后端
您可以通过设置@Indexed(index = …)来更改索引的名称。请注意,索引名称在给定应用程序中必须是唯一的。
@Indexed.index指定显式索引名称@Entity
@Indexed(index = "AuthorIndex")
public class Author {如果您定义了命名后端,您可以将实体映射到默认后端以外的其他后端。通过设置@Indexed(backend = "backend2"),您通知 Hibernate Search 您的实体的索引必须在名为“backend2”的后端中创建。如果您的模型具有明确定义的子部分并且具有非常不同的索引需求,这可能很有用。
@Indexed.backend指定显式后端@Entity
@Table(name = "\"user\"")
@Indexed(backend = "backend2")
public class User {|
索引在不同后端中的实体不能被同一个查询目标。例如,使用上面定义的映射,以下代码将抛出异常,因为 |
10.3.3. 条件索引和路由
将实体映射到索引并不总是像“此实体类型映射到此索引”那样简单。由于多种原因,主要是出于性能原因,您可能希望自定义何时以及在何处索引给定实体。
-
您可能不希望索引给定类型的所有实体:例如,当实体的
status属性设置为DRAFT或ARCHIVED时,阻止对其进行索引,因为用户不应该搜索这些实体。 -
您可能希望将实体路由到索引的特定分片:例如,根据实体的
language属性对其进行路由,因为每个用户都有特定的语言,并且只搜索其语言的实体。
这些行为可以通过使用@Indexed(routingBinder = …)将路由桥分配给索引的实体类型来在 Hibernate Search 中实现。
有关路由桥的更多信息,请参阅路由桥。
10.3.4. 编程映射
您也可以通过编程映射将实体标记为索引。行为和选项与基于注释的映射相同。
.indexed()标记要索引的类TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
TypeMappingStep authorMapping = mapping.type( Author.class );
authorMapping.indexed().index( "AuthorIndex" );
TypeMappingStep userMapping = mapping.type( User.class );
userMapping.indexed().backend( "backend2" );10.4. 映射文档标识符
10.4.1. 基础
索引文档,就像实体一样,需要分配一个标识符,以便 Hibernate Search 可以处理更新和删除。
当索引 Hibernate ORM 实体时,实体标识符默认用作文档标识符。只要实体标识符具有受支持的类型,标识符映射将开箱即用,无需显式映射。
当使用独立 POJO 映射器时,文档标识符需要显式映射。
10.4.2. 显式标识符映射
在以下情况下需要显式标识符映射。
-
Hibernate Search 不了解实体标识符(例如,当使用独立 POJO 映射器时)。
-
或者文档标识符不是实体标识符。
-
或者实体标识符的类型不受默认支持。这种情况包括复合标识符(Hibernate ORM 的
@EmbeddedId、@IdClass),尤其是复合标识符。
要选择一个要映射到文档标识符的属性,只需将@DocumentId注释应用到该属性即可。
@DocumentId显式将属性映射到文档标识符@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
@NaturalId
@DocumentId
private String isbn;
public Book() {
}
// Getters and setters
// ...
}当属性类型不受支持时,还需要实现自定义标识符桥,然后在@DocumentId注释中引用它。
@DocumentId将具有不受支持类型的属性映射到文档标识符@Entity
@Indexed
public class Book {
@Id
@Convert(converter = ISBNAttributeConverter.class)
@DocumentId(identifierBridge = @IdentifierBridgeRef(type = ISBNIdentifierBridge.class))
private ISBN isbn;
public Book() {
}
// Getters and setters
// ...
}10.4.3. 支持的标识符属性类型
以下是具有内置标识符桥的类型列表,即在将属性映射到文档标识符时开箱即用地支持的属性类型。
该表还解释了分配给文档标识符的值,即传递给底层后端的值。
| 属性类型 | 文档标识符的值 | 限制 |
|---|---|---|
|
|
- |
|
不变 |
- |
|
一个单字符 |
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
根据 |
- |
|
根据 |
- |
|
根据 |
- |
|
根据 |
- |
|
根据 |
- |
|
根据 |
- |
|
根据 |
- |
|
|
- |
|
|
- |
|
根据ISO 8601 格式的持续时间(例如 |
- |
|
根据ISO 8601 格式的持续时间进行格式化,仅使用秒和纳秒(例如 |
- |
|
根据ISO 8601 格式的年份(例如,对于公元 2017 年为 |
- |
|
根据ISO 8601 格式的年月(例如,对于 2017 年 11 月为 |
- |
|
根据ISO 8601 格式的月日(例如,对于 11 月 6 日为 |
- |
|
|
- |
|
一个表示相同日期/时间和时区的 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
纬度作为双精度数,经度作为双精度数,用逗号分隔(例如 |
- |
10.4.4. 编程映射
您也可以通过编程映射映射文档标识符。行为和选项与基于注释的映射相同。
.documentId()显式将属性映射到文档标识符TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "isbn" ).documentId();10.5. 使用@GenericField、@FullTextField 等将属性映射到索引字段
10.5.1. 基础
实体的属性可以直接映射到索引字段:您只需要添加一个注释,通过注释属性配置字段,Hibernate Search 将负责提取属性值并在必要时填充索引字段。
将属性映射到索引字段看起来像这样
@FullTextField(analyzer = "english", projectable = Projectable.YES) (1)
@KeywordField(name = "title_sort", normalizer = "english", sortable = Sortable.YES) (2)
private String title;
@GenericField(projectable = Projectable.YES, sortable = Sortable.YES) (3)
private Integer pageCount;| 1 | 将title属性映射到具有相同名称的全文本字段。可以设置一些选项来自定义字段的行为,在本例中是分析器(用于全文本索引)以及该字段是可投影的(其值可以从索引中检索)这一事实。 |
| 2 | 将title属性映射到另一个字段,以不同的方式配置:它没有被分析,而是简单地被规范化(即它没有被拆分为多个标记),并且它以可以用于排序的方式存储。将单个属性映射到多个字段在进行全文搜索时特别有用:在查询时,您可以根据需要使用不同的字段。您可以将一个属性映射到任意多个字段,但每个字段必须具有唯一的名称。 |
| 3 | 将另一个属性映射到其自己的字段。 |
在映射属性之前,您需要考虑两件事
@*Field注解-
在最简单的形式中,属性/字段映射是通过将
@GenericField注解应用于属性来实现的。此注解适用于所有支持的属性类型,但功能有限:它尤其不允许全文搜索。要更进一步,您需要依赖不同的、更具体的注解,这些注解提供特定的属性。可用的注解在 可用字段注解 中详细描述。 - 属性的类型
-
为了使
@*Field注解能够正常工作,映射属性的类型必须得到 Hibernate Search 的支持。有关所有开箱即用支持的类型的列表,请参阅 支持的属性类型,有关如何处理更复杂类型的说明,请参阅 映射自定义属性类型,无论是简单的容器(List<String>、Map<String, Integer>、……)还是自定义类型。
10.5.2. 可用字段注解
存在各种字段注解,每个注解都提供自己的一组属性。
本节列出了不同的注解及其用途。有关可用属性的更多详细信息,请参阅 字段注解属性。
@GenericField-
一个很好的默认选择,适用于所有具有内置支持的属性类型。
使用此注解映射的字段不提供任何高级功能,例如全文搜索:对通用字段的匹配是精确匹配。
-
@FullTextField -
一个文本字段,其值被视为多个词语。仅适用于
String字段。对全文字段的匹配可以 比精确匹配更微妙:匹配包含给定词语的字段,匹配不区分大小写的字段,匹配忽略变音符号的字段,……
全文字段还允许 突出显示。
全文字段应分配一个 分析器,由其名称引用。默认情况下,将使用名为
default的分析器。有关分析器和全文分析的更多详细信息,请参阅 分析。有关如何更改默认分析器的说明,请参阅您后端的文档中的专用部分:Lucene 或 Elasticsearch注意,您还可以定义 搜索分析器 以不同地分析搜索词语。
全文字段不能被排序或聚合。如果您需要根据属性的值进行排序或聚合,建议使用 @KeywordField,如果需要,可以使用规范化器(见下文)。请注意,可以向同一个属性添加多个字段,因此如果您需要全文搜索和排序,可以使用@FullTextField和@KeywordField:您只需要为这两个字段使用不同的 名称。 -
@KeywordField -
一个文本字段,其值被视为单个关键字。仅适用于
String字段。 -
@ScaledNumberField -
一个数值字段,用于需要比双精度数更高的精度的整数或浮点数,但始终具有大致相同的比例。仅适用于
java.math.BigDecimal或java.math.BigInteger字段。缩放数字被索引为整数,通常是长整型(64 位),具有固定的比例,该比例在所有文档中跨所有字段的所有值保持一致。由于缩放数字是以固定精度索引的,因此它们不能表示所有
BigDecimal或BigInteger值。太大的值无法索引,将触发运行时异常。具有尾随小数位的数字将四舍五入到最接近的整数。此注解允许设置 decimalScale 属性。
@NonStandardField-
一个注解,用于高级用例,其中使用 值绑定器,并且该绑定器预计会定义一个不支持任何标准选项的索引字段类型:
searchable、sortable、……此注解对于需要后端本机字段类型的用例非常有用:直接将映射定义为 JSON 用于 Elasticsearch,或 直接操作
IndexableField用于 Lucene。使用此注解映射的字段从注解中具有非常有限的配置选项(没有
searchable/sortable/等),但值绑定器将能够选择非标准字段类型,这通常会提供更大的灵活性。 -
@VectorField -
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。
通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。
建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。
向量字段的特定字段类型,用于 向量搜索。
向量字段接受类型为
float[]或byte[]的值,并且**要求**预先指定存储向量的 维数,并且索引向量的尺寸要与该维数匹配。除此之外,向量字段还允许可选地配置搜索过程中使用的 相似性函数,
efConstruction和m用于索引。不允许在同一个字段内索引多个向量,即向量字段不能是 多值。
10.5.3. 字段注解属性
存在各种字段映射注解,每个注解都提供自己的一组属性。
本节列出了不同的注解属性及其用途。有关可用注解的更多详细信息,请参阅 可用字段注解。
-
name -
索引字段的名称。默认情况下,它与属性名称相同。您可能希望在将单个属性映射到多个字段时更改它。
值:
String。名称不得包含句点字符(.)。默认为属性的名称。 -
sortable -
该字段是否可以 排序,即索引中是否添加了特定的数据结构,以便在查询时允许高效的排序。
值:
Sortable.YES、Sortable.NO、Sortable.DEFAULT。此选项不适用于
@FullTextField。有关解释和一些解决方案,请参阅 此处。 -
projectable -
该字段是否可以 投影,即该字段值是否存储在索引中,以便在查询时允许以后检索。
值:
Projectable.YES、Projectable.NO、Projectable.DEFAULT。对于 Lucene 和 Elasticsearch 后端,默认值不同:对于 Lucene,默认值为
Projectable.NO,而对于 Elasticsearch,默认值为Projectable.YES。对于 Elasticsearch,如果在
GeoPoint字段上将projectable或sortable属性解析为YES,那么即使其中一个显式设置为NO,此字段也会自动同时变为projectable和sortable。 -
aggregable -
该字段是否可以 聚合,即该字段值是否存储在索引中特定数据结构中,以便在查询时允许以后聚合。
值:
Aggregable.YES、Aggregable.NO、Aggregable.DEFAULT。此选项不适用于
@FullTextField。有关解释和一些解决方案,请参阅 此处。 searchable-
该字段是否可以被搜索。即该字段是否被索引,以便在查询时允许以后应用谓词。
值:
Searchable.YES、Searchable.NO、Searchable.DEFAULT。 -
indexNullAs -
用于替代任何时候属性值为 null 的值。
默认情况下禁用。
替换被定义为字符串。因此,它的值必须被解析。在 支持的属性类型 中查找列“indexNullAs”的解析方法,以了解解析时使用的格式。
-
extraction -
对于容器类型(
List、Optional、Map、……),如何从属性中提取要索引的元素。默认情况下,对于具有容器类型的属性,将索引最里面的元素。例如,对于类型为
List<String>的属性,将索引类型为String的元素。向量字段默认情况下禁用提取。
本节描述了此默认行为以及覆盖它的方法: 使用容器提取器映射容器类型。
-
analyzer -
在索引和查询时应用于字段值的分析器。仅适用于
@FullTextField。默认情况下,将使用名为
default的分析器。有关分析器和全文分析的更多详细信息,请参阅 分析。
-
searchAnalyzer -
一个可选的不同的分析器,覆盖使用
analyzer属性定义的分析器,仅在分析搜索词语时使用。如果未定义,则将使用分配给
analyzer的分析器。有关分析器和全文分析的更多详细信息,请参阅 分析。
-
normalizer -
在索引和查询时应用于字段值的规范化器。仅适用于
@KeywordField。有关规范化器和全文分析的更多详细信息,请参阅 分析。
norms-
是否存储字段的索引时评分信息。仅适用于
@KeywordField和@FullTextField。启用规范将提高评分质量。禁用规范将减少索引使用的磁盘空间。
值:
Norms.YES、Norms.NO、Norms.DEFAULT。 termVector-
词语向量存储策略。仅适用于
@FullTextField。此属性的不同值是
值 定义 TermVector.YES存储每个文档的词向量。这将生成两个同步的数组,一个包含文档词语,另一个包含词语的频率。
TermVector.NO不存储词向量。
TermVector.WITH_POSITIONS存储词向量和标记位置信息。这与
TermVector.YES相同,它还包含每个词语在文档中出现的顺序位置。TermVector.WITH_OFFSETS存储词向量和标记偏移量信息。这与
TermVector.YES相同,它还包含词语的起始和结束偏移量位置信息。TermVector.WITH_POSITION_OFFSETS存储词向量、标记位置和偏移量信息。这是
YES、WITH_OFFSETS和WITH_POSITIONS的组合。TermVector.WITH_POSITIONS_PAYLOADS存储词向量、标记位置和标记有效载荷。这与
TermVector.WITH_POSITIONS相同,它还包含每个词语在文档中出现的有效载荷。TermVector.WITH_POSITIONS_OFFSETS_PAYLOADS存储词向量、标记位置、偏移量信息和标记有效载荷。这与
TermVector.WITH_POSITION_OFFSETS相同,它还包含每个词语在文档中出现的有效载荷。请注意,全文字段请求的突出显示类型可能会影响最终解析的词向量存储策略。由于快速向量突出显示器类型对词向量存储策略有特定要求,如果通过使用
Highlightable.ANY显式或隐式请求它,它将把策略设置为TermVector.WITH_POSITIONS_OFFSETS,除非已指定策略。如果使用与快速向量突出显示器不兼容的非默认策略,则会抛出异常。 -
decimalScale -
在将大数(
BigInteger或BigDecimal)索引为固定精度整数之前,应如何调整其规模。仅在@ScaledNumberField上可用。要索引小数点后有有效数字的数字,请将
decimalScale设置为需要索引的数字位数。小数点将向右移动这些位数,然后进行索引,从而保留小数部分的这些位数。要索引无法容纳在长整型中的非常大的数字,请将小数点设置为负值。小数点将向左移动这些位数,然后进行索引,从而丢弃小数部分的所有位数。只有对于
BigDecimal才允许具有严格正值的decimalScale,因为BigInteger值没有小数位数。请注意,小数点的移动是完全透明的,不会影响您使用搜索 DSL 的方式:您需要提供“正常”的
BigDecimal或BigInteger值,Hibernate Search 将透明地应用decimalScale和舍入操作。由于舍入的影响,搜索谓词和排序的精度仅受
decimalScale允许的精度限制。请注意,舍入不会影响投影,投影将返回原始值,没有任何精度损失。
一个典型的用例是货币金额,小数位数为 2,因为小数点后通常只需要两位数。 通过Hibernate ORM 集成,默认的 decimalScale将自动从相关 SQL@Column的底层scale值中获取,使用 Hibernate ORM 元数据。可以使用decimalScale属性显式覆盖该值。 -
highlightable -
该字段是否可以突出显示,如果是,哪些突出显示器类型可以应用于该字段。即该字段值是否以特定格式索引/存储,以便在查询时允许稍后突出显示。仅在
@FullTextField上可用。虽然在大多数情况下选择一种突出显示器类型就足够了,但此属性可以接受多个不矛盾的值。请参考突出显示器类型部分以查看要选择哪个突出显示器。可用值为
值 定义 Highlightable.NOHighlightable.ANY允许对该字段进行突出显示时应用任何突出显示器类型。
Highlightable.PLAIN允许对该字段进行突出显示时应用纯文本突出显示器类型。
Highlightable.UNIFIEDHighlightable.FAST_VECTOR允许对该字段进行突出显示时应用快速向量突出显示器类型。此突出显示器类型需要将词向量存储策略设置为
WITH_POSITIONS_OFFSETS或WITH_POSITIONS_OFFSETS_PAYLOADS。Highlightable.DEFAULT使用特定于后端的默认值,该默认值取决于字段的整体配置。Elasticsearch的默认值为
[Highlightable.PLAIN, Highlightable.UNIFIED]。 Lucene的默认值取决于为该字段配置的可投影值。如果该字段是可投影的,则支持[PLAIN, UNIFIED]突出显示器。否则,不支持突出显示(Highlightable.NO)。此外,如果词向量存储策略设置为WITH_POSITIONS_OFFSETS或WITH_POSITIONS_OFFSETS_PAYLOADS,则这两个后端都将支持FAST_VECTOR突出显示器,如果它们已经支持另外两个([PLAIN, UNIFIED])。 -
dimension -
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。
通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。
建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。
存储向量的尺寸。这是必需字段。此尺寸应与用于将数据转换为向量表示的模型生成的向量尺寸匹配。它应该是一个正整数。最大允许值是特定于后端的。对于Lucene 后端,尺寸必须在
[1, 4096]范围内。至于Elasticsearch 后端,范围取决于分发版本。请参阅Elasticsearch/OpenSearch的特定文档,以了解这些分发版本的向量类型。仅在
@VectorField上可用。 -
vectorSimilarity -
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。
通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。
建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。
定义在向量搜索期间如何计算向量相似度。
仅在
@VectorField上可用。值 定义 VectorSimilarity.L2L2(欧几里得)范数,对于大多数情况来说都是合理的默认值。向量
x和y之间的距离计算为\(d(x,y) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2 } \),得分函数为\(s = \frac{1}{1+d^2}\)VectorSimilarity.DOT_PRODUCT内积(特别是点积)。向量
x和y之间的距离计算为\(d(x,y) = \sum_{i=1}^{n} x_i \cdot y_i \),得分函数为\(s = \frac{1}{1+d}\)为了有效地使用此相似度,索引向量和搜索向量必须被归一化;否则,搜索可能会产生糟糕的结果。浮点向量必须归一化为单位长度,而字节向量应该只具有相同的范数。
VectorSimilarity.COSINE余弦相似度。向量
x和y之间的距离计算为\(d(x,y) = \frac{1 - \sum_{i=1} ^{n} x_i \cdot y_i }{ \sqrt{ \sum_{i=1} ^{n} x_i^2 } \sqrt{ \sum_{i=1} ^{n} y_i^2 }} \),得分函数为\(s = \frac{1}{1+d}\)VectorSimilarity.MAX_INNER_PRODUCT类似于点积相似度,但不需要向量归一化。向量
x和y之间的距离计算为\(d(x,y) = \sum_{i=1}^{n} x_i \cdot y_i \),得分函数为\(s = \begin{cases} \frac{1}{1-d} & \text{if d < 0}\\ d+1 & \text{otherwise} \end{cases} \)VectorSimilarity.DEFAULT使用特定于后端的默认值。对于Lucene 后端,使用
L2相似度。表 4. 向量相似度如何与特定于后端的价值观相匹配 Hibernate Search 值 Lucene 后端 Elasticsearch 后端 Elasticsearch 后端(OpenSearch 发行版) DEFAULTEUCLIDEANElasticsearch 默认值
OpenSearch 默认值。
L2EUCLIDEANl2_norml2DOT_PRODUCTDOT_PRODUCTdot_product目前不支持OpenSearch,并将导致异常。
COSINECOSINEcosinecosinesimilMAX_INNER_PRODUCTMAXIMUM_INNER_PRODUCTmax_inner_product目前不支持OpenSearch,并将导致异常。
-
efConstruction -
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。
通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。
建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。
efConstruction是 k-NN 图创建期间使用的动态列表的尺寸。它影响向量的存储方式。更高的值会导致更精确的图,但索引速度会更慢。默认值是特定于后端的。
仅在
@VectorField上可用。 -
m -
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。
通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。
建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。
每个节点在HNSW(分层可导航小世界图)图中连接到的邻居数量。修改此值会影响内存消耗。建议将此值保持在 2 到 100 之间。
默认值是特定于后端的。
仅在
@VectorField上可用。
10.5.4. 支持的属性类型
以下是列出所有具有内置值桥接的类型的表格,即在将属性映射到索引字段时开箱即用的支持的属性类型。
该表还解释了分配给索引字段的值,即传递给底层后端以进行索引的值。
|
有关底层后端使用的索引和存储的信息,请参阅Lucene 字段类型或Elasticsearch 字段类型,具体取决于您的后端。 |
| 属性类型 | 索引字段的值(如果不同) | 限制 | 查询字符串谓词中“indexNullAs”/terms 的解析方法 |
|---|---|---|---|
|
|
- |
|
|
- |
- |
- |
|
一个单字符 |
- |
接受任何单字符 |
|
- |
- |
|
|
- |
- |
|
|
- |
- |
|
|
- |
- |
|
|
- |
- |
|
|
- |
- |
|
|
- |
- |
接受字符串 |
|
- |
- |
|
|
- |
- |
|
|
|
- |
|
|
|
- |
|
|
- |
|
|
|
- |
|
|
|
- |
|
|
|
- |
|
|
|
- |
|
|
|
- |
|
|
|
- |
|
|
|
|
- |
|
|
|
- |
|
|
格式化的 |
- |
|
|
|
|
|
|
- |
|
|
|
- |
|
|
|
- |
- |
|
|
|
- |
|
|
表示相同日期/时间和时区的 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
- |
纬度为双精度,经度为双精度,用逗号隔开。例如: |
|
日期/时间字段的范围和分辨率
除了少数例外,大多数日期和时间值按原样传递给后端;例如, 但是,在内部,Lucene 和 Elasticsearch 后端使用不同的日期/时间类型表示形式。因此,存储在索引中的日期和时间字段的范围和分辨率可能小于相应的 Java 类型。 每个后端的文档提供了更多信息:请参阅Lucene 的信息和Elasticsearch 的信息。 |
10.5.5. 对传统java.util日期/时间 API 的支持
不建议使用过时的日期/时间类型,例如java.util.Calendar、java.util.Date、java.sql.Timestamp、java.sql.Date、java.sql.Time,因为它们存在许多奇特之处和缺陷。Java 8 中引入的java.time包通常更受欢迎。
话虽如此,集成约束可能会迫使您依赖过时的日期/时间 API,这就是 Hibernate Search 仍然尽力支持它们的原因。
由于 Hibernate Search 使用java.time API 在内部表示日期/时间,因此在对过时的日期/时间类型进行索引之前需要对其进行转换。Hibernate Search 将操作简化:java.util.Date、java.util.Calendar 等将使用它们的时间值(自纪元以来的毫秒数)进行转换,该值将被假定为在 Java 8 API 中表示相同的日期/时间。在java.util.Calendar的情况下,时区信息将被保留以供投影使用。
对于 1900 年之后的所有日期,这将按预期工作。
在 1900 年之前,通过 Hibernate Search API 进行索引和搜索也将按预期工作,但**如果您需要以原生方式访问索引**,例如通过对 Elasticsearch 服务器的直接 HTTP 调用,您会注意到索引的值略有“偏差”。这是由于java.time 和过时的日期/时间 API 的实现方式不同,导致对时间值(自纪元以来的毫秒数)的解释略有差异。
这种“偏差”是一致的:在构建谓词时也会发生,并且在投影时会发生在相反的方向。因此,对于仅依赖 Hibernate Search API 的应用程序来说,这些差异将不可见。但是,在以原生方式访问索引时,它们将是可见的。
对于绝大多数用例,这将不是问题。如果这种行为对于您的应用程序不可接受,您应该考虑实现自定义值桥,并指示 Hibernate Search 为java.util.Date、java.util.Calendar 等默认使用它们:请参见使用桥解析器分配默认桥.
|
从技术上讲,转换很困难,因为 特别是
这是两个主要问题,但可能还存在其他问题。 |
10.5.6. 映射自定义属性类型
即使是不支持开箱即用的类型也可以进行映射。有各种解决方案,一些很简单,另一些更强大,但它们都归结为从不支持的类型中提取数据并将其转换为后端支持的类型。
有两种情况需要区分
-
如果不支持的类型仅仅是一个容器(
List<String>)或多个嵌套容器(Map<Integer, List<String>>),其元素具有支持的类型,那么您需要的是一个容器提取器。有关更多信息,请参见使用容器提取器映射容器类型. -
否则,您将不得不依靠一个称为桥的自定义组件来从您的类型中提取数据。有关自定义桥的更多信息,请参见绑定和桥.
10.5.7. 编程映射
您也可以通过编程映射将实体的属性直接映射到索引字段。行为和选项与基于注释的映射相同。
.genericField()、.fullTextField() 等将属性直接映射到字段TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "title" )
.fullTextField()
.analyzer( "english" ).projectable( Projectable.YES )
.keywordField( "title_sort" )
.normalizer( "english" ).sortable( Sortable.YES );
bookMapping.property( "pageCount" )
.genericField().projectable( Projectable.YES ).sortable( Sortable.YES );10.6. 使用@IndexedEmbedded映射关联元素
10.6.1. 基础
仅使用@Indexed 与@*Field 注释结合使用可以索引实体及其直接属性,这很好,但很简单。一个现实世界的模型将包含多个对象类型,它们相互引用,例如下面示例中的authors 关联。
此映射将在Book 索引中声明以下字段
-
title -
… 以及其他任何东西。
@Entity
@Indexed (1)
public class Book {
@Id
private Integer id;
@FullTextField(analyzer = "english") (2)
private String title;
@ManyToMany
private List<Author> authors = new ArrayList<>(); (3)
public Book() {
}
// Getters and setters
// ...
}@Entity
public class Author {
@Id
private Integer id;
private String name;
@ManyToMany(mappedBy = "authors")
private List<Book> books = new ArrayList<>();
public Author() {
}
// Getters and setters
// ...
}| 1 | Book 实体被索引。 |
| 2 | 书籍的title 被映射到一个索引字段。 |
| 3 | 但是如何将Author 名字索引到Book 索引中呢? |
在搜索书籍时,用户可能需要按作者姓名进行搜索。在高性能索引的世界中,跨索引连接代价高昂,通常不可取。解决此类用例的最佳方法通常是复制数据:在索引Book 时,只需将所有作者的姓名复制到Book 文档中。
这就是@IndexedEmbedded 的作用:它指示 Hibernate Search 将关联对象的字段嵌入到主对象中。在下面的示例中,它将指示 Hibernate Search 将Author 中定义的name 字段嵌入到Book 中,从而创建字段authors.name。
|
|
@IndexedEmbedded 索引关联元素此映射将在Book 索引中声明以下字段
-
title -
authors.name
@Entity
@Indexed
public class Book {
@Id
private Integer id;
@FullTextField(analyzer = "english")
private String title;
@ManyToMany
@IndexedEmbedded (1)
private List<Author> authors = new ArrayList<>();
public Book() {
}
// Getters and setters
// ...
}@Entity
public class Author {
@Id
private Integer id;
@FullTextField(analyzer = "name") (2)
private String name;
@ManyToMany(mappedBy = "authors")
private List<Book> books = new ArrayList<>();
public Author() {
}
// Getters and setters
// ...
}| 1 | 在authors 属性中添加一个@IndexedEmbedded。 |
| 2 | 将Author.name 映射到一个索引字段,即使Author 没有直接映射到一个索引(没有@Indexed)。 |
|
文档标识符 不是索引字段。因此,它们将被 要使用 |
|
当 有关此限制的原因以及解决方法,请参见嵌入元素发生更改时的重新索引. |
索引嵌入可以在多个级别上嵌套;例如,您可以决定索引嵌入作者的出生地点,以便能够专门搜索由俄罗斯作者撰写的书籍
@IndexedEmbedded此映射将在Book 索引中声明以下字段
-
title -
authors.name -
authors.placeOfBirth.country
@Entity
@Indexed
public class Book {
@Id
private Integer id;
@FullTextField(analyzer = "english")
private String title;
@ManyToMany
@IndexedEmbedded (1)
private List<Author> authors = new ArrayList<>();
public Book() {
}
// Getters and setters
// ...
}@Entity
public class Author {
@Id
private Integer id;
@FullTextField(analyzer = "name") (2)
private String name;
@Embedded
@IndexedEmbedded (3)
private Address placeOfBirth;
@ManyToMany(mappedBy = "authors")
private List<Book> books = new ArrayList<>();
public Author() {
}
// Getters and setters
// ...
}@Embeddable
public class Address {
@FullTextField(analyzer = "name") (4)
private String country;
private String city;
private String street;
public Address() {
}
// Getters and setters
// ...
}| 1 | 在authors 属性中添加一个@IndexedEmbedded。 |
| 2 | 将Author.name 映射到一个索引字段,即使Author 没有直接映射到一个索引(没有@Indexed)。 |
| 3 | 在placeOfBirth 属性中添加一个@IndexedEmbedded。 |
| 4 | 将Address.country 映射到一个索引字段,即使Address 没有直接映射到一个索引(没有@Indexed)。 |
|
默认情况下, 要解决此问题,请参见过滤嵌入字段并打破 |
10.6.2. @IndexedEmbedded 和null 值
当@IndexedEmbedded 目标的属性包含null 元素时,这些元素将简单地不被索引。
与使用@GenericField、@FullTextField 等将属性映射到索引字段不同,没有indexNullAs 功能来为null 对象索引特定值,但您可以利用搜索查询中的exists 谓词来查找给定@IndexedEmbedded 有或没有值的文档:只需将对象字段的名称传递给exists 谓词,例如上面的示例中的authors。
10.6.3. 容器类型上的@IndexedEmbedded
当@IndexedEmbedded 目标的属性具有容器类型(List、Optional、Map 等)时,将嵌入最里面的元素。例如,对于类型为List<MyEntity> 的属性,将嵌入类型为MyEntity 的元素。
本节描述了此默认行为以及覆盖它的方法: 使用容器提取器映射容器类型。
10.6.4. 使用name 设置对象字段名称
默认情况下,@IndexedEmbedded 将使用与注释属性相同的名称创建一个对象字段,并将嵌入字段添加到该对象字段中。因此,如果@IndexedEmbedded 应用于Book 实体中名为authors 的属性,则在索引Book 时,作者的索引字段name 将被复制到索引字段authors.name 中。
可以通过设置name 属性来更改对象字段的名称;例如,在上面的示例中使用@IndexedEmbedded(name = "allAuthors") 将导致作者的姓名被复制到索引字段allAuthors.name 中,而不是authors.name 中。
|
名称不能包含点字符( |
10.6.5. 使用prefix 设置字段名称前缀
|
|
默认情况下,@IndexedEmbedded 将在嵌入字段的名称前加上它所应用的属性的名称,后跟一个点。因此,如果@IndexedEmbedded 应用于Book 实体中名为authors 的属性,则在索引Book 时,作者的name 字段将被复制到authors.name 字段中。
可以通过设置prefix 属性来更改此前缀,例如@IndexedEmbedded(prefix = "author.")(不要忘记尾部的点!)。
|
前缀通常应该是一系列不带点的字符,以一个点结尾,例如 将前缀更改为不包含任何点的字符串( 特别是,不以点结尾的前缀会导致自定义桥所公开的一些 API 中的行为不正确:接受字段名称的 |
10.6.6. 使用targetType 转换@IndexedEmbedded 的目标
默认情况下,索引嵌入值的类型是使用反射自动检测的,如果相关,则考虑容器提取;例如,@IndexedEmbedded List<MyEntity> 将被检测为具有类型为MyEntity 的值。要嵌入的字段将根据值类型及其超类型的映射推断出来;在本例中,将考虑MyEntity 及其超类上存在的@GenericField 注释,但其子类中定义的注释将被忽略。
如果由于某种原因,模式没有为属性公开正确的类型(例如,原始List,或List<MyEntityInterface> 而不是List<MyEntityImpl>),则可以通过在@IndexedEmbedded 中设置targetType 属性来定义预期的值类型。在引导时,Hibernate Search 然后将根据给定的目标类型解析要嵌入的字段,并在运行时将值转换为给定的目标类型。
|
如果将索引嵌入的值强制转换为指定类型失败,则会进行传播并导致索引失败。 |
10.6.7. 嵌入元素更改时的重新索引
当“嵌入”实体发生变化时,Hibernate Search 将处理“嵌入”实体的重新索引。
只要应用 @IndexedEmbedded 的关联是双向的(使用 Hibernate ORM 的 mappedBy),这在大多数情况下都能透明地工作。
当 Hibernate Search 无法处理关联时,它将在引导时抛出异常。如果发生这种情况,请参考 基础 了解详情。
10.6.8. 嵌入实体标识符
将属性映射为索引嵌入类型中的 标识符 不会自动导致它在使用 @IndexedEmbedded 时被嵌入,因为文档标识符不是字段。
要嵌入此类属性的数据,可以使用 @IndexedEmbedded(includeEmbeddedObjectId = true),它将使 Hibernate Search 自动在结果嵌入对象中为索引嵌入类型的 标识符属性 插入一个字段。
索引字段将被定义为,就像以下 字段注释 被放在嵌入类型的标识符属性上一样:@GenericField(searchable = Searchable.YES, projectable = Projectable.YES)。索引字段的名称将是标识符属性的名称。它的桥接将是嵌入类型 @DocumentId 注释(如果有)引用的标识符桥接,或者默认情况下是标识符属性类型的默认值桥接。
|
如果需要更高级的映射(自定义名称、自定义桥接、可排序等),请勿使用 相反,通过使用 |
以下是如何使用 includeEmbeddedObjectId 的示例
includeEmbeddedObjectId 包含索引嵌入的 ID此映射将在 Employee 索引中声明以下字段
-
name -
department.name:由@IndexedEmbedded隐式包含。 -
department.id:由 `includeEmbeddedObjectId = true` 显式插入。
@Entity
public class Department {
@Id
private Integer id; (1)
@FullTextField
private String name;
@OneToMany(mappedBy = "department")
private List<Employee> employees = new ArrayList<>();
// Getters and setters
// ...
}| 1 | Department 标识符未映射到索引字段(不是 @*Field 注释)。 |
@Entity
@Indexed
public class Employee {
@Id
private Integer id;
@FullTextField
private String name;
@ManyToOne
@IndexedEmbedded(includeEmbeddedObjectId = true) (1)
private Department department;
// Getters and setters
// ...
}| 1 | @IndexedEmbedded 将为 Department 标识符在 Employee 索引中插入一个 department.id 字段,即使在 Department 中标识符属性未映射到索引字段。 |
10.6.9. 过滤嵌入字段和打破 @IndexedEmbedded 循环
默认情况下,@IndexedEmbedded 将“嵌入”所有内容:在索引嵌入元素中遇到的每个字段,以及在索引嵌入元素中遇到的每个 @IndexedEmbedded,递归地。
这对于更简单的用例来说效果很好,但可能会导致更复杂模型出现问题
-
如果索引嵌入元素声明了许多索引字段(Hibernate Search 字段),但其中只有部分对“索引嵌入”类型真正有用,那么额外的字段将不必要地降低索引性能。
-
如果存在
@IndexedEmbedded的循环(例如,A索引嵌入类型为B的b,它索引嵌入类型为A的a),那么索引嵌入类型最终将拥有无限数量的字段(a.b.someField、a.b.a.b.someField、a.b.a.b.a.b.someField等),Hibernate Search 将检测到并用异常拒绝。
为了解决这些问题,可以过滤要嵌入的字段,只包含真正有用的字段。@IndexedEmbedded 上可用的过滤属性有
includePaths-
应该嵌入的索引嵌入元素中索引字段的路径。
这优先于
includeDepth(见下文)。不能与同一个
@IndexedEmbedded中的excludePaths结合使用。 excludePaths-
索引嵌入元素中不应嵌入的索引字段的路径。
这优先于
includeDepth(见下文)。不能与同一个
@IndexedEmbedded中的includePaths结合使用。 includeDepth-
默认情况下将包含所有字段的索引嵌入级别数。
includeDepth是将遍历的@IndexedEmbedded的数量,以及其索引嵌入元素的所有字段都将被包含在内,即使这些字段未通过includePaths显式包含,除非这些字段通过excludePaths显式排除-
includeDepth=0表示此索引嵌入元素的字段不包含,嵌套索引嵌入元素的任何字段也不包含,除非这些字段通过includePaths显式包含。 -
includeDepth=1表示此索引嵌入元素的字段包含,除非这些字段通过excludePaths显式排除,但不包含嵌套索引嵌入元素(此@IndexedEmbedded中的@IndexedEmbedded)的字段,除非这些字段通过includePaths显式包含。 -
includeDepth=2表示此索引嵌入元素的字段和直接嵌套索引嵌入(此@IndexedEmbedded中的@IndexedEmbedded)元素的字段包含,除非这些字段通过excludePaths显式排除,但不包含超出此范围的嵌套索引嵌入元素(此@IndexedEmbedded中的@IndexedEmbedded中的@IndexedEmbedded)的字段,除非这些字段通过includePaths显式包含。 -
以此类推。
默认值取决于
includePaths属性的值-
如果
includePaths为空,则默认值为Integer.MAX_VALUE(包含每个级别上的所有字段) -
如果
includePaths不为空,则默认值为0(仅包含显式包含的字段)。
-
|
动态字段和过滤
动态字段 不受过滤规则的直接影响:动态字段只有在其父级被包含时才会被包含。 这意味着,特别是 |
|
在不同嵌套级别混合使用
includePaths 和 excludePaths通常,可以在不同嵌套级别的 |
以下是三个示例:一个利用 includePaths,一个利用 excludePaths,一个利用 includePaths 和 includeDepth。
includePaths 过滤索引嵌入字段此映射将在 Human 索引中声明以下字段
-
name -
nickname -
parents.name:显式包含,因为parents上的includePaths包含name。 -
parents.nickname:显式包含,因为parents上的includePaths包含nickname。 -
parents.parents.name:显式包含,因为parents上的includePaths包含parents.name。
以下字段将被特别排除
-
parents.parents.nickname:不隐式包含,因为includeDepth未设置,默认值为0,并且不显式包含,因为parents上的includePaths不包含parents.nickname。 -
parents.parents.parents.name:不隐式包含,因为includeDepth未设置,默认值为0,并且不显式包含,因为parents上的includePaths不包含parents.parents.name。
@Entity
@Indexed
public class Human {
@Id
private Integer id;
@FullTextField(analyzer = "name")
private String name;
@FullTextField(analyzer = "name")
private String nickname;
@ManyToMany
@IndexedEmbedded(includePaths = { "name", "nickname", "parents.name" })
private List<Human> parents = new ArrayList<>();
@ManyToMany(mappedBy = "parents")
private List<Human> children = new ArrayList<>();
public Human() {
}
// Getters and setters
// ...
}excludePaths 过滤索引嵌入字段此映射将产生与 使用 includePaths 过滤索引嵌入字段 示例中相同的模式,但通过使用 excludePaths 来实现。Human 索引中将声明以下字段
-
name -
nickname -
parents.name:隐式包含,因为parents上的includeDepth默认值为Integer.MAX_VALUE。 -
parents.nickname:隐式包含,因为parents上的includeDepth默认值为Integer.MAX_VALUE。 -
parents.parents.name:隐式包含,因为parents上的includeDepth默认值为Integer.MAX_VALUE。
以下字段将被特别排除
-
parents.parents.nickname:不包含,因为excludePaths显式排除parents.nickname。 -
parents.parents.parents/parents.parents.parents.<any-field>:不包含,因为excludePaths显式排除parents.parents,从而阻止任何进一步的遍历。
@Entity
@Indexed
public class Human {
@Id
private Integer id;
@FullTextField(analyzer = "name")
private String name;
@FullTextField(analyzer = "name")
private String nickname;
@ManyToMany
@IndexedEmbedded(excludePaths = { "parents.nickname", "parents.parents" })
private List<Human> parents = new ArrayList<>();
@ManyToMany(mappedBy = "parents")
private List<Human> children = new ArrayList<>();
public Human() {
}
// Getters and setters
// ...
}includePaths 和 includeDepth 过滤索引嵌入字段此映射将在 Human 索引中声明以下字段
-
name -
surname -
parents.name:隐式包含在深度0,因为includeDepth > 0(因此parents.*隐式包含)。 -
parents.nickname:隐式包含在深度0,因为includeDepth > 0(因此parents.*隐式包含)。 -
parents.parents.name:隐式包含在深度1,因为includeDepth > 1(因此parents.parents.*隐式包含)。 -
parents.parents.nickname:隐式包含在深度1,因为includeDepth > 1(因此parents.parents.*隐式包含)。 -
parents.parents.parents.name:不隐式包含在深度2,因为includeDepth = 2(因此parents.parents.parents隐式包含,但子字段只能显式包含),但显式包含,因为parents上的includePaths包含parents.parents.name。
以下字段将被特别排除
-
parents.parents.parents.nickname:不隐式包含在深度2,因为includeDepth = 2(因此parents.parents.parents隐式包含,但子字段必须显式包含),并且不显式包含,因为parents上的includePaths不包含parents.parents.nickname。 -
parents.parents.parents.parents.name:不隐式包含在深度3,因为includeDepth = 2(因此parents.parents.parents隐式包含,但parents.parents.parents.parents和子字段只能显式包含),并且不显式包含,因为parents上的includePaths不包含parents.parents.parents.name。
@Entity
@Indexed
public class Human {
@Id
private Integer id;
@FullTextField(analyzer = "name")
private String name;
@FullTextField(analyzer = "name")
private String nickname;
@ManyToMany
@IndexedEmbedded(includeDepth = 2, includePaths = { "parents.parents.name" })
private List<Human> parents = new ArrayList<>();
@ManyToMany(mappedBy = "parents")
private List<Human> children = new ArrayList<>();
public Human() {
}
// Getters and setters
// ...
}10.6.10. 使用 structure 将嵌入元素结构化为嵌套文档
索引嵌入字段可以通过 @IndexedEmbedded 注释的 structure 属性来配置,以两种方式进行结构化。为了说明结构选项,假设类 Book 使用 @Indexed 进行了注释,其 authors 属性使用 @IndexedEmbedded 进行了注释
-
Book 实例
-
title = Leviathan Wakes
-
authors =
-
Author 实例
-
firstName = Daniel
-
lastName = Abraham
-
-
Author 实例
-
firstName = Ty
-
lastName = Frank
-
-
-
DEFAULT 或 FLATTENED 结构
默认情况下,或当使用 @IndexedEmbedded(structure = FLATTENED)(如下所示)时,索引嵌入字段将被“扁平化”,这意味着不会保留树结构。
@IndexedEmbedded@Entity
@Indexed
public class Book {
@Id
private Integer id;
@FullTextField(analyzer = "english")
private String title;
@ManyToMany
@IndexedEmbedded(structure = ObjectStructure.FLATTENED) (1)
private List<Author> authors = new ArrayList<>();
public Book() {
}
// Getters and setters
// ...
}| 1 | 显式地将索引嵌入的结构设置为FLATTENED。这并非严格必要,因为FLATTENED是默认设置。 |
@Entity
public class Author {
@Id
private Integer id;
@FullTextField(analyzer = "name")
private String firstName;
@FullTextField(analyzer = "name")
private String lastName;
@ManyToMany(mappedBy = "authors")
private List<Book> books = new ArrayList<>();
public Author() {
}
// Getters and setters
// ...
}前面提到的书籍实例将被索引,其结构大致类似于以下示例:
-
书籍文档
-
title = Leviathan Wakes
-
authors.firstName = [Daniel, Ty]
-
authors.lastName = [Abraham, Frank]
-
authors.firstName和authors.lastName字段被“扁平化”,现在每个字段都有两个值;哪个姓氏对应哪个名字的信息已经丢失。
这对于索引和查询更有效率,但当在作者的姓氏和作者的姓氏上同时查询索引时,可能会导致意外行为。
例如,上面描述的书籍实例**将**显示为与诸如authors.firstname:Ty AND authors.lastname:Abraham之类的查询匹配,即使“Ty Abraham”不是这本书的作者之一。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.and(
f.match().field( "authors.firstName" ).matching( "Ty" ), (1)
f.match().field( "authors.lastName" ).matching( "Abraham" ) (1)
) )
.fetchHits( 20 );
assertThat( hits ).isNotEmpty(); (2)| 1 | 要求匹配结果包含一个名为Ty的作者和一个名为Abraham的作者...但不一定是同一个作者! |
| 2 | 匹配结果将包含一个作者为“Ty Daniel”和“Frank Abraham”的书籍。 |
NESTED结构
当索引嵌入的元素是“嵌套”的,即使用@IndexedEmbedded(structure = NESTED)时,如以下示例所示,树结构将通过为每个索引嵌入的元素透明地创建一个单独的“嵌套”文档来保留。
@IndexedEmbedded带有嵌套结构@Entity
@Indexed
public class Book {
@Id
private Integer id;
@FullTextField(analyzer = "english")
private String title;
@ManyToMany
@IndexedEmbedded(structure = ObjectStructure.NESTED) (1)
private List<Author> authors = new ArrayList<>();
public Book() {
}
// Getters and setters
// ...
}| 1 | 显式地将索引嵌入对象的结构设置为NESTED。 |
@Entity
public class Author {
@Id
private Integer id;
@FullTextField(analyzer = "name")
private String firstName;
@FullTextField(analyzer = "name")
private String lastName;
@ManyToMany(mappedBy = "authors")
private List<Book> books = new ArrayList<>();
public Author() {
}
// Getters and setters
// ...
}前面提到的书籍实例将被索引,其结构大致类似于以下示例:
-
书籍文档
-
title = Leviathan Wakes
-
嵌套文档
-
“authors”的嵌套文档 #1
-
authors.firstName = Daniel
-
authors.lastName = Abraham
-
-
“authors”的嵌套文档 #2
-
authors.firstName = Ty
-
authors.lastName = Frank
-
-
-
书籍实际上被索引为三个文档:书籍的根文档,以及两个用于作者的内部“嵌套”文档,保留了哪个姓氏对应哪个名字的信息,但以索引和查询性能下降为代价。
| 嵌套文档是“隐藏”的,不会直接显示在搜索结果中。无需担心嵌套文档与根文档“混淆”。 |
如果在构建嵌套文档中字段的谓词时采取特殊措施,使用nested谓词,包含关于作者的姓氏和作者的姓氏的谓词的查询将按照预期(直观地)执行。
例如,上面描述的书籍实例**将不会**显示为与诸如authors.firstname:Ty AND authors.lastname:Abraham之类的查询匹配,这得益于nested谓词(只能在使用NESTED结构进行索引时使用)。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.nested( "authors" ) (1)
.add( f.match().field( "authors.firstName" ).matching( "Ty" ) ) (2)
.add( f.match().field( "authors.lastName" ).matching( "Abraham" ) ) ) (2)
.fetchHits( 20 );
assertThat( hits ).isEmpty(); (3)| 1 | 要求两个约束(姓氏和名字)应用于**同一个**作者。 |
| 2 | 要求匹配结果包含一个名为Ty的作者和一个名为Abraham的作者。 |
| 3 | 匹配结果**将不会**包含一个作者为“Ty Daniel”和“Frank Abraham”的书籍。 |
10.6.11. 过滤关联元素
有时,只有关联的某些元素应该包含在@IndexedEmbedded中。
例如,Book实体可能会索引嵌入BookEdition实例,但有些版本可能已经停用,因此需要在索引之前将其过滤掉。
可以通过将@IndexedEmbedded应用于表示已过滤关联的瞬态 getter,并使用@AssociationInverseSide和@IndexingDependency.derivedFrom配置重新索引来实现这种过滤。
@AssociationInverseSide和@IndexingDependency.derivedFrom过滤@IndexedEmbedded关联@Entity
@Indexed
public class Book {
@Id
private Integer id;
@FullTextField(analyzer = "english")
private String title;
@OneToMany(mappedBy = "book")
@OrderBy("id asc")
private List<BookEdition> editions = new ArrayList<>(); (1)
public Book() {
}
// Getters and setters
// ...
@Transient (2)
@IndexedEmbedded (3)
@AssociationInverseSide(inversePath = @ObjectPath({ (4)
@PropertyValue(propertyName = "book")
}))
@IndexingDependency(derivedFrom = @ObjectPath({ (5)
@PropertyValue(propertyName = "editions"),
@PropertyValue(propertyName = "status")
}))
public List<BookEdition> getEditionsNotRetired() {
return editions.stream()
.filter( e -> e.getStatus() != BookEdition.Status.RETIRED )
.collect( Collectors.toList() );
}
}@Entity
public class BookEdition {
public enum Status {
PUBLISHING,
RETIRED
}
@Id
private Integer id;
@ManyToOne
private Book book;
@FullTextField(analyzer = "english")
private String label;
private Status status; (6)
public BookEdition() {
}
// Getters and setters
// ...
}| 1 | Book和BookEdition之间的关联在 Hibernate ORM 中映射,但在 Hibernate Search 中没有映射。 |
| 2 | 瞬态editionsNotRetired属性动态地返回未停用的版本。 |
| 3 | @IndexedEmbedded应用于editionsNotRetired而不是editions。如果需要,可以使用`@IndexedEmbedded(name = "editions")`在搜索时使其透明。 |
| 4 | Hibernate ORM 不了解editionsNotRetired,因此 Hibernate Search 无法推断此“过滤”关联的反向端。因此,我们使用@AssociationInverseSide来告诉 Hibernate Search 这件事。如果BookEdition的标签被修改,Hibernate Search 将使用此信息检索相应的Book以重新索引。 |
| 5 | 我们使用@IndexingDependency.derivedFrom来告诉 Hibernate Search,只要版本的“状态”发生变化,getEditionsNotRetired()的结果也可能发生变化,需要重新索引。 |
| 6 | 虽然BookEdition#status没有被注释,但由于Book中的@IndexingDependency注释,Hibernate Search 仍然会跟踪其变化。 |
10.6.12. 编程映射
您也可以通过编程映射将关联对象的字段嵌入到主对象中。行为和选项与基于注释的映射相同。
.indexedEmbedded()索引关联元素此映射将在Book 索引中声明以下字段
-
title -
authors.name
TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "title" )
.fullTextField().analyzer( "english" );
bookMapping.property( "authors" )
.indexedEmbedded();
TypeMappingStep authorMapping = mapping.type( Author.class );
authorMapping.property( "name" )
.fullTextField().analyzer( "name" );10.7. 使用容器提取器映射容器类型
10.7.1. 基础
大多数应用于属性的内置注释在应用于容器类型时将透明地工作。
-
应用于
String类型属性的@GenericField将直接索引属性值。 -
应用于
OptionalInt类型属性的@GenericField将索引可选值(整数)。 -
应用于
List<String>类型属性的@GenericField将索引列表元素(字符串)。 -
应用于
Map<Integer, String>类型属性的@GenericField将索引映射值(字符串)。 -
应用于
Map<Integer, List<String>>类型属性的@GenericField将索引映射值中的列表元素(字符串)。 -
等等。
其他字段注释(如@FullTextField)和@IndexedEmbedded(尤其如此)也是如此。@VectorField是这种行为的例外,需要明确指令从容器中提取值。
幕后发生的是,Hibernate Search 将检查属性类型并尝试应用“容器提取器”,选择第一个可用的提取器。
10.7.2. 显式容器提取
在某些情况下,您需要显式选择要使用的容器提取器。如果需要索引映射的键而不是值,就会出现这种情况。相关注释提供了一个extraction属性来配置此操作,如下面的示例所示。
所有内置提取器名称都作为常量在org.hibernate.search.mapper.pojo.extractor.builtin.BuiltinContainerExtractors中可用。 |
Map键映射到索引字段@ElementCollection (1)
@JoinTable(name = "book_pricebyformat")
@MapKeyColumn(name = "format")
@Column(name = "price")
@OrderBy("format asc")
@GenericField( (2)
name = "availableFormats",
extraction = @ContainerExtraction(BuiltinContainerExtractors.MAP_KEY) (3)
)
private Map<BookFormat, BigDecimal> priceByFormat = new LinkedHashMap<>();| 1 | 此注释(以及下面的注释)只是 Hibernate ORM 配置。 |
| 2 | 根据priceByFormat属性声明索引字段。 |
| 3 | 默认情况下,Hibernate Search 会索引映射值(书籍价格)。这使用extraction属性来指定必须索引映射键(书籍格式)。 |
当需要多级提取时,可以配置多个提取器:extraction = @ContainerExtraction(BuiltinContainerExtractors.MAP_KEY, BuiltinContainerExtractors.OPTIONAL)。但是,这种复杂的映射不太可能,因为它们通常不受 Hibernate ORM 支持。 |
|
可以实现和使用自定义容器提取器,但目前 Hibernate Search 不会检测到此类容器内部数据的更改是否必须触发包含元素的重新索引。因此,必须禁用对应属性的更改重新索引。 有关详细信息,请参阅HSEARCH-3688。 |
10.7.3. 禁用容器提取
在某些罕见情况下,不希望进行容器提取,@GenericField/@IndexedEmbedded旨在直接应用于List/Optional等。为了忽略默认的容器提取器,大多数注释都提供了一个extraction属性。将其设置为以下内容以完全禁用提取。
@ManyToMany
@GenericField( (1)
name = "authorCount",
valueBridge = @ValueBridgeRef(type = MyCollectionSizeBridge.class), (2)
extraction = @ContainerExtraction(extract = ContainerExtract.NO) (3)
)
private List<Author> authors = new ArrayList<>();| 1 | 根据authors属性声明索引字段。 |
| 2 | 指示 Hibernate Search 使用给定的桥,它将提取集合大小(作者数量)。 |
| 3 | 由于桥应用于整个集合而不是每个作者,因此extraction属性用于禁用容器提取。 |
10.7.4. 编程映射
.extractor(…)/.extactors(…)进行显式容器提取器定义,将Map键映射到索引字段bookMapping.property( "priceByFormat" )
.genericField( "availableFormats" )
.extractor( BuiltinContainerExtractors.MAP_KEY );类似地,您可以禁用容器提取。
.noExtractors()禁用容器提取bookMapping.property( "authors" )
.genericField( "authorCount" )
.valueBridge( new MyCollectionSizeBridge() )
.noExtractors();10.8. 映射地理点类型
10.8.1. 基础
地理点有点例外,因为标准 Java 库中没有类型可以表示它们。为此,Hibernate Search 定义了自己的接口org.hibernate.search.engine.spatial.GeoPoint。由于您的模型可能使用不同的类型来表示地理点,因此映射地理点需要一些额外的步骤。
有两个选项可用。
10.8.2. 使用 @GenericField 和 GeoPoint 接口
当地理位置点在您的实体模型中由一个专用的、不可变的类型表示时,您只需让该类型实现 GeoPoint 接口,并使用简单的 属性/字段映射 以及 @GenericField。
GeoPoint 并使用 @GenericField 来映射空间坐标@Embeddable
public class MyCoordinates implements GeoPoint { (1)
@Basic
private Double latitude;
@Basic
private Double longitude;
protected MyCoordinates() {
// For Hibernate ORM
}
public MyCoordinates(double latitude, double longitude) {
this.latitude = latitude;
this.longitude = longitude;
}
@Override
public double latitude() { (2)
return latitude;
}
@Override
public double longitude() {
return longitude;
}
}@Entity
@Indexed
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
@Embedded
@GenericField (3)
private MyCoordinates placeOfBirth;
public Author() {
}
// Getters and setters
// ...
}| 1 | 将地理位置点建模为一个可嵌入的类型,它实现了 GeoPoint。一个具有相应 Hibernate ORM UserType 的自定义类型也可以工作。 |
| 2 | 地理位置点类型必须是不可变的:它不声明任何 setter。 |
| 3 | 将 @GenericField 注解应用于保存坐标的 placeOfBirth 属性。一个名为 placeOfBirth 的索引字段将被添加到索引中。通常用于 @GenericField 的选项也可以在这里使用。 |
|
地理位置点类型必须是不可变的,即给定实例的纬度和经度永远不能改变。 这是 如果保存您坐标的类型是可变的,请不要使用 |
|
如果您的地理位置点类型是不可变的,但扩展 |
10.8.3. 使用 @GeoPointBinding、@Latitude 和 @Longitude
对于坐标存储在可变对象中的情况,解决方案是 @GeoPointBinding 注解。它与 @Latitude 和 @Longitude 注解相结合,可以映射任何声明了纬度和经度为 double 类型的坐标。
@GeoPointBinding 来映射空间坐标@Entity
@Indexed
@GeoPointBinding(fieldName = "placeOfBirth") (1)
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
@Latitude (2)
private Double placeOfBirthLatitude;
@Longitude (3)
private Double placeOfBirthLongitude;
public Author() {
}
// Getters and setters
// ...
}| 1 | 将 @GeoPointBinding 注解应用于类型,将 fieldName 设置为索引字段的名称。 |
| 2 | 将 @Latitude 应用于保存纬度的属性。它必须是 double 或 Double 类型。 |
| 3 | 将 @Longitude 应用于保存经度的属性。它必须是 double 或 Double 类型。 |
@GeoPointBinding 注解也可以应用于属性,在这种情况下,@Latitude 和 @Longitude 必须应用于该属性类型的属性。
@GeoPointBinding 来映射空间坐标@Embeddable
public class MyCoordinates { (1)
@Basic
@Latitude (2)
private Double latitude;
@Basic
@Longitude (3)
private Double longitude;
protected MyCoordinates() {
// For Hibernate ORM
}
public MyCoordinates(double latitude, double longitude) {
this.latitude = latitude;
this.longitude = longitude;
}
public double getLatitude() {
return latitude;
}
public void setLatitude(Double latitude) { (4)
this.latitude = latitude;
}
public double getLongitude() {
return longitude;
}
public void setLongitude(Double longitude) {
this.longitude = longitude;
}
}@Entity
@Indexed
public class Author {
@Id
@GeneratedValue
private Integer id;
@FullTextField(analyzer = "name")
private String name;
@Embedded
@GeoPointBinding (5)
private MyCoordinates placeOfBirth;
public Author() {
}
// Getters and setters
// ...
}| 1 | 将地理位置点建模为可嵌入的类型。实体也可以工作。 |
| 2 | 在地理位置点类型中,将 @Latitude 应用于保存纬度的属性。 |
| 3 | 在地理位置点类型中,将 @Longitude 应用于保存经度的属性。 |
| 4 | 地理位置点类型可以安全地声明 setter(它可以是可变的)。 |
| 5 | 将 @GeoPointBinding 注解应用于属性。可以将 fieldName 设置为索引字段的名称,但不是必须的:默认情况下将使用属性名称。 |
可以通过多次应用注解并设置 markerSet 属性为一个唯一的值来处理多个坐标集。
@GeoPointBinding 来映射多个空间坐标集@Entity
@Indexed
@GeoPointBinding(fieldName = "placeOfBirth", markerSet = "birth") (1)
@GeoPointBinding(fieldName = "placeOfDeath", markerSet = "death") (2)
public class Author {
@Id
@GeneratedValue
private Integer id;
@FullTextField(analyzer = "name")
private String name;
@Latitude(markerSet = "birth") (3)
private Double placeOfBirthLatitude;
@Longitude(markerSet = "birth") (4)
private Double placeOfBirthLongitude;
@Latitude(markerSet = "death") (5)
private Double placeOfDeathLatitude;
@Longitude(markerSet = "death") (6)
private Double placeOfDeathLongitude;
public Author() {
}
// Getters and setters
// ...
}| 1 | 将 @GeoPointBinding 注解应用于类型,将 fieldName 设置为索引字段的名称,并将 markerSet 设置为一个唯一的值。 |
| 2 | 将 @GeoPointBinding 注解第二次应用于类型,将 fieldName 设置为索引字段的名称(与第一个不同),并将 markerSet 设置为一个唯一的值(与第一个不同)。 |
| 3 | 将 @Latitude 应用于保存第一个地理位置点字段的纬度的属性。将 markerSet 属性设置为与相应的 @GeoPointBinding 注解相同的值。 |
| 4 | 将 @Longitude 应用于保存第一个地理位置点字段的经度的属性。将 markerSet 属性设置为与相应的 @GeoPointBinding 注解相同的值。 |
| 5 | 将 @Latitude 应用于保存第二个地理位置点字段的纬度的属性。将 markerSet 属性设置为与相应的 @GeoPointBinding 注解相同的值。 |
| 6 | 将 @Longitude 应用于保存第二个地理位置点字段的经度的属性。将 markerSet 属性设置为与相应的 @GeoPointBinding 注解相同的值。 |
10.8.4. 程序化映射
您也可以通过 程序化映射 来映射地理位置点字段文档标识符。行为和选项与基于注解的映射相同。
GeoPoint 并使用 .genericField() 来映射空间坐标TypeMappingStep authorMapping = mapping.type( Author.class );
authorMapping.indexed();
authorMapping.property( "placeOfBirth" )
.genericField();GeoPointBinder 来映射空间坐标TypeMappingStep authorMapping = mapping.type( Author.class );
authorMapping.indexed();
authorMapping.binder( GeoPointBinder.create().fieldName( "placeOfBirth" ) );
authorMapping.property( "placeOfBirthLatitude" )
.marker( GeoPointBinder.latitude() );
authorMapping.property( "placeOfBirthLongitude" )
.marker( GeoPointBinder.longitude() );10.9. 映射多个备选方案
10.9.1. 基础
在某些情况下,需要根据另一个属性的值以不同的方式索引特定属性。
例如,可能存在一个实体,它的文本属性的内容根据另一个属性(例如 language)的值而不同。在这种情况下,您可能希望根据语言以不同的方式分析文本。
虽然这可以通过自定义 类型桥 来解决,但解决此问题的便捷方法是使用 AlternativeBinder。该绑定程序以这种方式解决问题
-
在引导时,为每种语言声明一个索引字段,为每个字段分配不同的分析器;
-
在运行时,根据语言将文本属性的内容放入不同的字段中。
为了使用该绑定程序,您需要
-
使用
@AlternativeDiscriminator注解属性(例如language属性); -
实现一个
AlternativeBinderDelegate,它将声明索引字段(例如,每种语言一个字段)并创建一个AlternativeValueBridge。该桥梁负责在运行时将属性值传递给相关字段。 -
将
AlternativeBinder应用于托管属性的类型(例如,声明language属性和多语言文本属性的类型)。通常,您希望为此创建自己的注解。
以下是如何使用该绑定程序的示例。
AlternativeBinder 将属性映射到根据 language 属性的不同索引字段public enum Language { (1)
ENGLISH( "en" ),
FRENCH( "fr" ),
GERMAN( "de" );
public final String code;
Language(String code) {
this.code = code;
}
}| 1 | Language 枚举定义了支持的语言。 |
@Entity
@Indexed
public class BlogEntry {
@Id
private Integer id;
@AlternativeDiscriminator (1)
@Enumerated(EnumType.STRING)
private Language language;
@MultiLanguageField (2)
private String text;
// Getters and setters
// ...
}| 1 | 将 language 属性标记为鉴别器,它将用于确定语言。 |
| 2 | 使用自定义注解将 text 属性映射到多个字段。 |
@Retention(RetentionPolicy.RUNTIME) (1)
@Target({ ElementType.METHOD, ElementType.FIELD }) (2)
@PropertyMapping(processor = @PropertyMappingAnnotationProcessorRef( (3)
type = MultiLanguageField.Processor.class
))
@Documented (4)
public @interface MultiLanguageField {
String name() default ""; (5)
class Processor (6)
implements PropertyMappingAnnotationProcessor<MultiLanguageField> { (7)
@Override
public void process(PropertyMappingStep mapping, MultiLanguageField annotation,
PropertyMappingAnnotationProcessorContext context) {
LanguageAlternativeBinderDelegate delegate = new LanguageAlternativeBinderDelegate( (8)
annotation.name().isEmpty() ? null : annotation.name()
);
mapping.hostingType() (9)
.binder( AlternativeBinder.create( (10)
Language.class, (11)
context.annotatedElement().name(), (12)
String.class, (13)
BeanReference.ofInstance( delegate ) (14)
) );
}
}
}| 1 | 定义一个具有 RUNTIME 保留策略的注解。任何其他保留策略都将导致 Hibernate Search 忽略该注解。 |
| 2 | 允许注解定位方法(getter)或字段。 |
| 3 | 将此注解标记为属性映射,并指示 Hibernate Search 在找到此注解时应用给定的处理器。也可以通过其 CDI/Spring bean 名称来引用处理器。 |
| 4 | 可选地,将注解标记为已记录,以便将其包含在实体的 javadoc 中。 |
| 5 | 可选地,定义参数。这里我们允许自定义字段名称(它将默认为属性名称,见下文)。 |
| 6 | 这里处理器类嵌套在注解类中,因为这样更方便,但您可以自由地在单独的 Java 文件中实现它。 |
| 7 | 处理器必须实现 PropertyMappingAnnotationProcessor 接口,并设置其泛型类型参数为相应注解的类型。 |
| 8 | 在注解处理器中,实例化一个自定义绑定程序委托(有关实现,见下文)。 |
| 9 | 访问托管属性的类型的映射(在本例中为 BlogEntry)。 |
| 10 | 将 AlternativeBinder 应用于托管属性的类型(在本例中为 BlogEntry)。 |
| 11 | 将鉴别器值的预期类型传递给 AlternativeBinder。 |
| 12 | 将应该从中提取字段值的属性的名称传递给 AlternativeBinder(在本例中为 text)。 |
| 13 | 将从其提取索引字段值的属性的预期类型传递给 AlternativeBinder。 |
| 14 | 将绑定程序委托传递给 AlternativeBinder。 |
public class LanguageAlternativeBinderDelegate implements AlternativeBinderDelegate<Language, String> { (1)
private final String name;
public LanguageAlternativeBinderDelegate(String name) { (2)
this.name = name;
}
@Override
public AlternativeValueBridge<Language, String> bind(IndexSchemaElement indexSchemaElement, (3)
PojoModelProperty fieldValueSource) {
EnumMap<Language, IndexFieldReference<String>> fields = new EnumMap<>( Language.class );
String fieldNamePrefix = ( name != null ? name : fieldValueSource.name() ) + "_";
for ( Language language : Language.values() ) { (4)
String languageCode = language.code;
IndexFieldReference<String> field = indexSchemaElement.field(
fieldNamePrefix + languageCode, (5)
f -> f.asString().analyzer( "text_" + languageCode ) (6)
)
.toReference();
fields.put( language, field );
}
return new Bridge( fields ); (7)
}
private static class Bridge (8)
implements AlternativeValueBridge<Language, String> { (9)
private final EnumMap<Language, IndexFieldReference<String>> fields;
private Bridge(EnumMap<Language, IndexFieldReference<String>> fields) {
this.fields = fields;
}
@Override
public void write(DocumentElement target, Language discriminator, String bridgedElement) {
target.addValue( fields.get( discriminator ), bridgedElement ); (10)
}
}
}| 1 | 绑定程序委托必须实现 AlternativeBinderDelegate。第一个类型参数是鉴别器值的预期类型(在本例中为 Language);第二个类型参数是应从中提取字段值的属性的预期类型(在本例中为 String)。 |
| 2 | 任何(自定义)参数都可以通过构造函数传递。 |
| 3 | 实现 bind,将属性绑定到索引字段。 |
| 4 | 为每种语言定义一个字段。 |
| 5 | 确保为每个字段指定不同的名称。这里我们使用语言代码作为后缀,即 text_en、text_fr、text_de 等。 |
| 6 | 为每个字段分配不同的分析器。分析器 text_en、text_fr、text_de 必须在后端定义;见 分析。 |
| 7 | 返回一个桥梁。 |
| 8 | 这里桥梁类嵌套在绑定程序类中,因为这样更方便,但您可以自由地根据需要实现它:作为 lambda 表达式,在单独的 Java 文件中等等。 |
| 9 | 桥梁必须实现 AlternativeValueBridge 接口。 |
| 10 | 桥梁在索引时被调用;它根据鉴别器值选择要写入的字段,然后将值写入索引到该字段。 |
10.9.2. 程序化映射
您也可以通过 程序化映射 来应用 AlternativeBinder。行为和选项与基于注解的映射相同。
.binder(…) 应用 AlternativeBinderTypeMappingStep blogEntryMapping = mapping.type( BlogEntry.class );
blogEntryMapping.indexed();
blogEntryMapping.property( "language" )
.marker( AlternativeBinder.alternativeDiscriminator() );
LanguageAlternativeBinderDelegate delegate = new LanguageAlternativeBinderDelegate( null );
blogEntryMapping.binder( AlternativeBinder.create( Language.class,
"text", String.class, BeanReference.ofInstance( delegate ) ) );10.10. 调节何时触发重新索引
10.10.1. 基础
当实体属性映射到索引时,无论是通过 @GenericField、@IndexedEmbedded 还是 自定义桥梁,这种映射都引入了依赖关系:当属性更改时,需要更新文档。
对于更简单的单实体映射,这仅仅意味着 Hibernate Search 需要检测实体何时发生更改并重新索引实体。这将以透明方式处理。
如果映射包含“派生”属性,即未直接持久化但是在使用其他属性作为输入的 getter 中动态计算的属性,则 Hibernate Search 将无法推断这些属性基于持久状态的哪一部分。在这种情况下,需要一些显式配置;有关更多信息,请参见 当派生值更改时使用 @IndexingDependency 重新索引。
当映射跨越实体边界时,事情会变得更加复杂。让我们考虑一个映射,其中一个 Book 实体被映射到一个文档,并且该文档必须包含 Author 实体的 name 属性(例如使用 @IndexedEmbedded)。每当作者的姓名更改时,Hibernate Search 都会需要检索该作者的所有书籍,以重新索引它们。
实际上,这意味着每当实体映射依赖于与另一个实体的关联时,这种关联必须是双向的:如果 Book.authors 是 @IndexedEmbedded,则 Hibernate Search 必须知道反向关联 Author.books。如果无法解析反向关联,则在启动时将抛出异常。
大多数情况下,当使用 Hibernate ORM 集成 时,Hibernate Search 可以利用 Hibernate ORM 元数据(@OneToOne 和 @OneToMany 的 mappedBy 属性)来解析关联的反向端,因此这一切都是透明处理的。
在某些罕见的情况下,对于更复杂的映射,即使 Hibernate ORM 也可能不知道关联是双向的,因为无法使用 mappedBy,或者因为使用的是 独立 POJO 映射器。存在一些解决方案
-
关联可以简单地被忽略。这意味着每当关联实体更改时索引都会过期,但如果索引定期重建,这可能是一个可接受的解决方案。有关更多信息,请参见 使用
@IndexingDependency限制包含实体的重新索引。 -
如果关联实际上是双向的,则可以使用
@AssociationInverseSide显式地将它的反向端指定给 Hibernate Search。有关更多信息,请参见 使用@AssociationInverseSide丰富实体模型。
10.10.2. 使用 @AssociationInverseSide 丰富实体模型
给定从实体类型 A 到实体类型 B 的关联,@AssociationInverseSide 定义了关联的反向端,即从 B 到 A 的路径。
这在使用 独立 POJO 映射器 或使用 Hibernate ORM 集成 并且双向关联在 Hibernate ORM 中未被映射为双向关联(没有 mappedBy)时特别有用。
@AssociationInverseSide 映射关联的反向端@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
@ElementCollection (1)
@JoinTable(
name = "book_editionbyprice",
joinColumns = @JoinColumn(name = "book_id")
)
@MapKeyJoinColumn(name = "edition_id")
@Column(name = "price")
@OrderBy("edition_id asc")
@IndexedEmbedded( (2)
name = "editionsForSale",
extraction = @ContainerExtraction(BuiltinContainerExtractors.MAP_KEY)
)
@AssociationInverseSide( (3)
extraction = @ContainerExtraction(BuiltinContainerExtractors.MAP_KEY),
inversePath = @ObjectPath(@PropertyValue(propertyName = "book"))
)
private Map<BookEdition, BigDecimal> priceByEdition = new LinkedHashMap<>();
public Book() {
}
// Getters and setters
// ...
}@Entity
public class BookEdition {
@Id
@GeneratedValue
private Integer id;
@ManyToOne (4)
private Book book;
@FullTextField(analyzer = "english")
private String label;
public BookEdition() {
}
// Getters and setters
// ...
}| 1 | 此注释和以下注释是 Map<BookEdition, BigDecimal> 的 Hibernate ORM 映射,其中键是 BookEdition 实体,值是该版本的價格。 |
| 2 | 索引嵌入实际上待售的版本。 |
| 3 | 在 Hibernate ORM 中,无法为由 Map 键建模的关联使用 mappedBy。因此,我们使用 @AssociationInverseSide 来告诉 Hibernate Search 此关联的反向端是什么。 |
| 4 | 我们也可以在这里应用 @AssociationInverseSide 注释:任何一边都可以。 |
10.10.3. 当派生值更改时使用 @IndexingDependency 重新索引
当属性未直接持久化,而是在使用其他属性作为输入的 getter 中动态计算时,Hibernate Search 将无法推断这些属性基于持久状态的哪一部分,因此将无法 触发重新索引 当相关的持久状态更改时。默认情况下,Hibernate Search 将在引导时检测此类情况并抛出异常。
使用 @IndexingDependency(derivedFrom = …) 注释属性将为 Hibernate Search 提供它所需的信息并允许 触发重新索引。
@IndexingDependency.derivedFrom 映射派生值@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
@ElementCollection
private List<String> authors = new ArrayList<>(); (1)
public Book() {
}
// Getters and setters
// ...
@Transient (2)
@FullTextField(analyzer = "name") (3)
@IndexingDependency(derivedFrom = @ObjectPath({ (4)
@PropertyValue(propertyName = "authors")
}))
public String getMainAuthor() {
return authors.isEmpty() ? null : authors.get( 0 );
}
}| 1 | 作者被建模为包含作者姓名的字符串列表。 |
| 2 | 瞬态 mainAuthor 属性动态返回主要作者(第一个)。 |
| 3 | 我们在 getMainAuthor() getter 上使用 @FullTextField 来索引主要作者的姓名。 |
| 4 | 我们使用 @IndexingDependency.derivedFrom 来告诉 Hibernate Search,每当作者列表更改时,getMainAuthor() 的结果可能也会更改。 |
10.10.4. 使用 @IndexingDependency 限制包含实体的重新索引
在某些情况下,触发重新索引 每当给定属性更改时,实体的效率都很低
-
当关联很大时,例如单个实体实例在数千个其他实体中 被索引嵌入。
-
当映射到索引的属性非常频繁地更新时,会导致非常频繁的重新索引,并且磁盘或数据库的使用量不可接受。
-
等等。
当发生这种情况时,可以告诉 Hibernate Search 忽略对特定属性的更新(并且在 @IndexedEmbedded 的情况下,忽略该属性之外的任何内容)。
有几种选项可用于精确控制对给定属性的更新如何影响重新索引。有关每个选项的说明,请参见以下部分。
ReindexOnUpdate.SHALLOW:仅将重新索引限制为相同实体的更新
ReindexOnUpdate.SHALLOW 在关联高度不对称且因此是单向的情况下最为有用。想想与“引用”数据(如类别、类型、城市、国家/地区等)的关联。
它本质上告诉 Hibernate Search 更改关联——添加或删除关联的元素,即“浅层”更新——应该触发对发生更改的对象的重新索引,但更改关联实体的属性——“深层”更新——不应该触发重新索引。
例如,让我们考虑以下(不正确)映射
@Entity
@Indexed
public class Book {
@Id
private Integer id;
private String title;
@ManyToOne (1)
@IndexedEmbedded (2)
private BookCategory category;
public Book() {
}
// Getters and setters
// ...
}@Entity
public class BookCategory {
@Id
private Integer id;
@FullTextField(analyzer = "english")
private String name;
(3)
// Getters and setters
// ...
}| 1 | 每本书都与 BookCategory 实体关联。 |
| 2 | 我们想要 索引嵌入 BookCategory 到 Book 中… |
| 3 | …但我们真的不想建模从 BookCategory 到 Book 的(巨大)反向关联:每个类别可能包含数千本书籍,因此调用 getBooks() 方法会导致将数千个实体一次性加载到 Hibernate ORM 会话中,并且性能很差。因此,没有 getBooks() 方法来列出类别中的所有书籍。 |
使用此映射,当类别名称更改时,Hibernate Search 将无法重新索引所有书籍:用于列出该类别所有书籍的 getter 不存在。由于 Hibernate Search 默认情况下会尝试保持安全,因此它将拒绝此映射并在引导时抛出异常,指出它需要 Book → BookCategory 关联的反向端。
但是,在这种情况下,我们并不期望 BookCategory 的名称更改。这确实是“引用”数据,它更改得如此之少,以至于我们可以合理地提前规划此类更改,并在发生更改时 重新索引所有书籍。因此,如果 Hibernate Search 只是忽略了对 BookCategory 的更改,我们真的不会介意…
这就是 @IndexingDependency(reindexOnUpdate = ReindexOnUpdate.SHALLOW) 的作用:它告诉 Hibernate Search 忽略对关联实体更新的影响。请参见下面的修改后的映射
ReindexOnUpdate.SHALLOW 将重新索引限制为相同实体的更新@Entity
@Indexed
public class Book {
@Id
private Integer id;
private String title;
@ManyToOne
@IndexedEmbedded
@IndexingDependency(reindexOnUpdate = ReindexOnUpdate.SHALLOW) (1)
private BookCategory category;
public Book() {
}
// Getters and setters
// ...
}| 1 | 我们使用 ReindexOnUpdate.SHALLOW 来告诉 Hibernate Search 当为 Book 分配一个新类别(book.setCategory( newCategory ))时应该重新索引 Book,但当其类别的属性更改时(category.setName( newName ))不应该重新索引。 |
Hibernate Search 将接受上面的映射并成功启动,因为 Book 到 BookCategory 关联的反向端不再被认为是必要的。
只有对书籍类别的浅层更改才会触发该书籍的重新索引
-
当为书籍分配一个新类别(
book.setCategory( newCategory ))时,Hibernate Search 将认为这是一种“浅层”更改,因为它只影响Book实体。因此,Hibernate Search 将重新索引该书籍。 -
当类别本身发生更改时(
category.setName( newName )),Hibernate Search 将认为这是一种“深层”更改,因为它发生在Book实体的边界之外。因此,Hibernate Search 将不会自行重新索引该类别的书籍。索引将变得稍微不同步,但这可以通过 重新索引Book实体来解决,例如每晚一次。
ReindexOnUpdate.NO:禁用由特定属性更新引起的重新索引
ReindexOnUpdate.NO 最适合那些频繁更改且不需要在索引中保持最新状态的属性。
它本质上告诉 Hibernate Search 对该属性的更改不应该 触发重新索引,
例如,让我们考虑下面的映射
@Entity
@Indexed
public class Sensor {
@Id
private Integer id;
@FullTextField
private String name; (1)
@KeywordField
private SensorStatus status; (1)
@Column(name = "\"value\"")
private double value; (2)
@GenericField
private double rollingAverage; (3)
public Sensor() {
}
// Getters and setters
// ...
}| 1 | 传感器名称和状态很少更新。 |
| 2 | 传感器值每隔几毫秒更新一次 |
| 3 | 当传感器值更新时,我们还会更新过去几秒内的滚动平均值(基于此处未显示的数据)。 |
对名称和状态的更新(很少更新)可以很好地触发重新索引。但考虑到有数千个传感器,对传感器值的更新无法合理地触发重新索引:每隔几毫秒重新索引数千个传感器可能无法很好地执行。
但是,在此场景中,对传感器值的搜索不被认为是关键的,索引不需要那么新鲜。我们可以在传感器值方面接受索引滞后几分钟。我们可以考虑设置一个每隔几秒运行一次的批处理进程来重新索引所有传感器,无论是通过 批量索引器、使用 Jakarta Batch 批量索引作业,还是 显式地。因此,如果 Hibernate Search 只是忽略了对传感器值的更改,我们真的不会介意…
这就是 @IndexingDependency(reindexOnUpdate = ReindexOnUpdate.NO) 的作用:它告诉 Hibernate Search 忽略对 rollingAverage 属性更新的影响。请参见下面的修改后的映射
ReindexOnUpdate.NO 禁用由侦听器触发的特定属性的重新索引@Entity
@Indexed
public class Sensor {
@Id
private Integer id;
@FullTextField
private String name;
@KeywordField
private SensorStatus status;
@Column(name = "\"value\"")
private double value;
@GenericField
@IndexingDependency(reindexOnUpdate = ReindexOnUpdate.NO) (1)
private double rollingAverage;
public Sensor() {
}
// Getters and setters
// ...
}| 1 | 我们使用 ReindexOnUpdate.NO 来告诉 Hibernate Search 对 rollingAverage 的更新不应该 触发重新索引。 |
使用此映射
-
当传感器被分配一个新名称(
sensor.setName( newName ))或状态(sensor.setStatus( newStatus ))时,Hibernate Search 将触发传感器的重新索引。 -
当传感器被分配一个新的滚动平均值(
sensor.setRollingAverage( newName ))时,Hibernate Search 不会触发传感器的重新索引。
10.10.5. 程序化映射
您也可以通过程序化映射来控制重新索引。行为和选项与基于注释的映射相同。
.associationInverseSide(…)映射关联的反向边TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "priceByEdition" )
.indexedEmbedded( "editionsForSale" )
.extractor( BuiltinContainerExtractors.MAP_KEY )
.associationInverseSide( PojoModelPath.parse( "book" ) )
.extractor( BuiltinContainerExtractors.MAP_KEY );
TypeMappingStep bookEditionMapping = mapping.type( BookEdition.class );
bookEditionMapping.property( "label" )
.fullTextField().analyzer( "english" );.indexingDependency().derivedFrom(…)映射派生值TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "mainAuthor" )
.fullTextField().analyzer( "name" )
.indexingDependency().derivedFrom( PojoModelPath.parse( "authors" ) );.indexingDependency().reindexOnUpdate(…)限制触发重新索引TypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "category" )
.indexedEmbedded()
.indexingDependency().reindexOnUpdate( ReindexOnUpdate.SHALLOW );
TypeMappingStep bookCategoryMapping = mapping.type( BookCategory.class );
bookCategoryMapping.property( "name" )
.fullTextField().analyzer( "english" );10.11. 更改现有应用程序的映射
在应用程序的整个生命周期中,特定索引实体类型的映射需要更改的情况会发生。发生这种情况时,映射更改很可能需要更改索引的结构,即它的模式。Hibernate Search 不会自动处理这种结构更改,因此需要手动干预。
当索引结构需要更改时,最简单的解决方案是
|
从技术上讲,如果映射更改仅包含以下内容,则严格不需要删除索引并重新索引
但是,您仍然需要
|
10.12. 自定义映射注释
10.12.1. 基础
默认情况下,Hibernate Search 只识别内置的映射注释,例如@Indexed、@GenericField或@IndexedEmbedded。
要在 Hibernate Search 映射中使用自定义注释,需要执行两个步骤
-
为该注释实现一个处理器:
TypeMappingAnnotationProcessor用于类型注释,PropertyMappingAnnotationProcessor用于方法/字段注释,ConstructorMappingAnnotationProcessor用于构造函数注释,或MethodParameterMappingAnnotationProcessor用于构造函数参数注释。 -
使用
@TypeMapping、@PropertyMapping、@ConstructorMapping或@MethodParameterMapping注释自定义注释,并将对注释处理器的引用作为参数传递。
完成此操作后,Hibernate Search 将能够在索引类中检测到自定义注释(但不一定在自定义投影类型中,请参见自定义根映射注释)。每当遇到自定义注释时,Hibernate Search 将实例化注释处理器并调用其process方法,并将以下内容作为参数传递
-
一个
mapping参数,允许使用程序化映射 API为类型、属性、构造函数或构造函数参数定义映射。 -
一个
annotation参数,表示注释实例。 -
一个带有各种帮助程序的
context对象。
自定义注释最常用于应用自定义的参数化绑定程序或桥接器。您可以在以下部分中找到示例
|
完全可以使用自定义注释来实现无参数的绑定程序或桥接器,甚至更复杂的功能,例如索引嵌入:程序化映射 API中的每个功能都可以通过自定义注释触发。 |
10.13. 检查映射
Hibernate Search 成功启动后,可以使用SearchMapping获取索引实体的列表,并获得对相应索引的更直接访问,如以下示例所示。
SearchMapping mapping = /* ... */ (1)
SearchIndexedEntity<Book> bookEntity = mapping.indexedEntity( Book.class ); (2)
String jpaName = bookEntity.jpaName(); (3)
IndexManager indexManager = bookEntity.indexManager(); (4)
Backend backend = indexManager.backend(); (5)
SearchIndexedEntity<?> bookEntity2 = mapping.indexedEntity( "Book" ); (6)
Class<?> javaClass = bookEntity2.javaClass();
for ( SearchIndexedEntity<?> entity : mapping.allIndexedEntities() ) { (7)
// ...
}| 1 | 检索 SearchMapping. |
| 2 | 通过其实体类检索SearchIndexedEntity。SearchIndexedEntity提供对该实体及其索引的相关信息的访问。 |
| 3 | (仅限Hibernate ORM 集成)获取该实体的 JPA 名称。 |
| 4 | 获取该实体的索引管理器。 |
| 5 | 获取该索引管理器的后端。 |
| 6 | 通过其实体名称检索SearchIndexedEntity。 |
| 7 | 检索所有索引实体。 |
从IndexManager中,您还可以访问索引元模型,以检查可用字段及其主要特征,如下所示。
SearchIndexedEntity<Book> bookEntity = mapping.indexedEntity( Book.class ); (1)
IndexManager indexManager = bookEntity.indexManager(); (2)
IndexDescriptor indexDescriptor = indexManager.descriptor(); (3)
indexDescriptor.field( "releaseDate" ).ifPresent( field -> { (4)
String path = field.absolutePath(); (5)
String relativeName = field.relativeName();
// Etc.
if ( field.isValueField() ) { (6)
IndexValueFieldDescriptor valueField = field.toValueField(); (7)
IndexValueFieldTypeDescriptor type = valueField.type(); (8)
boolean projectable = type.projectable();
Class<?> dslArgumentClass = type.dslArgumentClass();
Class<?> projectedValueClass = type.projectedValueClass();
Optional<String> analyzerName = type.analyzerName();
Optional<String> searchAnalyzerName = type.searchAnalyzerName();
Optional<String> normalizerName = type.normalizerName();
// Etc.
Set<String> traits = type.traits(); (9)
if ( traits.contains( IndexFieldTraits.Aggregations.RANGE ) ) {
// ...
}
}
else if ( field.isObjectField() ) { (10)
IndexObjectFieldDescriptor objectField = field.toObjectField();
IndexObjectFieldTypeDescriptor type = objectField.type();
boolean nested = type.nested();
// Etc.
}
} );
Collection<? extends AnalyzerDescriptor> analyzerDescriptors = indexDescriptor.analyzers(); (11)
for ( AnalyzerDescriptor analyzerDescriptor : analyzerDescriptors ) {
String analyzerName = analyzerDescriptor.name();
// ...
}
Optional<? extends AnalyzerDescriptor> analyzerDescriptor = indexDescriptor.analyzer( "some-analyzer-name" ); (12)
// ...
Collection<? extends NormalizerDescriptor> normalizerDescriptors = indexDescriptor.normalizers(); (13)
for ( NormalizerDescriptor normalizerDescriptor : normalizerDescriptors ) {
String normalizerName = normalizerDescriptor.name();
// ...
}
Optional<? extends NormalizerDescriptor> normalizerDescriptor = indexDescriptor.normalizer( "some-normalizer-name" ); (14)
// ...| 1 | 检索SearchIndexedEntity。 |
| 2 | 获取该实体的索引管理器。IndexManager提供对索引相关信息的访问。这包括元模型,但不仅如此(见下文)。 |
| 3 | 获取该索引的描述符。描述符公开了索引元模型。 |
| 4 | 通过名称检索字段。该方法返回一个Optional,如果字段不存在,则为空。 |
| 5 | 字段描述符公开了有关字段结构的信息:路径、名称、父级,… |
| 6 | 检查字段是否为值字段,它保存一个值(整数、文本,…),而不是对象字段,它保存其他字段。 |
| 7 | 将字段描述符缩小到值字段描述符。 |
| 8 | 获取字段类型的描述符。类型描述符公开了有关字段功能的信息:它是否可搜索、可排序、可投影,Search DSL的参数的预期 Java 类是什么,在该字段上设置了哪些分析器/规范化器,… |
| 9 | 检查字段类型的“特性”:每个特性都表示可以对该类型的字段使用的谓词/排序/投影/聚合。 |
| 10 | 对象字段也可以被检查。 |
| 11 | 还可以检查描述符所表示的索引的所有已配置分析器的集合。 |
| 12 | 或者,可以通过名称检索分析器描述符,以查看特定分析器是否在索引上下文中可用。 |
| 13 | 还可以检查描述符所表示的索引的所有已配置规范化器的集合。 |
| 14 | 或者,可以通过名称检索规范化器描述符,以查看特定规范化器是否在索引上下文中可用。 |
|
|
SearchMapping还公开了方法,用于通过名称检索IndexManager,甚至通过名称检索整个Backend。
11. 将索引内容映射到自定义类型(投影构造函数)
11.1. 基础
投影允许直接从匹配的文档中检索数据作为搜索查询的结果。随着文档和投影的结构变得更加复杂,对 Projection DSL 的程序化调用也变得更加复杂,这会导致难以理解的投影定义。
为了解决这个问题,Hibernate Search 提供了通过映射自定义类型(通常是记录)来定义投影的能力,方法是在这些类型或其构造函数上应用@ProjectionConstructor注释。执行这样的投影就像引用自定义类型一样简单。
这样的投影是复合的,它们的内部投影(组件)从投影构造函数参数的名称和类型推断而来。
|
在注释自定义投影类型时,需要牢记以下几点约束
|
@ProjectionConstructor (1)
public record MyBookProjection(
@IdProjection Integer id, (2)
String title, (3)
List<Author> authors) { (4)
@ProjectionConstructor (5)
public record Author(String firstName, String lastName) {
}
}| 1 | 在记录类型上使用 `@ProjectionConstructor` 进行注释,可以在类型级别(如果只有一个构造函数)或构造函数级别(如果有多个构造函数,请参阅 多个构造函数)。 |
| 2 | 要在实体标识符上进行投影,请使用 @IdProjection 对相关构造函数参数进行注释。大多数投影都有一个相应的注释,可以在构造函数参数上使用。 |
| 3 | 要在值字段上进行投影,请添加一个以该字段命名的构造函数参数,其类型与该字段相同。有关如何定义构造函数参数的更多信息,请参阅 隐式内部投影推理。 或者,可以使用 |
| 4 | 要在对象字段上进行投影,请添加一个以该字段命名的构造函数参数,并使用其自己的自定义投影类型。多值投影 必须建模为 `List<…>` 或超类型。 或者,可以使用 |
| 5 | 对用于对象字段的任何自定义投影类型使用 `@ProjectionConstructor` 进行注释。 |
List<MyBookProjection> hits = searchSession.search( Book.class )
.select( MyBookProjection.class ) (1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每个匹配项将是自定义投影类型的实例,并填充从索引检索到的数据。 |
|
自定义的非记录类也可以使用 `@ProjectionConstructor` 进行注释,如果您由于某种原因(例如您仍在使用 Java 13 或更低版本)而无法使用记录,这将很有用。 |
上面的示例执行的投影等效于以下代码
List<MyBookProjection> hits = searchSession.search( Book.class )
.select( f -> f.composite()
.from(
f.id( Integer.class ),
f.field( "title", String.class ),
f.object( "authors" )
.from(
f.field( "authors.firstName", String.class ),
f.field( "authors.lastName", String.class )
)
.as( MyBookProjection.Author::new )
.multi()
)
.as( MyBookProjection::new ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );11.2. 映射投影类型的检测
Hibernate Search 必须在启动时知道投影类型,它通常会在它们使用 `@ProjectionConstructor` 进行注释后立即完成,这得益于类路径扫描。
有关类路径扫描以及如何对其进行调整(例如扫描依赖项而不是仅扫描应用程序 JAR)的更多信息,请参阅 类路径扫描。
11.3. 隐式内部投影推理
11.3.1. 基础
当构造函数参数未使用 显式投影注释 进行注释时,Hibernate Search 会根据这些参数的名称和类型应用一些基本推理规则,以选择(内部)投影。
以下部分说明如何定义构造函数参数的名称和类型以获得所需的投影。
11.3.2. 内部投影和类型
当构造函数参数未使用 显式投影注释 进行注释时,Hibernate Search 会从相应构造函数参数的类型推断内部投影的类型。
您应根据以下规则设置构造函数参数的类型
-
对于单值投影
-
对于 值字段上的投影(通常使用
@FullTextField/@GenericField/等进行映射),请将参数类型设置为目标字段的 投影值类型,通常是使用 `@FullTextField` / `@GenericField` / 等进行注释的属性的类型。 -
对于 对象字段上的投影(通常使用
@IndexedEmbedded进行映射),请将参数类型设置为使用 `@ProjectionConstructor` 进行注释的另一个自定义类型,其构造函数将定义要从该对象字段中提取哪些字段。
-
-
对于多值投影,请遵循上述规则,然后将类型包装在 `Iterable`、`Collection` 或 `List` 中,例如 `Iterable<SomeType>`、`Collection<SomeType>` 或 `List<SomeType>`。
|
用于表示多值投影的构造函数参数 **只能** 具有类型 `Iterable<…>`、`Collection<…>` 或 `List<…>`。 目前不支持其他容器类型,例如 `Map` 或 `Optional` 。 |
11.3.3. 内部投影和字段路径
当构造函数参数未使用 显式投影注释 进行注释或已注释但该注释未提供显式路径时,Hibernate Search 会从相应构造函数参数的名称推断要投影的字段的路径。
在这种情况下,您应该将构造函数参数的名称(在 Java 代码中)设置为要投影的字段的名称。
|
Hibernate Search 只能检索构造函数参数的名称
|
11.4. 显式内部投影
构造函数参数可以使用显式投影注释进行注释,例如 `@IdProjection` 或 `@FieldProjection`。
对于通常会 自动推断 的投影,这允许进一步定制,例如在 字段投影 中显式设置目标字段路径或禁用值转换。或者,在 对象投影 中,这也允许 打破嵌套对象投影的循环。
对于其他投影,例如 标识符投影,这实际上是它们在投影构造函数中使用的唯一方法,因为它们永远不会自动推断。
有关要应用于投影构造函数参数的相应内置注释的更多信息,请参阅 每个投影的文档。
11.5. 映射具有多个构造函数的类型
如果投影类型(记录或类)具有多个构造函数,则 `@ProjectionConstructor` 注释不能应用于类型级别,而必须应用于您希望用于投影的构造函数。
public class MyAuthorProjectionClassMultiConstructor {
public final String firstName;
public final String lastName;
@ProjectionConstructor (1)
public MyAuthorProjectionClassMultiConstructor(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public MyAuthorProjectionClassMultiConstructor(String fullName) { (2)
this( fullName.split( " " )[0], fullName.split( " " )[1] );
}
// ... Equals and hashcode ...
}| 1 | 使用 `@ProjectionConstructor` 对要用于投影的构造函数进行注释。 |
| 2 | 其他构造函数可以用于除投影之外的其他目的,但它们 **不能** 使用 `@ProjectionConstructor` 进行注释(只允许一个这样的构造函数)。 |
在记录的情况下,(隐式)规范构造函数也可以进行注释,但这需要使用特定语法在代码中表示该构造函数
public record MyAuthorProjectionRecordMultiConstructor(String firstName, String lastName) {
@ProjectionConstructor (1)
public MyAuthorProjectionRecordMultiConstructor { (2)
}
public MyAuthorProjectionRecordMultiConstructor(String fullName) { (3)
this( fullName.split( " " )[0], fullName.split( " " )[1] );
}
}| 1 | 使用 `@ProjectionConstructor` 对要用于投影的构造函数进行注释。 |
| 2 | (隐式)规范构造函数使用特定语法,没有括号或参数。 |
| 3 | 其他构造函数可以用于除投影之外的其他目的,但它们 **不能** 使用 `@ProjectionConstructor` 进行注释(只允许一个这样的构造函数)。 |
11.6. 编程映射
您也可以通过 编程映射 映射投影构造函数。行为和选项与基于注释的映射相同。
TypeMappingStep myBookProjectionMapping = mapping.type( MyBookProjection.class );
myBookProjectionMapping.mainConstructor()
.projectionConstructor(); (1)
myBookProjectionMapping.mainConstructor().parameter( 0 )
.projection( IdProjectionBinder.create() ); (2)
TypeMappingStep myAuthorProjectionMapping = mapping.type( MyBookProjection.Author.class );
myAuthorProjectionMapping.mainConstructor()
.projectionConstructor();如果投影类型(记录或类)具有多个构造函数,则需要使用 `。constructor(…)` 而不是 `。mainConstructor()`,并将构造函数参数的(原始)类型作为参数传递。
mapping.type( MyAuthorProjectionClassMultiConstructor.class )
.constructor( String.class, String.class )
.projectionConstructor();12. 绑定和桥梁
12.1. 基础
在 Hibernate Search 中,绑定 是将自定义组件分配给域模型的过程。
可以绑定的最直观的组件是桥梁,它们负责将数据从实体模型转换为文档模型。
例如,当 `@GenericField` 应用于自定义枚举类型的属性时,将使用内置桥梁在索引时将此枚举转换为字符串,并在投影时将字符串转换回枚举。
同样,当类型为 `Long` 的实体标识符映射到文档标识符时,将使用内置桥梁在索引时将 `Long` 转换为 `String`(因为所有文档标识符都是字符串),并在加载搜索结果时将 `String` 转换回 `Long`。
桥梁不仅限于一对一映射:例如,@GeoPointBinding 注释(将使用 `@Latitude` 和 `@Longitude` 进行注释的两个属性映射到单个字段)由另一个内置桥梁支持。
虽然内置桥梁为各种标准类型提供,但它们可能不足以满足复杂模型的需求。这就是桥梁真正有用的原因:可以实现自定义桥梁并在 Hibernate Search 映射中引用它们。使用自定义桥梁,可以映射自定义类型,甚至可以映射需要在索引时执行用户代码的复杂类型。
有多种类型的桥梁,将在下一节中详细介绍。如果您需要实现自定义桥梁,但不太清楚需要哪种类型的桥梁,以下表格可能会有所帮助
| 桥梁类型 | ValueBridge |
PropertyBridge |
TypeBridge |
IdentifierBridge |
RoutingBridge |
|---|---|---|---|---|---|
应用于… |
类字段或 getter |
类字段或 getter |
类 |
类字段或 getter(通常是实体 ID) |
类 |
映射到… |
一个索引字段。仅值字段:整数、文本、地理点等。没有 对象字段(复合)。 |
一个或多个索引字段。值字段以及 对象字段(复合)。 |
一个或多个索引字段。值字段以及 对象字段(复合)。 |
文档标识符 |
路由(条件索引,路由键) |
内置注释 |
|
|
|
||
支持 容器提取器 |
是 |
否 |
否 |
否 |
否 |
支持可变类型 |
否 |
是 |
是 |
否 |
是 |
12.2. 值桥梁
12.2.1. 基础
值桥是一种可插拔组件,用于实现属性到索引字段的映射。它应用于具有 @*Field 注释(@GenericField、@FullTextField 等)或 自定义注释 的属性。
值桥实现起来相对简单:在最简单的形式中,它归结为将值从属性类型转换为索引字段类型。由于与 @*Field 注释的集成,几个功能是免费提供的
但是,由于这些功能,值桥会受到一些限制,而这些限制在 属性桥 中不存在,例如
-
值桥只允许一对一映射:一个属性对应一个索引字段。单个值桥不能填充多个索引字段。
-
**值桥在应用于可变类型时将无法正常工作**。预计值桥将应用于“原子”数据,例如
LocalDate;如果它应用于实体,例如从其属性中提取数据,Hibernate Search 将不知道哪些属性被使用,并且将无法 检测到这些属性更改时需要重新索引。
下面是一个自定义值桥的示例,该桥将自定义 ISBN 类型转换为其字符串表示形式以对其进行索引
ValueBridgepublic class ISBNValueBridge implements ValueBridge<ISBN, String> { (1)
@Override
public String toIndexedValue(ISBN value, ValueBridgeToIndexedValueContext context) { (2)
return value == null ? null : value.getStringValue();
}
}| 1 | 该桥必须实现 ValueBridge 接口。必须提供两个泛型类型参数:第一个是属性值的类型(实体模型中的值),第二个是索引字段的类型(文档模型中的值)。 |
| 2 | toIndexedValue 方法是唯一必须实现的方法:所有其他方法都是可选的。它以属性值和上下文对象作为参数,并期望返回相应的索引字段值。它在索引时被调用,但也用于搜索 DSL 必须转换 的参数时。 |
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
@Convert(converter = ISBNAttributeConverter.class) (1)
@KeywordField( (2)
valueBridge = @ValueBridgeRef(type = ISBNValueBridge.class), (3)
normalizer = "isbn" (4)
)
private ISBN isbn;
// Getters and setters
// ...
}| 1 | 这与值桥无关,但对于 Hibernate ORM 正确将数据存储到数据库中是必需的。 |
| 2 | 将属性映射到索引字段。 |
| 3 | 指示 Hibernate Search 使用我们的自定义值桥。在 CDI/Spring bean 的情况下,也可以通过其名称引用该桥。 |
| 4 | 像往常一样自定义字段。 |
以下是以 Elasticsearch 后端为例的索引文档的示例
{
"isbn": "978-0-58-600835-5"
}上面的示例只是一个最小实现。自定义值桥可以做更多
-
它可以 将投影结果转换回属性类型;
-
它可以 解析传递给
indexNullAs的值; -
…
有关更多信息,请参阅下一节。
12.2.2. 类型解析
默认情况下,值桥的属性类型和索引字段类型是自动确定的,使用反射来提取 ValueBridge 接口的泛型类型参数:第一个参数是属性类型,第二个参数是索引字段类型。
例如,在 public class MyBridge implements ValueBridge<ISBN, String> 中,属性类型解析为 ISBN,索引字段类型解析为 String:该桥将应用于类型为 ISBN 的属性,并将填充类型为 String 的索引字段。
使用反射自动解析类型会导致一些限制。特别是,这意味着泛型类型参数不能是任何东西;一般来说,您应该坚持使用文字类型(MyBridge implements ValueBridge<ISBN, String>),并避免泛型类型参数和通配符(MyBridge<T> implements ValueBridge<List<T>, T>)。
如果您需要更复杂的类型,您可以绕过自动解析,并使用 ValueBinder 显式指定类型。
12.2.3. 在其他 @*Field 注释中使用值桥
为了将自定义值桥与诸如 @FullTextField 之类的专用注释一起使用,该桥必须声明兼容的索引字段类型。
例如
-
@FullTextField和@KeywordField要求索引字段类型为String(ValueBridge<Whatever, String>); -
@ScaledNumberField要求索引字段类型为BigDecimal(ValueBridge<Whatever, BigDecimal>)或BigInteger(ValueBridge<Whatever, BigInteger>)。
有关每个注释的具体约束,请参阅 可用字段注释。
尝试使用声明不兼容类型的桥将在引导时触发异常。
12.2.4. 使用 fromIndexedValue() 支持投影
默认情况下,任何尝试使用自定义桥对字段进行投影都将导致异常,因为 Hibernate Search 不知道如何将从索引中获得的投影值转换回属性类型。
可以 显式禁用转换 以从索引中获取原始值,但解决问题的另一种方法是简单地在自定义桥中实现 fromIndexedValue。此方法将在需要转换投影值时调用。
fromIndexedValue 以转换投影值public class ISBNValueBridge implements ValueBridge<ISBN, String> {
@Override
public String toIndexedValue(ISBN value, ValueBridgeToIndexedValueContext context) {
return value == null ? null : value.getStringValue();
}
@Override
public ISBN fromIndexedValue(String value, ValueBridgeFromIndexedValueContext context) {
return value == null ? null : ISBN.parse( value ); (1)
}
}| 1 | 根据需要实现 fromIndexedValue。 |
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
@Convert(converter = ISBNAttributeConverter.class) (1)
@KeywordField( (2)
valueBridge = @ValueBridgeRef(type = ISBNValueBridge.class), (3)
normalizer = "isbn",
projectable = Projectable.YES (4)
)
private ISBN isbn;
// Getters and setters
// ...
}| 1 | 这与值桥无关,但对于 Hibernate ORM 正确将数据存储到数据库中是必需的。 |
| 2 | 将属性映射到索引字段。 |
| 3 | 指示 Hibernate Search 使用我们的自定义值桥。 |
| 4 | 不要忘记将字段配置为可投影的。 |
12.2.5. 使用 parse() 将字符串表示形式解析为索引字段类型
默认情况下,当使用自定义桥时,一些 Hibernate Search 功能(如指定 @*Field 注释的 indexNullAs 属性,或在使用本地后端(例如 Lucene)的查询字符串谓词(simpleQueryString()/queryString())中使用具有自定义桥的字段,或在搜索 DSL 中使用 ValueModel.STRING)将无法开箱即用。
为了使其正常工作,该桥需要实现 parse 方法,以便 Hibernate Search 可以将字符串表示形式转换为索引字段的正确类型的值。
parsepublic class ISBNValueBridge implements ValueBridge<ISBN, String> {
@Override
public String toIndexedValue(ISBN value, ValueBridgeToIndexedValueContext context) {
return value == null ? null : value.getStringValue();
}
@Override
public String parse(String value) {
// Just check the string format and return the string
return ISBN.parse( value ).getStringValue(); (1)
}
}| 1 | 根据需要实现 parse。该桥可能会针对无效字符串抛出异常。 |
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
@Convert(converter = ISBNAttributeConverter.class) (1)
@KeywordField( (2)
valueBridge = @ValueBridgeRef(type = ISBNValueBridge.class), (3)
normalizer = "isbn",
indexNullAs = "000-0-00-000000-0" (4)
)
private ISBN isbn;
// Getters and setters
// ...
}| 1 | 这与值桥无关,但对于 Hibernate ORM 正确将数据存储到数据库中是必需的。 |
| 2 | 将属性映射到索引字段。 |
| 3 | 指示 Hibernate Search 使用我们的自定义值桥。 |
| 4 | 将 indexNullAs 设置为有效值。 |
List<Book> result = searchSession.search( Book.class )
.where( f -> f.queryString().field( "isbn" )
.matching( "978-0-13-468599-1" ) ) (1)
.fetchHits( 20 );| 1 | 在查询字符串谓词中使用 ISBN 的字符串表示形式。 |
12.2.6. 使用 format() 将值格式化为字符串
默认情况下,当使用自定义桥时,请求字段投影的 ValueModel.STRING 将使用简单的 toString() 调用。
为了自定义格式,该桥需要实现 format 方法,以便 Hibernate Search 可以将索引字段转换为所需的字符串表示形式。
formatpublic class ISBNValueBridge implements ValueBridge<ISBN, Long> {
// Implement mandatory toDocumentIdentifier/fromDocumentIdentifier ...
// ...
@Override
public String format(Long value) { (1)
return value == null
? null
: value.toString()
.replaceAll( "(\\d{3})(\\d)(\\d{2})(\\d{6})(\\d)", "$1-$2-$3-$4-$5" );
}
}| 1 | 根据需要实现 format。该桥可能会针对无效值抛出异常。 |
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
@Convert(converter = ISBNAttributeConverter.class) (1)
@GenericField( (2)
valueBridge = @ValueBridgeRef(type = ISBNValueBridge.class), (3)
projectable = Projectable.YES (4)
)
private ISBN isbn;
// Getters and setters
// ...
}| 1 | 这与值桥无关,但对于 Hibernate ORM 正确将数据存储到数据库中是必需的。 |
| 2 | 将属性映射到索引字段。 |
| 3 | 指示 Hibernate Search 使用我们的自定义值桥。 |
| 4 | 将字段配置为可投影的。 |
List<String> result = searchSession.search( Book.class )
.select( f -> f.field( "isbn", String.class, ValueModel.STRING ) ) (1)
.where( f -> f.matchAll() )
.fetchHits( 20 );| 1 | 在请求字段投影时使用字符串表示形式。 |
12.2.7. 使用 isCompatibleWith() 跨索引的兼容性
值桥参与索引,也参与各种搜索 DSL,以将传递给 DSL 的值转换为后端将理解的索引字段值。
在创建针对多个索引中单个字段的谓词时,Hibernate Search 将有多个桥可供选择:每个索引一个。由于只能创建一个带有单个值的谓词,Hibernate Search 需要选择一个桥。默认情况下,当自定义桥分配给字段时,Hibernate Search 将抛出异常,因为它无法决定选择哪个桥。
如果在所有索引中分配给该字段的桥都生成相同的结果,则可以通过实现 isCompatibleWith 来指示 Hibernate Search 任何桥都可以。
此方法接受另一个桥作为参数,如果该桥可以预期始终表现得与 this 相同,则返回 true。
isCompatibleWith 以支持多索引搜索public class ISBNValueBridge implements ValueBridge<ISBN, String> {
@Override
public String toIndexedValue(ISBN value, ValueBridgeToIndexedValueContext context) {
return value == null ? null : value.getStringValue();
}
@Override
public boolean isCompatibleWith(ValueBridge<?, ?> other) { (1)
return getClass().equals( other.getClass() );
}
}| 1 | 根据需要实现 isCompatibleWith。这里我们只认为同一个类的任何实例都是兼容的。 |
12.2.8. 使用 ValueBinder 更精细地配置桥
为了更精细地配置桥,可以实现一个将在引导时执行的值绑定器。该绑定器将能够特别定义自定义索引字段类型。
ValueBinderpublic class ISBNValueBinder implements ValueBinder { (1)
@Override
public void bind(ValueBindingContext<?> context) { (2)
context.bridge( (3)
ISBN.class, (4)
new ISBNValueBridge(), (5)
context.typeFactory() (6)
.asString() (7)
.normalizer( "isbn" ) (8)
);
}
private static class ISBNValueBridge implements ValueBridge<ISBN, String> {
@Override
public String toIndexedValue(ISBN value, ValueBridgeToIndexedValueContext context) {
return value == null ? null : value.getStringValue(); (9)
}
}
}| 1 | 该绑定器必须实现 ValueBinder 接口。 |
| 2 | 实现 bind 方法。 |
| 3 | 调用 context.bridge(…) 以定义要使用的值桥。 |
| 4 | 传递预期的属性值的类型。 |
| 5 | 传递值桥实例。 |
| 6 | 使用上下文的类型工厂创建一个索引字段类型。 |
| 7 | 使用 as*() 方法为索引字段选择一个基本类型。 |
| 8 | 根据需要配置类型。此配置将设置应用于使用此桥的任何类型的默认值,但它们可以被覆盖。类型配置类似于各种 @*Field 注释中找到的属性。有关更多信息,请参阅 定义索引字段类型。 |
| 9 | 值桥仍然必须实现。 这里桥梁类嵌套在绑定程序类中,因为这样更方便,但您可以自由地根据需要实现它:作为 lambda 表达式,在单独的 Java 文件中等等。 |
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
@Convert(converter = ISBNAttributeConverter.class) (1)
@KeywordField( (2)
valueBinder = @ValueBinderRef(type = ISBNValueBinder.class), (3)
sortable = Sortable.YES (4)
)
private ISBN isbn;
// Getters and setters
// ...
}| 1 | 这与值桥无关,但对于 Hibernate ORM 正确将数据存储到数据库中是必需的。 |
| 2 | 将属性映射到索引字段。 |
| 3 | 指示 Hibernate Search 使用我们的自定义值绑定器。注意使用 valueBinder 而不是 valueBridge。在 CDI/Spring bean 的情况下,也可以通过其名称引用绑定器。 |
| 4 | 像往常一样自定义字段。使用注释属性设置的配置优先于值绑定器设置的索引字段类型配置。例如,在这种情况下,即使绑定器没有将字段定义为可排序的,该字段也将是可排序的。 |
|
在将值绑定器与专用 例如, 这些限制类似于直接分配值桥时的限制;请参阅 在其他 |
12.2.9. 传递参数
值桥通常与内置的 @*Field 注解 一起使用,该注解已经接受参数来配置字段名称、字段是否可排序等。
但是,这些参数不会传递给值桥或值绑定器。有两种方法可以将参数传递给值桥。
-
一种方法(主要)限于字符串参数,但实现起来很简单。
-
另一种方法可以允许任何类型的参数,但需要您声明自己的注解。
简单字符串参数
您可以为 @ValueBinderRef 注解定义字符串参数,然后在绑定器中使用它们。
@ValueBinderRef 注解将参数传递给 ValueBridgepublic class BooleanAsStringBridge implements ValueBridge<Boolean, String> { (1)
private final String trueAsString;
private final String falseAsString;
public BooleanAsStringBridge(String trueAsString, String falseAsString) { (2)
this.trueAsString = trueAsString;
this.falseAsString = falseAsString;
}
@Override
public String toIndexedValue(Boolean value, ValueBridgeToIndexedValueContext context) {
if ( value == null ) {
return null;
}
return value ? trueAsString : falseAsString;
}
}| 1 | 实现一个桥接,该桥接不直接索引布尔值,而是将它们作为字符串索引。 |
| 2 | 该桥接在其构造函数中接受两个参数:表示 true 的字符串和表示 false 的字符串。 |
public class BooleanAsStringBinder implements ValueBinder {
@Override
public void bind(ValueBindingContext<?> context) {
String trueAsString = context.params().get( "trueAsString", String.class ); (1)
String falseAsString = context.params().get( "falseAsString", String.class );
context.bridge( Boolean.class, (2)
new BooleanAsStringBridge( trueAsString, falseAsString ) );
}
}| 1 | 使用绑定上下文获取参数值。 如果未定义参数,则 |
| 2 | 将它们作为参数传递给桥接构造函数。 |
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
@GenericField(valueBinder = @ValueBinderRef(type = BooleanAsStringBinder.class, (1)
params = {
@Param(name = "trueAsString", value = "yes"),
@Param(name = "falseAsString", value = "no")
}))
private boolean published;
@ElementCollection
@GenericField(valueBinder = @ValueBinderRef(type = BooleanAsStringBinder.class, (2)
params = {
@Param(name = "trueAsString", value = "passed"),
@Param(name = "falseAsString", value = "failed")
}), name = "censorshipAssessments_allYears")
private Map<Year, Boolean> censorshipAssessments = new HashMap<>();
// Getters and setters
// ...
}| 1 | 定义要在属性上使用的绑定器,设置 fieldName 参数。 |
| 2 | 因为我们使用的是值桥接,所以注解可以透明地应用于容器。在这里,桥接将依次应用于映射中的每个值。 |
使用自定义注解的参数
您可以通过定义具有属性的 自定义注解 将任何类型的参数传递给桥接。
ValueBridgepublic class BooleanAsStringBridge implements ValueBridge<Boolean, String> { (1)
private final String trueAsString;
private final String falseAsString;
public BooleanAsStringBridge(String trueAsString, String falseAsString) { (2)
this.trueAsString = trueAsString;
this.falseAsString = falseAsString;
}
@Override
public String toIndexedValue(Boolean value, ValueBridgeToIndexedValueContext context) {
if ( value == null ) {
return null;
}
return value ? trueAsString : falseAsString;
}
}| 1 | 实现一个桥接,该桥接不直接索引布尔值,而是将它们作为字符串索引。 |
| 2 | 该桥接在其构造函数中接受两个参数:表示 true 的字符串和表示 false 的字符串。 |
@Retention(RetentionPolicy.RUNTIME) (1)
@Target({ ElementType.METHOD, ElementType.FIELD }) (2)
@PropertyMapping(processor = @PropertyMappingAnnotationProcessorRef( (3)
type = BooleanAsStringField.Processor.class
))
@Documented (4)
@Repeatable(BooleanAsStringField.List.class) (5)
public @interface BooleanAsStringField {
String trueAsString() default "true"; (6)
String falseAsString() default "false";
String name() default ""; (7)
ContainerExtraction extraction() default @ContainerExtraction(); (7)
@Documented
@Target({ ElementType.METHOD, ElementType.FIELD })
@Retention(RetentionPolicy.RUNTIME)
@interface List {
BooleanAsStringField[] value();
}
class Processor (8)
implements PropertyMappingAnnotationProcessor<BooleanAsStringField> { (9)
@Override
public void process(PropertyMappingStep mapping, BooleanAsStringField annotation,
PropertyMappingAnnotationProcessorContext context) {
BooleanAsStringBridge bridge = new BooleanAsStringBridge( (10)
annotation.trueAsString(), annotation.falseAsString()
);
mapping.genericField( (11)
annotation.name().isEmpty() ? null : annotation.name()
)
.valueBridge( bridge ) (12)
.extractors( (13)
context.toContainerExtractorPath( annotation.extraction() )
);
}
}
}| 1 | 定义一个具有 RUNTIME 保留策略的注解。任何其他保留策略都将导致 Hibernate Search 忽略该注解。 |
| 2 | 由于我们正在定义一个值桥接,因此允许该注解将目标设置为方法(getter)或字段。 |
| 3 | 将此注解标记为属性映射,并指示 Hibernate Search 在找到此注解时应用给定的处理器。也可以通过其 CDI/Spring bean 名称来引用处理器。 |
| 4 | 可选地,将注解标记为已记录,以便将其包含在实体的 javadoc 中。 |
| 5 | 可以选择将注解标记为可重复,以便能够在同一属性上声明多个字段。 |
| 6 | 定义自定义属性来配置值桥接。在这里,我们定义了两个字符串,桥接应该使用它们来表示布尔值 true 和 false。 |
| 7 | 由于我们将使用自定义注解,而不是内置的 @*Field 注解,因此需要在此处声明对该桥接有意义的标准参数。 |
| 8 | 这里处理器类嵌套在注解类中,因为这样更方便,但您可以自由地在单独的 Java 文件中实现它。 |
| 9 | 处理器必须实现 PropertyMappingAnnotationProcessor 接口,并设置其泛型类型参数为相应注解的类型。 |
| 10 | 在 process 方法中,实例化桥接并将注解属性作为构造函数参数传递。 |
| 11 | 使用配置的名称(如果提供)声明字段。 |
| 12 | 将我们的桥接分配给字段。或者,我们可以使用 valueBinder() 方法分配值绑定器。 |
| 13 | 配置其余的标准参数。请注意,传递给 process 方法的 context 对象公开了实用程序方法,用于将标准 Hibernate Search 注解转换为可以传递给映射的内容(这里,@ContainerExtraction 被转换为容器提取器路径)。 |
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
@BooleanAsStringField(trueAsString = "yes", falseAsString = "no") (1)
private boolean published;
@ElementCollection
@BooleanAsStringField( (2)
name = "censorshipAssessments_allYears",
trueAsString = "passed", falseAsString = "failed"
)
private Map<Year, Boolean> censorshipAssessments = new HashMap<>();
// Getters and setters
// ...
}| 1 | 使用自定义注解应用桥接,设置参数。 |
| 2 | 因为我们使用的是值桥接,所以注解可以透明地应用于容器。在这里,桥接将依次应用于映射中的每个值。 |
12.2.10. 从桥接访问 ORM 会话或会话工厂
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
传递给桥接方法的上下文可用于检索 Hibernate ORM 会话或会话工厂。
ValueBridge 检索 ORM 会话或会话工厂public class MyDataValueBridge implements ValueBridge<MyData, String> {
@Override
public String toIndexedValue(MyData value, ValueBridgeToIndexedValueContext context) {
SessionFactory sessionFactory = context.extension( HibernateOrmExtension.get() ) (1)
.sessionFactory(); (2)
// ... do something with the factory ...
}
@Override
public MyData fromIndexedValue(String value, ValueBridgeFromIndexedValueContext context) {
Session session = context.extension( HibernateOrmExtension.get() ) (3)
.session(); (4)
// ... do something with the session ...
}
}| 1 | 应用一个扩展到上下文以访问特定于 Hibernate ORM 的内容。 |
| 2 | 从扩展上下文检索 SessionFactory。Session 在这里不可用。 |
| 3 | 应用一个扩展到上下文以访问特定于 Hibernate ORM 的内容。 |
| 4 | 从扩展上下文检索 Session。 |
12.2.11. 将 Bean 注入值桥接或值绑定器
使用 兼容框架,Hibernate Search 支持将 Bean 注入 ValueBridge 和 ValueBinder。
这仅适用于通过 Hibernate Search 的 Bean 解析 实例化的 Bean。一般来说,如果您需要在某个时刻显式调用 new MyBridge(),则该桥接不会被自动注入。 |
传递给值绑定器的 bind 方法的上下文还公开了 beanResolver() 方法,以访问 Bean 解析器并显式实例化 Bean。
有关详细信息,请参阅 Bean 注入。
12.2.12. 编程映射
您也可以通过 编程映射 应用值桥接。只需传递桥接的实例。
.valueBridge(…) 应用 ValueBridgeTypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "isbn" )
.keywordField().valueBridge( new ISBNValueBridge() );同样,您可以传递绑定器实例。您可以通过绑定器的构造函数或 setter 传递参数。
.valueBinder(…) 应用 ValueBinderTypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "isbn" )
.genericField()
.valueBinder( new ISBNValueBinder() )
.sortable( Sortable.YES );12.2.13. 孵化功能
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
传递给值绑定器的 bind 方法的上下文公开了 bridgedElement() 方法,该方法允许访问有关要绑定的值的元数据,特别是其类型。
有关更多信息,请参阅 javadoc。
12.3. 属性桥接
12.3.1. 基础知识
与值桥接相比,属性桥接的实现更复杂,但涵盖了更广泛的用例。
-
属性桥接可以将单个属性映射到多个索引字段。
-
属性桥接可以正确地应用于可变类型,前提是它已正确实现。
但是,由于其相当灵活的性质,属性桥接不会透明地提供与值桥接免费提供的功能。它们可以得到支持,但必须手动实现。这尤其包括容器提取器,它们不能与属性桥接结合使用:属性桥接必须显式提取容器值。
实现属性桥接需要两个组件。
-
PropertyBinder的自定义实现,用于在引导时将桥接绑定到属性。这涉及声明将使用的属性部分、声明将填充的索引字段及其类型以及实例化属性桥接。 -
PropertyBridge的自定义实现,用于在运行时执行转换。这涉及从属性中提取数据、在必要时进行转换以及将其推送到索引字段。
以下是一个将发票行项列表映射到几个汇总发票的字段的自定义属性桥接的示例。
PropertyBridgepublic class InvoiceLineItemsSummaryBinder implements PropertyBinder { (1)
@Override
public void bind(PropertyBindingContext context) { (2)
context.dependencies() (3)
.use( "category" )
.use( "amount" );
IndexSchemaObjectField summaryField = context.indexSchemaElement() (4)
.objectField( "summary" );
IndexFieldType<BigDecimal> amountFieldType = context.typeFactory() (5)
.asBigDecimal().decimalScale( 2 ).toIndexFieldType();
context.bridge( (6)
List.class, (7)
new Bridge( (8)
summaryField.toReference(), (9)
summaryField.field( "total", amountFieldType ).toReference(), (10)
summaryField.field( "books", amountFieldType ).toReference(), (10)
summaryField.field( "shipping", amountFieldType ).toReference() (10)
)
);
}
// ... class continues below| 1 | 绑定器必须实现 PropertyBinder 接口。 |
| 2 | 在绑定器中实现 bind 方法。 |
| 3 | 声明桥接的依赖项,即桥接将实际使用的属性值部分。这对于 Hibernate Search 在这些部分被修改时正确触发重新索引是**绝对必要的**。有关声明依赖项的更多信息,请参阅 声明对桥接元素的依赖项。 |
| 4 | 声明由该桥接填充的字段。在本例中,我们正在创建一个 summary 对象字段,该字段将具有多个子字段(见下文)。有关声明索引字段的更多信息,请参阅 声明和写入索引字段。 |
| 5 | 声明子字段的类型。我们将索引货币金额,因此我们将使用带两位小数的 BigDecimal 类型。有关声明索引字段类型的更多信息,请参阅 定义索引字段类型。 |
| 6 | 调用 context.bridge(…) 来定义要使用的属性桥接。 |
| 7 | 传递预期的属性类型。 |
| 8 | 传递属性桥接实例。 |
| 9 | 将对 summary 对象字段的引用传递给桥接。 |
| 10 | 为发票的 total 金额创建一个子字段,为 books 的小计创建一个子字段,为 shipping 的小计创建一个子字段。将对这些字段的引用传递给桥接。 |
// ... class InvoiceLineItemsSummaryBinder (continued)
@SuppressWarnings("rawtypes")
private static class Bridge (1)
implements PropertyBridge<List> { (2)
private final IndexObjectFieldReference summaryField;
private final IndexFieldReference<BigDecimal> totalField;
private final IndexFieldReference<BigDecimal> booksField;
private final IndexFieldReference<BigDecimal> shippingField;
private Bridge(IndexObjectFieldReference summaryField, (3)
IndexFieldReference<BigDecimal> totalField,
IndexFieldReference<BigDecimal> booksField,
IndexFieldReference<BigDecimal> shippingField) {
this.summaryField = summaryField;
this.totalField = totalField;
this.booksField = booksField;
this.shippingField = shippingField;
}
@Override
public void write(DocumentElement target, List bridgedElement, PropertyBridgeWriteContext context) { (4)
@SuppressWarnings("unchecked")
List<InvoiceLineItem> lineItems = (List<InvoiceLineItem>) bridgedElement;
BigDecimal total = BigDecimal.ZERO;
BigDecimal books = BigDecimal.ZERO;
BigDecimal shipping = BigDecimal.ZERO;
for ( InvoiceLineItem lineItem : lineItems ) { (5)
BigDecimal amount = lineItem.getAmount();
total = total.add( amount );
switch ( lineItem.getCategory() ) {
case BOOK:
books = books.add( amount );
break;
case SHIPPING:
shipping = shipping.add( amount );
break;
}
}
DocumentElement summary = target.addObject( this.summaryField ); (6)
summary.addValue( this.totalField, total ); (7)
summary.addValue( this.booksField, books ); (7)
summary.addValue( this.shippingField, shipping ); (7)
}
}
}| 1 | 这里桥梁类嵌套在绑定程序类中,因为这样更方便,但您可以自由地根据需要实现它:作为 lambda 表达式,在单独的 Java 文件中等等。 |
| 2 | 桥接必须实现 PropertyBridge 接口。必须提供一个泛型类型参数:属性的类型,即“桥接元素”的类型。 |
| 3 | 桥接存储对字段的引用,它在索引时需要这些引用。 |
| 4 | 在桥接中实现 write 方法。此方法在索引时调用。 |
| 5 | 从桥接元素中提取数据,并选择性地对其进行转换。 |
| 6 | 向 summary 对象字段添加一个对象。请注意,summary 字段是在根目录中声明的,因此我们直接在 target 参数上调用 addObject。 |
| 7 | 向每个 summary.total、summary.books 和 summary.shipping 字段添加一个值。请注意,这些字段被声明为 summary 的子字段,因此我们对 summaryValue 而不是 target 调用 addValue。 |
@Entity
@Indexed
public class Invoice {
@Id
@GeneratedValue
private Integer id;
@ElementCollection
@OrderColumn
@PropertyBinding(binder = @PropertyBinderRef(type = InvoiceLineItemsSummaryBinder.class)) (1)
private List<InvoiceLineItem> lineItems = new ArrayList<>();
// Getters and setters
// ...
}| 1 | 使用 @PropertyBinding 注解应用桥接。 |
以下是以 Elasticsearch 后端为例的索引文档的示例
{
"summary": {
"total": 38.96,
"books": 30.97,
"shipping": 7.99
}
}12.3.2. 传递参数
有两种方法可以将参数传递给属性桥接。
-
一种方法(主要)限于字符串参数,但实现起来很简单。
-
另一种方法可以允许任何类型的参数,但需要您声明自己的注解。
简单字符串参数
您可以将字符串参数传递给 @PropertyBinderRef 注解,然后在绑定器中使用它们。
@PropertyBinderRef 注解将参数传递给 PropertyBinderpublic class InvoiceLineItemsSummaryBinder implements PropertyBinder {
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
.use( "category" )
.use( "amount" );
String fieldName = context.params().get( "fieldName", String.class ); (1)
IndexSchemaObjectField summaryField = context.indexSchemaElement()
.objectField( fieldName ); (2)
IndexFieldType<BigDecimal> amountFieldType = context.typeFactory()
.asBigDecimal().decimalScale( 2 ).toIndexFieldType();
context.bridge( List.class, new Bridge(
summaryField.toReference(),
summaryField.field( "total", amountFieldType ).toReference(),
summaryField.field( "books", amountFieldType ).toReference(),
summaryField.field( "shipping", amountFieldType ).toReference()
) );
}
@SuppressWarnings("rawtypes")
private static class Bridge implements PropertyBridge<List> {
/* ... same implementation as before ... */
}
}| 1 | 使用绑定上下文获取参数值。 如果未定义参数,则 |
| 2 | 在 bind 方法中,使用参数的值。这里使用 fieldName 参数来设置字段名称,但我们可以为任何目的传递参数:将字段定义为可排序,定义归一化器,等等。 |
@Entity
@Indexed
public class Invoice {
@Id
@GeneratedValue
private Integer id;
@ElementCollection
@OrderColumn
@PropertyBinding(binder = @PropertyBinderRef( (1)
type = InvoiceLineItemsSummaryBinder.class,
params = @Param(name = "fieldName", value = "itemSummary")))
private List<InvoiceLineItem> lineItems = new ArrayList<>();
// Getters and setters
// ...
}| 1 | 定义要在属性上使用的绑定器,设置 fieldName 参数。 |
使用自定义注解的参数
您可以通过定义具有属性的 自定义注解 将任何类型的参数传递给桥接。
PropertyBinder@Retention(RetentionPolicy.RUNTIME) (1)
@Target({ ElementType.METHOD, ElementType.FIELD }) (2)
@PropertyMapping(processor = @PropertyMappingAnnotationProcessorRef( (3)
type = InvoiceLineItemsSummaryBinding.Processor.class
))
@Documented (4)
public @interface InvoiceLineItemsSummaryBinding {
String fieldName() default ""; (5)
class Processor (6)
implements PropertyMappingAnnotationProcessor<InvoiceLineItemsSummaryBinding> { (7)
@Override
public void process(PropertyMappingStep mapping,
InvoiceLineItemsSummaryBinding annotation,
PropertyMappingAnnotationProcessorContext context) {
InvoiceLineItemsSummaryBinder binder = new InvoiceLineItemsSummaryBinder(); (8)
if ( !annotation.fieldName().isEmpty() ) { (9)
binder.fieldName( annotation.fieldName() );
}
mapping.binder( binder ); (10)
}
}
}| 1 | 定义一个具有 RUNTIME 保留策略的注解。任何其他保留策略都将导致 Hibernate Search 忽略该注解。 |
| 2 | 由于我们正在定义一个属性桥接,因此允许该注解将目标设置为方法(getter)或字段。 |
| 3 | 将此注解标记为属性映射,并指示 Hibernate Search 在找到此注解时应用给定的处理器。也可以通过其 CDI/Spring bean 名称来引用处理器。 |
| 4 | 可选地,将注解标记为已记录,以便将其包含在实体的 javadoc 中。 |
| 5 | 定义一个类型为 String 的属性来指定字段名称。 |
| 6 | 这里处理器类嵌套在注解类中,因为这样更方便,但您可以自由地在单独的 Java 文件中实现它。 |
| 7 | 处理器必须实现 PropertyMappingAnnotationProcessor 接口,并设置其泛型类型参数为相应注解的类型。 |
| 8 | 在注解处理器中,实例化绑定器。 |
| 9 | 处理注解属性并将数据传递给绑定器。 这里我们使用的是 setter,但通过构造函数传递数据也可以。 |
| 10 | 将绑定器应用于属性。 |
public class InvoiceLineItemsSummaryBinder implements PropertyBinder {
private String fieldName = "summary";
public InvoiceLineItemsSummaryBinder fieldName(String fieldName) { (1)
this.fieldName = fieldName;
return this;
}
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
.use( "category" )
.use( "amount" );
IndexSchemaObjectField summaryField = context.indexSchemaElement()
.objectField( this.fieldName ); (2)
IndexFieldType<BigDecimal> amountFieldType = context.typeFactory()
.asBigDecimal().decimalScale( 2 ).toIndexFieldType();
context.bridge( List.class, new Bridge(
summaryField.toReference(),
summaryField.field( "total", amountFieldType ).toReference(),
summaryField.field( "books", amountFieldType ).toReference(),
summaryField.field( "shipping", amountFieldType ).toReference()
) );
}
@SuppressWarnings("rawtypes")
private static class Bridge implements PropertyBridge<List> {
/* ... same implementation as before ... */
}
}| 1 | 在绑定器中实现 setter。或者,我们可以公开一个参数化的构造函数。 |
| 2 | 在 bind 方法中,使用参数的值。这里使用 fieldName 参数来设置字段名称,但我们可以为任何目的传递参数:将字段定义为可排序,定义归一化器,等等。 |
@Entity
@Indexed
public class Invoice {
@Id
@GeneratedValue
private Integer id;
@ElementCollection
@OrderColumn
@InvoiceLineItemsSummaryBinding( (1)
fieldName = "itemSummary"
)
private List<InvoiceLineItem> lineItems = new ArrayList<>();
// Getters and setters
// ...
}| 1 | 使用自定义注解应用桥接,设置 fieldName 参数。 |
12.3.3. 从桥接访问 ORM 会话
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
传递给桥接方法的上下文可用于检索 Hibernate ORM 会话。
PropertyBridge 检索 ORM 会话private static class Bridge implements PropertyBridge<Object> {
private final IndexFieldReference<String> field;
private Bridge(IndexFieldReference<String> field) {
this.field = field;
}
@Override
public void write(DocumentElement target, Object bridgedElement, PropertyBridgeWriteContext context) {
Session session = context.extension( HibernateOrmExtension.get() ) (1)
.session(); (2)
// ... do something with the session ...
}
}| 1 | 应用一个扩展到上下文以访问特定于 Hibernate ORM 的内容。 |
| 2 | 从扩展上下文检索 Session。 |
12.3.4. 将 Bean 注入绑定器
使用 兼容框架,Hibernate Search 支持将 Bean 注入
-
如果您使用自定义注解,则使用
PropertyMappingAnnotationProcessor。 -
如果您使用
@PropertyBinding注解,则使用PropertyBinder。
这仅适用于通过 Hibernate Search 的bean 解析实例化的 bean。作为经验法则,如果您需要在某个时刻显式调用new MyBinder(),则绑定器不会自动注入。 |
传递给属性绑定器bind方法的上下文还公开了一个beanResolver()方法,用于访问 bean 解析器并显式实例化 bean。
有关详细信息,请参阅 Bean 注入。
12.3.5. 编程映射
您也可以通过编程映射应用属性桥。只需传递绑定器的实例。您可以通过绑定器的构造函数或通过 setter 传递参数。
.binder(…) 应用PropertyBinderTypeMappingStep invoiceMapping = mapping.type( Invoice.class );
invoiceMapping.indexed();
invoiceMapping.property( "lineItems" )
.binder( new InvoiceLineItemsSummaryBinder().fieldName( "itemSummary" ) );12.3.6. 孵化功能
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
传递给属性绑定器bind方法的上下文公开了一个bridgedElement()方法,它可以访问有关正在绑定的属性的元数据。
元数据可用于详细检查属性
-
获取属性的名称。
-
检查属性的类型。
-
获取属性的访问器。
-
检测带有标记的属性。标记由带有
@MarkerBinding元注解的特定注解应用。
有关更多信息,请参阅 javadoc。
以下是如何使用此元数据的最简单示例,获取属性名称并将其用作字段名称。
PropertyBinder 中使用正在绑定的属性作为字段名称public class InvoiceLineItemsSummaryBinder implements PropertyBinder {
@Override
@SuppressWarnings("uncheked")
public void bind(PropertyBindingContext context) {
context.dependencies()
.use( "category" )
.use( "amount" );
PojoModelProperty bridgedElement = context.bridgedElement(); (1)
IndexSchemaObjectField summaryField = context.indexSchemaElement()
.objectField( bridgedElement.name() ); (2)
IndexFieldType<BigDecimal> amountFieldType = context.typeFactory()
.asBigDecimal().decimalScale( 2 ).toIndexFieldType();
context.bridge( List.class, new Bridge(
summaryField.toReference(),
summaryField.field( "total", amountFieldType ).toReference(),
summaryField.field( "books", amountFieldType ).toReference(),
summaryField.field( "shipping", amountFieldType ).toReference()
) );
}
@SuppressWarnings("rawtypes")
private static class Bridge implements PropertyBridge<List> {
/* ... same implementation as before ... */
}
}| 1 | 使用绑定上下文获取桥接元素。 |
| 2 | 使用属性的名称作为新声明的索引字段的名称。 |
@Entity
@Indexed
public class Invoice {
@Id
@GeneratedValue
private Integer id;
@ElementCollection
@OrderColumn
@PropertyBinding(binder = @PropertyBinderRef( (1)
type = InvoiceLineItemsSummaryBinder.class
))
private List<InvoiceLineItem> lineItems = new ArrayList<>();
// Getters and setters
// ...
}| 1 | 使用 @PropertyBinding 注解应用桥接。 |
以下是以 Elasticsearch 后端为例的索引文档的示例
{
"lineItems": {
"total": 38.96,
"books": 30.97,
"shipping": 7.99
}
}12.4. 类型桥
12.4.1. 基础知识
类型桥是一个可插拔组件,它实现将整个类型映射到一个或多个索引字段。它通过@TypeBinding 注解或自定义注解应用于类型。
类型桥在核心原理和实现方式上与属性桥非常相似。唯一的(明显的)区别是属性桥应用于属性(字段或 getter),而类型桥应用于类型(类或接口)。这会导致 API 对类型桥公开的方式略有不同。
实现类型桥需要两个组件
-
TypeBinder的自定义实现,用于在引导时将桥绑定到类型。这涉及声明将使用的类型的属性、声明将填充的索引字段及其类型,以及实例化类型桥。 -
TypeBridge的自定义实现,用于在运行时执行转换。这涉及从类型的实例中提取数据,根据需要转换数据,并将数据推送到索引字段。
以下是一个自定义类型桥的示例,它将Author 类的两个属性firstName 和lastName 映射到单个fullName 字段。
TypeBridgepublic class FullNameBinder implements TypeBinder { (1)
@Override
public void bind(TypeBindingContext context) { (2)
context.dependencies() (3)
.use( "firstName" )
.use( "lastName" );
IndexFieldReference<String> fullNameField = context.indexSchemaElement() (4)
.field( "fullName", f -> f.asString().analyzer( "name" ) ) (5)
.toReference();
context.bridge( (6)
Author.class, (7)
new Bridge( (8)
fullNameField (9)
)
);
}
// ... class continues below| 1 | 绑定器必须实现TypeBinder 接口。 |
| 2 | 在绑定器中实现 bind 方法。 |
| 3 | 声明桥的依赖关系,即桥将实际使用的类型实例的各个部分。这对于 Hibernate Search 在这些部分修改时正确触发重新索引是**绝对必要的**。有关声明依赖关系的更多信息,请参阅 声明对桥接元素的依赖关系。 |
| 4 | 声明将由此桥填充的字段。在本例中,我们正在创建一个名为fullName 的单个字符串字段。可以声明多个索引字段。有关声明索引字段的更多信息,请参阅 声明和写入索引字段。 |
| 5 | 声明字段的类型。由于我们正在索引全名,因此我们将使用具有name 分析器(单独定义,请参阅 分析)的String 类型。有关声明索引字段类型的更多信息,请参阅 定义索引字段类型。 |
| 6 | 调用context.bridge(…) 以定义要使用的类型桥。 |
| 7 | 传递实体的预期类型。 |
| 8 | 传递类型桥实例。 |
| 9 | 将对fullName 字段的引用传递给桥。 |
// ... class FullNameBinder (continued)
private static class Bridge (1)
implements TypeBridge<Author> { (2)
private final IndexFieldReference<String> fullNameField;
private Bridge(IndexFieldReference<String> fullNameField) { (3)
this.fullNameField = fullNameField;
}
@Override
public void write(
DocumentElement target,
Author author,
TypeBridgeWriteContext context) { (4)
String fullName = author.getLastName() + " " + author.getFirstName(); (5)
target.addValue( this.fullNameField, fullName ); (6)
}
}
}| 1 | 这里桥梁类嵌套在绑定程序类中,因为这样更方便,但您可以自由地根据需要实现它:作为 lambda 表达式,在单独的 Java 文件中等等。 |
| 2 | 桥必须实现TypeBridge 接口。必须提供一个泛型类型参数:类型“桥接元素”。 |
| 3 | 桥接存储对字段的引用,它在索引时需要这些引用。 |
| 4 | 在桥接中实现 write 方法。此方法在索引时调用。 |
| 5 | 从桥接元素中提取数据,并选择性地对其进行转换。 |
| 6 | 设置fullName 字段的值。请注意,fullName 字段是在根级别声明的,因此我们直接在target 参数上调用addValue。 |
@Entity
@Indexed
@TypeBinding(binder = @TypeBinderRef(type = FullNameBinder.class)) (1)
public class Author {
@Id
@GeneratedValue
private Integer id;
private String firstName;
private String lastName;
@GenericField (2)
private LocalDate birthDate;
// Getters and setters
// ...
}| 1 | 使用@TypeBinding 注解应用桥。 |
| 2 | 仍然可以使用其他注解直接映射属性,只要索引字段名称与类型绑定器中使用的名称不同。但是,firstName 和lastName 属性不需要任何注解:它们已经被桥接处理。 |
以下是以 Elasticsearch 后端为例的索引文档的示例
{
"fullName": "Asimov Isaac"
}12.4.2. 传递参数
有两种方法可以将参数传递给类型桥
-
一种方法(主要)限于字符串参数,但实现起来很简单。
-
另一种方法可以允许任何类型的参数,但需要您声明自己的注解。
简单字符串参数
您可以将字符串参数传递给@TypeBinderRef 注解,然后在绑定器中使用它们
@TypeBinderRef 注解将参数传递给TypeBinderpublic class FullNameBinder implements TypeBinder {
@Override
public void bind(TypeBindingContext context) {
context.dependencies()
.use( "firstName" )
.use( "lastName" );
IndexFieldReference<String> fullNameField = context.indexSchemaElement()
.field( "fullName", f -> f.asString().analyzer( "name" ) )
.toReference();
IndexFieldReference<String> fullNameSortField = null;
String sortField = context.params().get( "sortField", String.class ); (1)
if ( "true".equalsIgnoreCase( sortField ) ) { (2)
fullNameSortField = context.indexSchemaElement()
.field(
"fullName_sort",
f -> f.asString().normalizer( "name" ).sortable( Sortable.YES )
)
.toReference();
}
context.bridge( Author.class, new Bridge(
fullNameField,
fullNameSortField
) );
}
private static class Bridge implements TypeBridge<Author> {
private final IndexFieldReference<String> fullNameField;
private final IndexFieldReference<String> fullNameSortField;
private Bridge(IndexFieldReference<String> fullNameField,
IndexFieldReference<String> fullNameSortField) { (2)
this.fullNameField = fullNameField;
this.fullNameSortField = fullNameSortField;
}
@Override
public void write(
DocumentElement target,
Author author,
TypeBridgeWriteContext context) {
String fullName = author.getLastName() + " " + author.getFirstName();
target.addValue( this.fullNameField, fullName );
if ( this.fullNameSortField != null ) {
target.addValue( this.fullNameSortField, fullName );
}
}
}
}| 1 | 使用绑定上下文获取参数值。 如果未定义参数,则 |
| 2 | 在bind 方法中,使用参数的值。这里使用sortField 参数来决定是否添加另一个可排序字段,但我们可以将参数用于任何目的:定义字段名称、定义规范化器、自定义注解等等。 |
@Entity
@Indexed
@TypeBinding(binder = @TypeBinderRef(type = FullNameBinder.class, (1)
params = @Param(name = "sortField", value = "true")))
public class Author {
@Id
@GeneratedValue
private Integer id;
private String firstName;
private String lastName;
// Getters and setters
// ...
}| 1 | 定义要应用于类型的绑定器,设置sortField 参数。 |
使用自定义注解传递参数
您可以通过定义具有属性的 自定义注解 将任何类型的参数传递给桥接。
TypeBinder@Retention(RetentionPolicy.RUNTIME) (1)
@Target({ ElementType.TYPE }) (2)
@TypeMapping(processor = @TypeMappingAnnotationProcessorRef(type = FullNameBinding.Processor.class)) (3)
@Documented (4)
public @interface FullNameBinding {
boolean sortField() default false; (5)
class Processor (6)
implements TypeMappingAnnotationProcessor<FullNameBinding> { (7)
@Override
public void process(TypeMappingStep mapping, FullNameBinding annotation,
TypeMappingAnnotationProcessorContext context) {
FullNameBinder binder = new FullNameBinder() (8)
.sortField( annotation.sortField() ); (9)
mapping.binder( binder ); (10)
}
}
}| 1 | 定义一个具有 RUNTIME 保留策略的注解。任何其他保留策略都将导致 Hibernate Search 忽略该注解。 |
| 2 | 由于我们正在定义类型桥,因此允许注解针对类型。 |
| 3 | 将此注解标记为类型映射,并指示 Hibernate Search 在找到此注解时应用给定的绑定器。也可以通过名称引用绑定器,如果是 CDI/Spring bean 的情况。 |
| 4 | 可选地,将注解标记为已记录,以便将其包含在实体的 javadoc 中。 |
| 5 | 定义一个类型为boolean 的属性,以指定是否应该添加排序字段。 |
| 6 | 这里处理器类嵌套在注解类中,因为这样更方便,但您可以自由地在单独的 Java 文件中实现它。 |
| 7 | 处理器必须实现TypeMappingAnnotationProcessor 接口,并将其泛型类型参数设置为相应注解的类型。 |
| 8 | 在注解处理器中,实例化绑定器。 |
| 9 | 处理注解属性并将数据传递给绑定器。 这里我们使用的是 setter,但通过构造函数传递数据也可以。 |
| 10 | 将绑定器应用于类型。 |
public class FullNameBinder implements TypeBinder {
private boolean sortField;
public FullNameBinder sortField(boolean sortField) { (1)
this.sortField = sortField;
return this;
}
@Override
public void bind(TypeBindingContext context) {
context.dependencies()
.use( "firstName" )
.use( "lastName" );
IndexFieldReference<String> fullNameField = context.indexSchemaElement()
.field( "fullName", f -> f.asString().analyzer( "name" ) )
.toReference();
IndexFieldReference<String> fullNameSortField = null;
if ( this.sortField ) { (2)
fullNameSortField = context.indexSchemaElement()
.field(
"fullName_sort",
f -> f.asString().normalizer( "name" ).sortable( Sortable.YES )
)
.toReference();
}
context.bridge( Author.class, new Bridge(
fullNameField,
fullNameSortField
) );
}
private static class Bridge implements TypeBridge<Author> {
private final IndexFieldReference<String> fullNameField;
private final IndexFieldReference<String> fullNameSortField;
private Bridge(IndexFieldReference<String> fullNameField,
IndexFieldReference<String> fullNameSortField) { (2)
this.fullNameField = fullNameField;
this.fullNameSortField = fullNameSortField;
}
@Override
public void write(
DocumentElement target,
Author author,
TypeBridgeWriteContext context) {
String fullName = author.getLastName() + " " + author.getFirstName();
target.addValue( this.fullNameField, fullName );
if ( this.fullNameSortField != null ) {
target.addValue( this.fullNameSortField, fullName );
}
}
}
}| 1 | 在绑定器中实现 setter。或者,我们可以公开一个参数化的构造函数。 |
| 2 | 在bind 方法中,使用参数的值。这里使用sortField 参数来决定是否添加另一个可排序字段,但我们可以将参数用于任何目的:定义字段名称、定义规范化器、自定义注解等等。 |
@Entity
@Indexed
@FullNameBinding(sortField = true) (1)
public class Author {
@Id
@GeneratedValue
private Integer id;
private String firstName;
private String lastName;
// Getters and setters
// ...
}| 1 | 使用其自定义注解应用桥,设置sortField 参数。 |
12.4.3. 从桥访问 ORM 会话
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
传递给桥接方法的上下文可用于检索 Hibernate ORM 会话。
TypeBridge 检索 ORM 会话private static class Bridge implements TypeBridge<Object> {
private final IndexFieldReference<String> field;
private Bridge(IndexFieldReference<String> field) {
this.field = field;
}
@Override
public void write(DocumentElement target, Object bridgedElement, TypeBridgeWriteContext context) {
Session session = context.extension( HibernateOrmExtension.get() ) (1)
.session(); (2)
// ... do something with the session ...
}
}| 1 | 应用一个扩展到上下文以访问特定于 Hibernate ORM 的内容。 |
| 2 | 从扩展上下文检索 Session。 |
12.4.4. 将 bean 注入绑定器
使用 兼容框架,Hibernate Search 支持将 Bean 注入
-
如果您使用自定义注解,则使用
TypeMappingAnnotationProcessor。 -
如果您使用
@TypeBinding注解,则使用TypeBinder。
这仅适用于通过 Hibernate Search 的bean 解析实例化的 bean。作为经验法则,如果您需要在某个时刻显式调用new MyBinder(),则绑定器不会自动注入。 |
传递给路由键绑定器bind方法的上下文还公开了一个beanResolver()方法,用于访问 bean 解析器并显式实例化 bean。
有关详细信息,请参阅 Bean 注入。
12.4.5. 编程映射
您也可以通过编程映射应用类型桥。只需传递绑定器的实例。您可以通过绑定器的构造函数或通过 setter 传递参数。
.binder(…) 应用TypeBinderTypeMappingStep authorMapping = mapping.type( Author.class );
authorMapping.indexed();
authorMapping.binder( new FullNameBinder().sortField( true ) );12.4.6. 孵化功能
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
传递给类型绑定器bind方法的上下文公开了一个bridgedElement()方法,它可以访问有关正在绑定的类型的元数据。
元数据尤其可用于详细检查类型
-
获取属性的访问器。
-
检测带有标记的属性。标记由带有
@MarkerBinding元注解的特定注解应用。
有关更多信息,请参阅 javadoc。
12.5. 标识符桥
12.5.1. 基础知识
标识符桥是一个可插拔组件,它实现将实体属性映射到文档标识符。它通过@DocumentId 注解或自定义注解应用于属性。
实现标识符桥归结为实现两个方法
-
一个方法将属性值(任何类型)转换为文档标识符(字符串);
-
一个方法将文档标识符转换回原始属性值。
以下是一个自定义标识符桥的示例,它将自定义BookId 类型转换为其字符串表示形式,反之亦然
IdentifierBridgepublic class BookIdBridge implements IdentifierBridge<BookId> { (1)
@Override
public String toDocumentIdentifier(BookId value,
IdentifierBridgeToDocumentIdentifierContext context) { (2)
return value.getPublisherId() + "/" + value.getPublisherSpecificBookId();
}
@Override
public BookId fromDocumentIdentifier(String documentIdentifier,
IdentifierBridgeFromDocumentIdentifierContext context) { (3)
String[] split = documentIdentifier.split( "/" );
return new BookId( Long.parseLong( split[0] ), Long.parseLong( split[1] ) );
}
}| 1 | 桥必须实现IdentifierBridge 接口。必须提供一个泛型参数:属性值的类型(实体模型中的值)。 |
| 2 | toDocumentIdentifier 方法将属性值和上下文对象作为参数,并应返回相应的文档标识符。它在索引时被调用,在搜索 DSL必须转换的参数时也被调用,特别是对于ID 谓词。 |
| 3 | fromDocumentIdentifier 方法将文档标识符和上下文对象作为参数,并应返回原始属性值。它在将搜索命中映射到相应的实体时被调用。 |
@Entity
@Indexed
public class Book {
@EmbeddedId
@DocumentId( (1)
identifierBridge = @IdentifierBridgeRef(type = BookIdBridge.class) (2)
)
private BookId id = new BookId();
private String title;
// Getters and setters
// ...
}| 1 | 将属性映射到文档标识符。 |
| 2 | 指示 Hibernate Search 使用我们的自定义标识符桥。也可以通过名称引用桥,如果是 CDI/Spring bean 的情况。 |
12.5.2. 类型解析
默认情况下,标识符桥的属性类型是自动确定的,使用反射提取IdentifierBridge 接口的泛型类型参数。
例如,在public class MyBridge implements IdentifierBridge<BookId> 中,属性类型被解析为BookId:桥将应用于类型为BookId 的属性。
类型是使用反射自动解析的事实带来了一些限制。特别是,这意味着泛型类型参数不能是任何东西;作为一般规则,您应该坚持使用文字类型(MyBridge implements IdentifierBridge<BookId>)并避免使用泛型类型参数和通配符(MyBridge<T extends Number> implements IdentifierBridge<T>,MyBridge implements IdentifierBridge<List<? extends Number>>)。
如果您需要更复杂的类型,您可以绕过自动解析,并使用 IdentifierBinder 显式指定类型。
12.5.3. 使用 isCompatibleWith() 跨索引的兼容性
标识符桥参与索引,但也参与搜索 DSL,将传递给 id 谓词 的值转换为后端可以理解的文档标识符。
当创建针对多个实体类型(及其索引)的 id 谓词时,Hibernate Search 将有多个桥梁可供选择:每个实体类型一个。由于只能创建一个具有单个值的谓词,Hibernate Search 需要选择一个桥梁。
默认情况下,当将自定义桥梁分配给字段时,Hibernate Search 会抛出异常,因为它无法决定选择哪个桥梁。
如果在所有索引中分配给该字段的桥都生成相同的结果,则可以通过实现 isCompatibleWith 来指示 Hibernate Search 任何桥都可以。
此方法接受另一个桥作为参数,如果该桥可以预期始终表现得与 this 相同,则返回 true。
isCompatibleWith 以支持多索引搜索public class BookOrMagazineIdBridge implements IdentifierBridge<BookOrMagazineId> {
@Override
public String toDocumentIdentifier(BookOrMagazineId value,
IdentifierBridgeToDocumentIdentifierContext context) {
return value.getPublisherId() + "/" + value.getPublisherSpecificBookId();
}
@Override
public BookOrMagazineId fromDocumentIdentifier(String documentIdentifier,
IdentifierBridgeFromDocumentIdentifierContext context) {
String[] split = documentIdentifier.split( "/" );
return new BookOrMagazineId( Long.parseLong( split[0] ), Long.parseLong( split[1] ) );
}
@Override
public boolean isCompatibleWith(IdentifierBridge<?> other) {
return getClass().equals( other.getClass() ); (1)
}
}| 1 | 根据需要实现 isCompatibleWith。这里我们只认为同一个类的任何实例都是兼容的。 |
12.5.4. 使用 parseIdentifierLiteral(..) 解析标识符的字符串表示形式
在某些情况下,Hibernate Search 可能需要解析标识符的字符串表示形式,例如,当 标识符匹配谓词 的匹配子句中使用 ValueModel.STRING 时。
使用自定义标识符桥,Hibernate Search 默认情况下无法自动解析此类标识符字面量。为了解决这个问题,可以实现 parseIdentifierLiteral(..)。
parseIdentifierLiteral(..)public class BookIdBridge implements IdentifierBridge<BookId> { (1)
// Implement mandatory toDocumentIdentifier/fromDocumentIdentifier ...
// ...
@Override
public BookId parseIdentifierLiteral(String value) { (2)
if ( value == null ) {
return null;
}
String[] parts = value.split( "/" );
if ( parts.length != 2 ) {
throw new IllegalArgumentException( "BookId string literal must be in a `pubId/bookId` format." );
}
return new BookId( Long.parseLong( parts[0] ), Long.parseLong( parts[1] ) );
}
}List<Book> result = searchSession.search( Book.class )
.where( f -> f.id().matching( "1/42", ValueModel.STRING ) ) (1)
.fetchHits( 20 );| 1 | 在 标识符匹配谓词 中使用 ValueModel.STRING 和标识符的字符串表示形式。 |
12.5.5. 使用 IdentifierBinder 更精细地配置桥梁
为了更精细地配置桥梁,可以实现一个将在引导时执行的值绑定器。此绑定器特别能够检查属性的类型。
IdentifierBinderpublic class BookIdBinder implements IdentifierBinder { (1)
@Override
public void bind(IdentifierBindingContext<?> context) { (2)
context.bridge( (3)
BookId.class, (4)
new Bridge() (5)
);
}
private static class Bridge implements IdentifierBridge<BookId> { (6)
@Override
public String toDocumentIdentifier(BookId value,
IdentifierBridgeToDocumentIdentifierContext context) {
return value.getPublisherId() + "/" + value.getPublisherSpecificBookId();
}
@Override
public BookId fromDocumentIdentifier(String documentIdentifier,
IdentifierBridgeFromDocumentIdentifierContext context) {
String[] split = documentIdentifier.split( "/" );
return new BookId( Long.parseLong( split[0] ), Long.parseLong( split[1] ) );
}
}
}| 1 | 绑定器必须实现 IdentifierBinder 接口。 |
| 2 | 实现 bind 方法。 |
| 3 | 调用 context.bridge(…) 以定义要使用的标识符桥梁。 |
| 4 | 传递预期的属性值的类型。 |
| 5 | 传递标识符桥实例。 |
| 6 | 标识符桥必须仍然实现。 这里桥梁类嵌套在绑定程序类中,因为这样更方便,但您可以自由地根据需要实现它:作为 lambda 表达式,在单独的 Java 文件中等等。 |
@Entity
@Indexed
public class Book {
@EmbeddedId
@DocumentId( (1)
identifierBinder = @IdentifierBinderRef(type = BookIdBinder.class) (2)
)
private BookId id = new BookId();
@FullTextField(analyzer = "english")
private String title;
// Getters and setters
// ...
}| 1 | 将属性映射到文档标识符。 |
| 2 | 指示 Hibernate Search 使用我们的自定义标识符绑定器。注意使用 identifierBinder 而不是 identifierBridge。如果它是 CDI/Spring Bean,也可以通过其名称引用绑定器。 |
12.5.6. 传递参数
有两种方法可以将参数传递给标识符桥梁
-
一种方法(主要)限于字符串参数,但实现起来很简单。
-
另一种方法可以允许任何类型的参数,但需要您声明自己的注解。
简单字符串参数
您可以将字符串参数传递给 @IdentifierBinderRef 注释,然后在绑定器中使用它们
@IdentifierBinderRef 注释将参数传递给 IdentifierBridgepublic class OffsetIdentifierBridge implements IdentifierBridge<Integer> { (1)
private final int offset;
public OffsetIdentifierBridge(int offset) { (2)
this.offset = offset;
}
@Override
public String toDocumentIdentifier(Integer propertyValue, IdentifierBridgeToDocumentIdentifierContext context) {
return String.valueOf( propertyValue + offset );
}
@Override
public Integer fromDocumentIdentifier(String documentIdentifier,
IdentifierBridgeFromDocumentIdentifierContext context) {
return Integer.parseInt( documentIdentifier ) - offset;
}
}| 1 | 实现一个将标识符按原样索引但添加可配置偏移量的桥梁,例如,如果偏移量为 1,数据库标识符从 0 开始,索引标识符将从 1 开始。 |
| 2 | 桥梁在构造函数中接受一个参数:要应用于标识符的偏移量。 |
public class OffsetIdentifierBinder implements IdentifierBinder {
@Override
public void bind(IdentifierBindingContext<?> context) {
String offset = context.params().get( "offset", String.class ); (1)
context.bridge(
Integer.class,
new OffsetIdentifierBridge( Integer.parseInt( offset ) ) (2)
);
}
}| 1 | 使用绑定上下文获取参数值。 如果未定义参数,则 |
| 2 | 将参数值作为参数传递给桥梁构造函数。 |
@Entity
@Indexed
public class Book {
@Id
// DB identifiers start at 0, but index identifiers start at 1
@DocumentId(identifierBinder = @IdentifierBinderRef( (1)
type = OffsetIdentifierBinder.class,
params = @Param(name = "offset", value = "1")))
private Integer id;
private String title;
// Getters and setters
// ...
}| 1 | 定义要用于标识符的绑定器,并设置参数。 |
使用自定义注释的参数
您可以通过定义具有属性的 自定义注解 将任何类型的参数传递给桥接。
IdentifierBridgepublic class OffsetIdentifierBridge implements IdentifierBridge<Integer> { (1)
private final int offset;
public OffsetIdentifierBridge(int offset) { (2)
this.offset = offset;
}
@Override
public String toDocumentIdentifier(Integer propertyValue, IdentifierBridgeToDocumentIdentifierContext context) {
return String.valueOf( propertyValue + offset );
}
@Override
public Integer fromDocumentIdentifier(String documentIdentifier,
IdentifierBridgeFromDocumentIdentifierContext context) {
return Integer.parseInt( documentIdentifier ) - offset;
}
}| 1 | 实现一个将标识符按原样索引但添加可配置偏移量的桥梁,例如,如果偏移量为 1,数据库标识符从 0 开始,索引标识符将从 1 开始。 |
| 2 | 桥梁在构造函数中接受一个参数:要应用于标识符的偏移量。 |
@Retention(RetentionPolicy.RUNTIME) (1)
@Target({ ElementType.METHOD, ElementType.FIELD }) (2)
@PropertyMapping(processor = @PropertyMappingAnnotationProcessorRef( (3)
type = OffsetDocumentId.Processor.class
))
@Documented (4)
public @interface OffsetDocumentId {
int offset(); (5)
class Processor (6)
implements PropertyMappingAnnotationProcessor<OffsetDocumentId> { (7)
@Override
public void process(PropertyMappingStep mapping, OffsetDocumentId annotation,
PropertyMappingAnnotationProcessorContext context) {
OffsetIdentifierBridge bridge = new OffsetIdentifierBridge( (8)
annotation.offset()
);
mapping.documentId() (9)
.identifierBridge( bridge ); (10)
}
}
}| 1 | 定义一个具有 RUNTIME 保留策略的注解。任何其他保留策略都将导致 Hibernate Search 忽略该注解。 |
| 2 | 由于我们正在定义一个标识符桥梁,因此允许注释针对方法(getter)或字段。 |
| 3 | 将此注解标记为属性映射,并指示 Hibernate Search 在找到此注解时应用给定的处理器。也可以通过其 CDI/Spring bean 名称来引用处理器。 |
| 4 | 可选地,将注解标记为已记录,以便将其包含在实体的 javadoc 中。 |
| 5 | 定义自定义属性以配置值桥梁。这里我们定义了一个桥梁应该添加到实体标识符的偏移量。 |
| 6 | 这里处理器类嵌套在注解类中,因为这样更方便,但您可以自由地在单独的 Java 文件中实现它。 |
| 7 | 处理器必须实现 PropertyMappingAnnotationProcessor 接口,并设置其泛型类型参数为相应注解的类型。 |
| 8 | 在 process 方法中,实例化桥梁并将注释属性作为构造函数参数传递。 |
| 9 | 声明此属性将用于生成文档标识符。 |
| 10 | 指示 Hibernate Search 使用我们的桥梁在属性和文档标识符之间进行转换。或者,我们可以使用 identifierBinder() 方法传递一个标识符绑定器。 |
@Entity
@Indexed
public class Book {
@Id
// DB identifiers start at 0, but index identifiers start at 1
@OffsetDocumentId(offset = 1) (1)
private Integer id;
private String title;
// Getters and setters
// ...
}| 1 | 使用其自定义注释应用桥梁,并设置参数。 |
12.5.7. 从桥梁访问 ORM 会话或会话工厂
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
传递给桥接方法的上下文可用于检索 Hibernate ORM 会话或会话工厂。
IdentifierBridge 中检索 ORM 会话或会话工厂public class MyDataIdentifierBridge implements IdentifierBridge<MyData> {
@Override
public String toDocumentIdentifier(MyData propertyValue, IdentifierBridgeToDocumentIdentifierContext context) {
SessionFactory sessionFactory = context.extension( HibernateOrmExtension.get() ) (1)
.sessionFactory(); (2)
// ... do something with the factory ...
}
@Override
public MyData fromDocumentIdentifier(String documentIdentifier,
IdentifierBridgeFromDocumentIdentifierContext context) {
Session session = context.extension( HibernateOrmExtension.get() ) (3)
.session(); (4)
// ... do something with the session ...
}
}| 1 | 应用一个扩展到上下文以访问特定于 Hibernate ORM 的内容。 |
| 2 | 从扩展上下文检索 SessionFactory。Session 在这里不可用。 |
| 3 | 应用一个扩展到上下文以访问特定于 Hibernate ORM 的内容。 |
| 4 | 从扩展上下文检索 Session。 |
12.5.8. 将 Bean 注入桥梁或绑定器
使用 兼容的框架,Hibernate Search 支持将 Bean 注入 IdentifierBridge 和 IdentifierBinder 中。
这仅适用于通过 Hibernate Search 的 Bean 解析 实例化的 Bean。一般来说,如果您需要在某个时刻显式调用 new MyBridge(),则该桥接不会被自动注入。 |
传递给标识符绑定器的 bind 方法的上下文还公开了一个 beanResolver() 方法,以访问 Bean 解析器并显式实例化 Bean。
有关详细信息,请参阅 Bean 注入。
12.5.9. 编程映射
您也可以通过 编程映射 应用标识符桥梁。只需传递桥梁的实例。
.identifierBridge(…) 应用 IdentifierBridgeTypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "id" )
.documentId().identifierBridge( new BookIdBridge() );同样,您可以传递一个绑定器实例
.identifierBinder(…) 应用 IdentifierBinderTypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed();
bookMapping.property( "id" )
.documentId().identifierBinder( new BookIdBinder() );12.5.10. 孵化功能
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
传递给标识符绑定器的 bind 方法的上下文公开了一个 bridgedElement() 方法,它可以访问有关被绑定值的元数据,尤其是其类型。
有关更多信息,请参阅 javadoc。
12.6. 路由桥梁
12.6.1. 基础知识
路由桥梁是一个可插拔组件,它在运行时定义实体是否应该被索引以及 相应的索引文档应该被路由到哪个分片。它使用 @Indexed 注释应用于索引的实体类型,使用其 routingBinder 属性(@Indexed(routingBinder = …))。
实现路由桥梁需要两个组件
-
RoutingBinder的自定义实现,用于在引导时将桥梁绑定到索引的实体类型。这包括声明将由路由桥梁使用的索引实体类型的属性,以及实例化路由桥梁。 -
RoutingBridge的自定义实现,用于在运行时将实体路由到索引。这包括从类型的实例中提取数据,如果需要,转换数据,并定义当前路由(或将实体标记为“未索引”)。如果路由可以在实体实例的生命周期内发生变化,您还需要定义潜在的先前路由,以便 Hibernate Search 能够找到并删除以前为该实体实例索引的文档。
在下面的部分中,您将找到主要用例的示例
12.6.2. 使用路由桥梁进行条件索引
下面是自定义路由桥梁的第一个示例,该示例在 Book 类的实例的 status 为 ARCHIVED 时禁用索引。
RoutingBridge 进行条件索引public class BookStatusRoutingBinder implements RoutingBinder { (1)
@Override
public void bind(RoutingBindingContext context) { (2)
context.dependencies() (3)
.use( "status" );
context.bridge( (4)
Book.class, (5)
new Bridge() (6)
);
}
// ... class continues below| 1 | 绑定器必须实现 RoutingBinder 接口。 |
| 2 | 在绑定器中实现 bind 方法。 |
| 3 | 声明桥梁的依赖项,即桥梁实际上将使用的实体实例的部分。有关声明依赖项的更多信息,请参见 声明对桥接元素的依赖项。 |
| 4 | 调用 context.bridge(…) 以定义要使用的路由桥梁。 |
| 5 | 传递索引实体的预期类型。 |
| 6 | 传递路由桥实例。 |
// ... class BookStatusRoutingBinder (continued)
public static class Bridge (1)
implements RoutingBridge<Book> { (2)
@Override
public void route(DocumentRoutes routes, Object entityIdentifier, (3)
Book indexedEntity, RoutingBridgeRouteContext context) {
switch ( indexedEntity.getStatus() ) { (4)
case PUBLISHED:
routes.addRoute(); (5)
break;
case ARCHIVED:
routes.notIndexed(); (6)
break;
}
}
@Override
public void previousRoutes(DocumentRoutes routes, Object entityIdentifier, (7)
Book indexedEntity, RoutingBridgeRouteContext context) {
routes.addRoute(); (8)
}
}
}| 1 | 这里桥梁类嵌套在绑定程序类中,因为这样更方便,但您可以自由地根据需要实现它:作为 lambda 表达式,在单独的 Java 文件中等等。 |
| 2 | 桥梁必须实现 RoutingBridge 接口。 |
| 3 | 在桥梁中实现 route(…) 方法。此方法在索引时被调用。 |
| 4 | 从桥接元素中提取数据并检查它。 |
| 5 | 如果 Book 状态为 PUBLISHED,那么我们希望继续进行索引:添加一个路由,以便 Hibernate Search 像往常一样索引实体。 |
| 6 | 如果 Book 状态为 ARCHIVED,那么我们不想索引它:调用 notIndexed(),以便 Hibernate Search 知道它不应该索引实体。 |
| 7 | 当一本书被存档时,可能存在需要删除的以前索引的文档。previousRoutes(…) 方法允许您告诉 Hibernate Search 此文档可能位于何处。在必要时,Hibernate Search 将遵循每个给定的路由,查找对应于此实体的文档,并删除它们。 |
| 8 | 在本例中,路由非常简单:只有一个可能的先前路由,因此我们只注册该路由。 |
@Entity
@Indexed(routingBinder = @RoutingBinderRef(type = BookStatusRoutingBinder.class)) (1)
public class Book {
@Id
private Integer id;
private String title;
@Basic(optional = false)
@KeywordField (2)
private Status status;
// Getters and setters
// ...
}| 1 | 使用 @Indexed 注释应用桥梁。 |
| 2 | 桥梁中使用的属性仍然可以映射为索引字段,但它们不必是。 |
12.6.3. 使用路由桥梁控制路由到索引分片
|
有关分片的初步介绍,包括它在 Hibernate Search 中的工作原理及其局限性,请参见 分片和路由。 |
路由桥梁也可以用于控制 路由到索引分片。
下面是一个自定义路由桥梁的示例,它使用 Book 类的 genre 属性作为路由键。有关如何在搜索查询中使用路由的示例,请参见 路由,其映射与下面的示例相同。
RoutingBridge 控制路由到索引分片public class BookGenreRoutingBinder implements RoutingBinder { (1)
@Override
public void bind(RoutingBindingContext context) { (2)
context.dependencies() (3)
.use( "genre" );
context.bridge( (4)
Book.class, (5)
new Bridge() (6)
);
}
// ... class continues below| 1 | 绑定器必须实现 RoutingBinder 接口。 |
| 2 | 在绑定器中实现 bind 方法。 |
| 3 | 声明桥梁的依赖项,即桥梁实际上将使用的实体实例的部分。有关声明依赖项的更多信息,请参见 声明对桥接元素的依赖项。 |
| 4 | 调用 context.bridge(…) 以定义要使用的路由桥梁。 |
| 5 | 传递索引实体的预期类型。 |
| 6 | 传递路由桥实例。 |
// ... class BookGenreRoutingBinder (continued)
public static class Bridge implements RoutingBridge<Book> { (1)
@Override
public void route(DocumentRoutes routes, Object entityIdentifier, (2)
Book indexedEntity, RoutingBridgeRouteContext context) {
String routingKey = indexedEntity.getGenre().name(); (3)
routes.addRoute().routingKey( routingKey ); (4)
}
@Override
public void previousRoutes(DocumentRoutes routes, Object entityIdentifier, (5)
Book indexedEntity, RoutingBridgeRouteContext context) {
for ( Genre possiblePreviousGenre : Genre.values() ) {
String routingKey = possiblePreviousGenre.name();
routes.addRoute().routingKey( routingKey ); (6)
}
}
}
}| 1 | 桥梁必须实现 RoutingBridge 接口。这里桥梁类嵌套在绑定器类中,因为这样做更方便,但您当然可以自由地在单独的 java 文件中实现它。 |
| 2 | 在桥梁中实现 route(…) 方法。此方法在索引时被调用。 |
| 3 | 从桥接元素中提取数据并派生路由键。 |
| 4 | 使用生成的路由键添加路由。Hibernate Search 在索引中添加/更新/删除实体时将遵循此路由。 |
| 5 | 当书籍的类型发生变化时,路由将发生变化,并且可能存在需要删除的以前索引的文档。previousRoutes(…) 方法允许您告诉 Hibernate Search 此文档可能位于何处。在必要时,Hibernate Search 将遵循每个给定的路由,查找对应于此实体的文档,并删除它们。 |
| 6 | 在本例中,我们只是不知道书籍的先前类型是什么,因此我们告诉 Hibernate Search 遵循所有可能的路由,每个可能的类型一个。 |
@Entity
@Indexed(routingBinder = @RoutingBinderRef(type = BookGenreRoutingBinder.class)) (1)
public class Book {
@Id
private Integer id;
private String title;
@Basic(optional = false)
@KeywordField (2)
private Genre genre;
// Getters and setters
// ...
}| 1 | 使用 @Indexed 注释应用桥梁。 |
| 2 | 桥梁中使用的属性仍然可以映射为索引字段,但它们不必是。 |
|
优化
previousRoutes(…)在某些情况下,您可能比上面的示例拥有更多关于先前路由的信息,您可以利用这些信息来减少索引中的删除操作。
|
12.6.4. 传递参数
有两种方法可以将参数传递给路由桥接器。
-
一种方法(主要)限于字符串参数,但实现起来很简单。
-
另一种方法可以允许任何类型的参数,但需要您声明自己的注解。
请参考 这个 TypeBinder 的示例,它与您在 RoutingBinder 中需要的非常相似。
12.6.5. 从桥接器访问 ORM 会话
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
传递给桥接方法的上下文可用于检索 Hibernate ORM 会话。
RoutingBridge 获取 ORM 会话private static class Bridge implements RoutingBridge<MyEntity> {
@Override
public void route(DocumentRoutes routes, Object entityIdentifier, MyEntity indexedEntity,
RoutingBridgeRouteContext context) {
Session session = context.extension( HibernateOrmExtension.get() ) (1)
.session(); (2)
// ... do something with the session ...
}
@Override
public void previousRoutes(DocumentRoutes routes, Object entityIdentifier, MyEntity indexedEntity,
RoutingBridgeRouteContext context) {
// ...
}
}| 1 | 应用一个扩展到上下文以访问特定于 Hibernate ORM 的内容。 |
| 2 | 从扩展上下文检索 Session。 |
12.6.6. 将 bean 注入到绑定器中
使用 兼容框架,Hibernate Search 支持将 Bean 注入
-
如果您使用 自定义注释,则使用
TypeMappingAnnotationProcessor。 -
如果您使用
@Indexed(routingBinder = …),则使用RoutingBinder。
这仅适用于通过 Hibernate Search 的bean 解析实例化的 bean。作为经验法则,如果您需要在某个时刻显式调用new MyBinder(),则绑定器不会自动注入。 |
传递给路由绑定器的 bind 方法的上下文还公开了一个 beanResolver() 方法,用于访问 bean 解析器并显式地实例化 bean。
有关详细信息,请参阅 Bean 注入。
12.6.7. 编程方式映射
您也可以通过 编程方式映射 来应用路由键桥接器。只需传递绑定器的实例即可。
.binder(…) 应用 RoutingBinderTypeMappingStep bookMapping = mapping.type( Book.class );
bookMapping.indexed()
.routingBinder( new BookStatusRoutingBinder() );
bookMapping.property( "status" ).keywordField();12.6.8. 孵化功能
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
传递给路由绑定器的 bind 方法的上下文公开了一个 bridgedElement() 方法,它可以访问有关要绑定类型元数据的访问权限。
元数据尤其可用于详细检查类型
-
获取属性的访问器。
-
检测带有标记的属性。标记由带有
@MarkerBinding元注解的特定注解应用。
有关更多信息,请参阅 javadoc。
12.7. 声明对桥接元素的依赖项
12.7.1. 基础知识
为了使索引保持同步,Hibernate Search 需要了解所有用于生成索引文档的实体属性,以便在它们发生变化时触发重新索引。
这通过一个专门的 DSL 完成,可以从 TypeBinder 和 PropertyBinder 的 bind(…) 方法访问。
下面是一个类型绑定器的示例,它期望被应用于 ScientificPaper 类型,并声明对论文作者的姓氏和名字的依赖关系。
public class AuthorFullNameBinder implements TypeBinder {
@Override
public void bind(TypeBindingContext context) {
context.dependencies() (1)
.use( "author.firstName" ) (2)
.use( "author.lastName" ); (3)
IndexFieldReference<String> authorFullNameField = context.indexSchemaElement()
.field( "authorFullName", f -> f.asString().analyzer( "name" ) )
.toReference();
context.bridge( Book.class, new Bridge( authorFullNameField ) );
}
private static class Bridge implements TypeBridge<Book> {
// ...
}
}| 1 | 开始声明依赖项。 |
| 2 | 声明桥接器将访问论文的 author 属性,然后是作者的 firstName 属性。 |
| 3 | 声明桥接器将访问论文的 author 属性,然后是作者的 lastName 属性。 |
以上内容应该足以开始,但如果您想了解更多信息,以下是一些关于声明依赖项的事实。
- 路径相对于桥接元素
-
例如
-
对于类型
ScientificPaper上的类型桥接器,路径author将引用ScientificPaper实例上author属性的值。 -
对于
ScientificPaper的author属性上的属性桥接器,路径name将引用Author实例上name属性的值。
-
- 给定路径的每个组件都将被视为依赖项
-
您不需要声明任何父路径。
例如,如果声明使用路径
myProperty.someOtherProperty,Hibernate Search 将自动假设也使用myProperty。 - 只需要声明可变属性
-
如果一个属性在实体第一次持久化后永远不会改变,那么它将永远不会触发重新索引,Hibernate Search 不需要知道依赖关系。
如果您的桥接器只依赖不可变属性,请参见
useRootOnly():根本不声明依赖项。 - 包含在依赖项路径中的关联需要有一个反向端
-
如果您声明一个跨越实体边界的关联的依赖项,并且该关联在另一个实体中没有反向端,则会抛出异常。
例如,当您声明对路径
author.lastName的依赖项时,Hibernate Search 推断出,只要作者的姓氏发生变化,其书籍就需要重新索引。因此,当它检测到作者的姓氏发生变化时,Hibernate Search 将需要检索书籍以重新索引它们。这就是为什么ScientificPaper实体中的author关联需要在Author实体中有一个反向端,例如books关联。有关这些约束以及如何解决非平凡模型的更多信息,请参见 调整何时触发重新索引。
12.7.2. 遍历非默认容器(映射键,…)
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
当路径元素引用容器类型的属性(List,Map,Optional,…)时,该路径将隐式解析为该容器的元素。例如,someMap.otherObject 将解析为 someMap 的值(而不是键)的 otherObject 属性。
如果默认解析不是您需要的,您可以通过传递 PojoModelPath 对象而不是简单字符串来显式控制如何遍历容器。
@Entity
@Indexed
@TypeBinding(binder = @TypeBinderRef(type = BookEditionsForSaleTypeBinder.class)) (1)
public class Book {
@Id
@GeneratedValue
private Integer id;
@FullTextField(analyzer = "name")
private String title;
@ElementCollection
@JoinTable(
name = "book_editionbyprice",
joinColumns = @JoinColumn(name = "book_id")
)
@MapKeyJoinColumn(name = "edition_id")
@Column(name = "price")
@OrderBy("edition_id asc")
@AssociationInverseSide(
extraction = @ContainerExtraction(BuiltinContainerExtractors.MAP_KEY),
inversePath = @ObjectPath(@PropertyValue(propertyName = "book"))
)
private Map<BookEdition, BigDecimal> priceByEdition = new LinkedHashMap<>(); (2)
public Book() {
}
// Getters and setters
// ...
}| 1 | 将自定义桥接器应用于 ScientificPaper 实体。 |
| 2 | 此(相当复杂的)映射是我们将在自定义桥接器中访问的映射。 |
public class BookEditionsForSaleTypeBinder implements TypeBinder {
@Override
public void bind(TypeBindingContext context) {
context.dependencies()
.use( PojoModelPath.builder() (1)
.property( "priceByEdition" ) (2)
.value( BuiltinContainerExtractors.MAP_KEY ) (3)
.property( "label" ) (4)
.toValuePath() ); (5)
IndexFieldReference<String> editionsForSaleField = context.indexSchemaElement()
.field( "editionsForSale", f -> f.asString().analyzer( "english" ) )
.multiValued()
.toReference();
context.bridge( Book.class, new Bridge( editionsForSaleField ) );
}
private static class Bridge implements TypeBridge<Book> {
private final IndexFieldReference<String> editionsForSaleField;
private Bridge(IndexFieldReference<String> editionsForSaleField) {
this.editionsForSaleField = editionsForSaleField;
}
@Override
public void write(DocumentElement target, Book book, TypeBridgeWriteContext context) {
for ( BookEdition edition : book.getPriceByEdition().keySet() ) { (6)
target.addValue( editionsForSaleField, edition.getLabel() );
}
}
}
}| 1 | 开始构建 PojoModelPath。 |
| 2 | 将 priceByEdition 属性(一个 Map)追加到路径。 |
| 3 | 显式地提到桥接器将访问 priceByEdition 映射中的键——论文版本。如果没有此项,Hibernate Search 将假设访问值。 |
| 4 | 将 label 属性追加到路径。这是论文版本中的 label 属性。 |
| 5 | 创建路径并将其传递给 .use(…) 以声明依赖关系。 |
| 6 | 这是实际访问如上所述路径的代码。 |
对于应用于容器属性的属性绑定器,您可以通过将容器提取器路径作为第一个参数传递给 use(…) 来控制如何遍历该属性本身。
@Entity
@Indexed
public class Book {
@Id
@GeneratedValue
private Integer id;
@FullTextField(analyzer = "name")
private String title;
@ElementCollection
@JoinTable(
name = "book_editionbyprice",
joinColumns = @JoinColumn(name = "book_id")
)
@MapKeyJoinColumn(name = "edition_id")
@Column(name = "price")
@OrderBy("edition_id asc")
@AssociationInverseSide(
extraction = @ContainerExtraction(BuiltinContainerExtractors.MAP_KEY),
inversePath = @ObjectPath(@PropertyValue(propertyName = "book"))
)
@PropertyBinding(binder = @PropertyBinderRef(type = BookEditionsForSalePropertyBinder.class)) (1)
private Map<BookEdition, BigDecimal> priceByEdition = new LinkedHashMap<>();
public Book() {
}
// Getters and setters
// ...
}| 1 | 将自定义桥接器应用于 ScientificPaper 实体的 pricesByEdition 属性。 |
public class BookEditionsForSalePropertyBinder implements PropertyBinder {
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
.use( ContainerExtractorPath.explicitExtractor( BuiltinContainerExtractors.MAP_KEY ), (1)
"label" ); (2)
IndexFieldReference<String> editionsForSaleField = context.indexSchemaElement()
.field( "editionsForSale", f -> f.asString().analyzer( "english" ) )
.multiValued()
.toReference();
context.bridge( Map.class, new Bridge( editionsForSaleField ) );
}
@SuppressWarnings("rawtypes")
private static class Bridge implements PropertyBridge<Map> {
private final IndexFieldReference<String> editionsForSaleField;
private Bridge(IndexFieldReference<String> editionsForSaleField) {
this.editionsForSaleField = editionsForSaleField;
}
@Override
public void write(DocumentElement target, Map bridgedElement, PropertyBridgeWriteContext context) {
@SuppressWarnings("unchecked")
Map<BookEdition, ?> priceByEdition = (Map<BookEdition, ?>) bridgedElement;
for ( BookEdition edition : priceByEdition.keySet() ) { (3)
target.addValue( editionsForSaleField, edition.getLabel() );
}
}
}
}| 1 | 显式地提到桥接器将访问 priceByEdition 属性中的键——论文版本。如果没有此项,Hibernate Search 将假设访问值。 |
| 2 | 声明对论文版本中的 label 属性的依赖关系。 |
| 3 | 这是实际访问如上所述路径的代码。 |
12.7.3. useRootOnly():根本不声明依赖项
如果您的桥接器只访问不可变属性,那么声明其唯一的依赖项是对根对象的依赖项是安全的。
为此,请调用 .dependencies().useRootOnly()。
|
如果没有此调用,Hibernate Search 将怀疑存在疏忽,并在启动时抛出异常。 |
12.7.4. fromOtherEntity(…):使用反向路径声明依赖项
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
并非总是能够将依赖项表示为从桥接元素到桥接器访问的值的路径。
特别是,当桥接器依赖其他组件(查询、服务)来检索另一个实体时,甚至可能不存在从桥接元素到该实体的路径。在这种情况下,如果有从另一个实体到桥接元素的反向路径,并且桥接元素是一个实体,您可以简单地从另一个实体声明依赖关系,如下所示。
@Entity
@Indexed
@TypeBinding(binder = @TypeBinderRef(type = ScientificPapersReferencedByBinder.class)) (1)
public class ScientificPaper {
@Id
private Integer id;
private String title;
@ManyToMany
private List<ScientificPaper> references = new ArrayList<>();
public ScientificPaper() {
}
// Getters and setters
// ...
}| 1 | 将自定义桥接器应用于 ScientificPaper 类型。 |
public class ScientificPapersReferencedByBinder implements TypeBinder {
@Override
public void bind(TypeBindingContext context) {
context.dependencies()
.fromOtherEntity( ScientificPaper.class, "references" ) (1)
.use( "title" ); (2)
IndexFieldReference<String> papersReferencingThisOneField = context.indexSchemaElement()
.field( "referencedBy", f -> f.asString().analyzer( "english" ) )
.multiValued()
.toReference();
context.bridge( ScientificPaper.class, new Bridge( papersReferencingThisOneField ) );
}
private static class Bridge implements TypeBridge<ScientificPaper> {
private final IndexFieldReference<String> referencedByField;
private Bridge(IndexFieldReference<String> referencedByField) { (2)
this.referencedByField = referencedByField;
}
@Override
public void write(DocumentElement target, ScientificPaper paper, TypeBridgeWriteContext context) {
for ( String referencingPaperTitle : findReferencingPaperTitles( context, paper ) ) { (3)
target.addValue( referencedByField, referencingPaperTitle );
}
}
private List<String> findReferencingPaperTitles(TypeBridgeWriteContext context, ScientificPaper paper) {
Session session = context.extension( HibernateOrmExtension.get() ).session();
Query<String> query = session.createQuery(
"select p.title from ScientificPaper p where :this member of p.references",
String.class );
query.setParameter( "this", paper );
return query.list();
}
}
}| 1 | 声明此桥接器依赖于其他类型为 ScientificPaper 的实体,并且这些其他实体通过其 references 属性引用索引实体。 |
| 2 | 声明桥接器实际使用的其他实体的哪些部分。 |
| 3 | 桥接器通过查询检索其他实体,但随后只使用之前声明的部分。 |
|
目前,当“其他实体”被删除时,以这种方式声明的依赖关系将被忽略。 请参见 HSEARCH-3567,以跟踪解决此问题的进展。 |
12.8. 声明和写入索引字段
12.8.1. 基础知识
在实现 PropertyBinder 或 TypeBinder 时,需要声明桥接器将贡献的索引字段。此声明使用专门的 DSL 进行。
此 DSL 的入口点是 IndexNode,它表示绑定器将向其推送数据的文档结构的一部分。从 IndexNode 中,可以声明字段。
每个字段的声明都会产生一个字段引用。此引用将存储在桥接器中,桥接器将在运行时使用它来设置给定文档中此字段的值,该文档由 DocumentElement 表示。
下面是一个使用 DSL 在属性绑定器中声明单个字段,然后在属性桥接器中写入该字段的简单示例。
public class ISBNBinder implements PropertyBinder {
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
/* ... (declaration of dependencies, not relevant) ... */
IndexSchemaElement schemaElement = context.indexSchemaElement(); (1)
IndexFieldReference<String> field =
schemaElement.field( (2)
"isbn", (3)
f -> f.asString() (4)
.normalizer( "isbn" )
)
.toReference(); (5)
context.bridge( (6)
ISBN.class, (7)
new ISBNBridge( field ) (8)
);
}
}| 1 | 获取 IndexNode,即索引字段声明 DSL 的入口点。 |
| 2 | 声明一个字段。 |
| 3 | 传递字段的名称。 |
| 4 | 声明字段的类型。这是通过一个利用另一个 DSL 的 lambda 完成的。有关更多信息,请参见 定义索引字段类型。 |
| 5 | 获取对已声明字段的引用。 |
| 6 | 调用 context.bridge(…) 来定义要使用的桥接器。 |
| 7 | 传递预期值的类型。 |
| 8 | 传递桥接器实例。 |
private static class ISBNBridge implements PropertyBridge<ISBN> {
private final IndexFieldReference<String> fieldReference;
private ISBNBridge(IndexFieldReference<String> fieldReference) {
this.fieldReference = fieldReference;
}
@Override
public void write(DocumentElement target, ISBN bridgedElement, PropertyBridgeWriteContext context) {
String indexedValue = /* ... (extraction of data, not relevant) ... */
target.addValue( this.fieldReference, indexedValue ); (1)
}
}| 1 | 在桥接器中,使用上面获得的引用为当前文档的字段添加值。 |
12.8.2. 类型对象
使用 lambda 语法声明每个字段的类型很方便,但在某些情况下会造成阻碍,尤其是在需要使用完全相同的类型声明多个字段时。
出于这个原因,传递给绑定器的上下文对象会公开一个 typeFactory() 方法。使用这个工厂,可以构建可以重复使用在多个字段声明中的 IndexFieldType 对象。
@Override
public void bind(TypeBindingContext context) {
context.dependencies()
/* ... (declaration of dependencies, not relevant) ... */
IndexSchemaElement schemaElement = context.indexSchemaElement();
IndexFieldType<String> nameType = context.typeFactory() (1)
.asString() (2)
.analyzer( "name" )
.toIndexFieldType(); (3)
context.bridge( Author.class, new Bridge(
schemaElement.field( "firstName", nameType ) (4)
.toReference(),
schemaElement.field( "lastName", nameType ) (4)
.toReference(),
schemaElement.field( "fullName", nameType ) (4)
.toReference()
) );
}| 1 | 获取类型工厂。 |
| 2 | 定义类型。 |
| 3 | 获取生成的类型。 |
| 4 | 在定义字段时,直接传递类型,而不是使用 lambda 表达式。 |
12.8.3. 多值字段
默认情况下,字段被认为是单值的:如果尝试在索引期间向单值字段添加多个值,则会抛出异常。
为了向字段添加多个值,必须在声明期间将该字段标记为多值。
@Override
public void bind(TypeBindingContext context) {
context.dependencies()
/* ... (declaration of dependencies, not relevant) ... */
IndexSchemaElement schemaElement = context.indexSchemaElement();
context.bridge( Author.class, new Bridge(
schemaElement.field( "names", f -> f.asString().analyzer( "name" ) )
.multiValued() (1)
.toReference()
) );
}| 1 | 将字段声明为多值。 |
12.8.4. 对象字段
前面的部分只介绍了具有值字段的扁平化模式,但索引模式实际上可以组织成树结构,包含两种类型的索引字段。
-
值字段,通常简称为“字段”,它保存特定类型的原子值:字符串、整数、日期等。
-
对象字段,它保存复合值。
对象字段的声明方式与值字段类似,但需要额外的步骤来声明每个子字段,如下所示。
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
/* ... (declaration of dependencies, not relevant) ... */
IndexSchemaElement schemaElement = context.indexSchemaElement();
IndexSchemaObjectField summaryField =
schemaElement.objectField( "summary" ); (1)
IndexFieldType<BigDecimal> amountFieldType = context.typeFactory()
.asBigDecimal().decimalScale( 2 )
.toIndexFieldType();
context.bridge( List.class, new Bridge(
summaryField.toReference(), (2)
summaryField.field( "total", amountFieldType ) (3)
.toReference(),
summaryField.field( "books", amountFieldType ) (3)
.toReference(),
summaryField.field( "shipping", amountFieldType ) (3)
.toReference()
) );
}| 1 | 使用 objectField 声明一个对象字段,在参数中传递它的名称。 |
| 2 | 获取对已声明对象字段的引用,并将其传递给桥接器以供将来使用。 |
| 3 | 创建子字段,获取对这些字段的引用,并将它们传递给桥接器以供将来使用。 |
|
对象字段的子字段可以包含对象字段。 |
|
与值字段一样,对象字段默认情况下是单值的。如果要将其设为多值,请确保在对象字段定义期间调用 |
对象字段及其子字段都分配有引用,桥接器将使用这些引用写入文档,如下例所示。
@Override
public void write(DocumentElement target, List bridgedElement, PropertyBridgeWriteContext context) {
@SuppressWarnings("unchecked")
List<InvoiceLineItem> lineItems = (List<InvoiceLineItem>) bridgedElement;
BigDecimal total = BigDecimal.ZERO;
BigDecimal books = BigDecimal.ZERO;
BigDecimal shipping = BigDecimal.ZERO;
/* ... (computation of amounts, not relevant) ... */
DocumentElement summary = target.addObject( this.summaryField ); (1)
summary.addValue( this.totalField, total ); (2)
summary.addValue( this.booksField, books ); (2)
summary.addValue( this.shippingField, shipping ); (2)
}| 1 | 向当前文档的 summary 对象字段添加一个对象,并获取对该对象的引用。 |
| 2 | 向我们刚刚添加的对象的子字段添加值。请注意,我们在刚刚添加的对象上调用 addValue,而不是在 target 上。 |
12.8.5. 对象结构
默认情况下,对象字段是扁平化的,这意味着不会保留树结构。有关更多信息,请参阅 DEFAULT 或 FLATTENED 结构。
可以通过向 objectField 方法传递参数来切换到 嵌套结构,如下所示。然后,对象字段的每个值将被透明地索引为单独的嵌套文档,而无需对桥接器的 write 方法进行任何更改。
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
/* ... (declaration of dependencies, not relevant) ... */
IndexSchemaElement schemaElement = context.indexSchemaElement();
IndexSchemaObjectField lineItemsField =
schemaElement.objectField( (1)
"lineItems", (2)
ObjectStructure.NESTED (3)
)
.multiValued(); (4)
context.bridge( List.class, new Bridge(
lineItemsField.toReference(), (5)
lineItemsField.field( "category", f -> f.asString() ) (6)
.toReference(),
lineItemsField.field( "amount", f -> f.asBigDecimal().decimalScale( 2 ) ) (7)
.toReference()
) );
}| 1 | 使用 objectField 声明一个对象字段。 |
| 2 | 定义对象字段的名称。 |
| 3 | 定义对象字段的结构,这里为 NESTED。 |
| 4 | 将对象字段定义为多值。 |
| 5 | 获取对已声明对象字段的引用,并将其传递给桥接器以供将来使用。 |
| 6 | 创建子字段,获取对这些字段的引用,并将它们传递给桥接器以供将来使用。 |
12.8.6. 使用字段模板的动态字段
上面部分中声明的字段都是 静态 字段:它们的路径和类型在引导时就已知。
在某些非常特殊的情况下,在实际索引字段之前无法知道字段的路径;例如,可能想要通过使用映射键作为字段名来索引 Map<String, Integer>,或者索引架构未知的 JSON 对象的属性。然后,这些字段被认为是 动态 字段。
动态字段不会在引导时声明,但需要与在引导时声明的字段 模板 匹配。该模板包括字段类型和结构信息(是否为多值等),但不包括字段名。
字段模板始终在绑定器中声明:在 类型绑定器 或 属性绑定器 中。对于静态字段,声明模板的入口点是传递给绑定器 bind(…) 方法的 IndexNode。对模式元素调用 fieldTemplate 方法将声明字段模板。
假设在绑定期间声明了字段模板,则桥接器可以在索引时通过调用 addValue 并传递字段名(作为字符串)和字段值来向 DocumentElement 添加动态字段。
下面是一个简单的示例,它使用 DSL 在属性绑定器中声明字段模板,然后在属性桥接器中写入该字段。
public class UserMetadataBinder implements PropertyBinder {
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
/* ... (declaration of dependencies, not relevant) ... */
IndexSchemaElement schemaElement = context.indexSchemaElement();
IndexSchemaObjectField userMetadataField =
schemaElement.objectField( "userMetadata" ); (1)
userMetadataField.fieldTemplate( (2)
"userMetadataValueTemplate", (3)
f -> f.asString().analyzer( "english" ) (4)
); (5)
context.bridge( Map.class, new UserMetadataBridge(
userMetadataField.toReference() (6)
) );
}
}| 1 | 使用 objectField 声明一个对象字段。最好始终将动态字段托管在专用的对象字段中,以避免与其他模板发生冲突。 |
| 2 | 使用 fieldTemplate 声明字段模板。 |
| 3 | 传递 模板 名称 - 这不是字段名,只用于唯一标识模板。 |
| 4 | 定义字段类型。 |
| 5 | 与静态字段声明相反,字段模板声明不会返回字段引用,因为在写入文档时不需要该引用。 |
| 6 | 获取对已声明对象字段的引用,并将其传递给桥接器以供将来使用。 |
@SuppressWarnings("rawtypes")
private static class UserMetadataBridge implements PropertyBridge<Map> {
private final IndexObjectFieldReference userMetadataFieldReference;
private UserMetadataBridge(IndexObjectFieldReference userMetadataFieldReference) {
this.userMetadataFieldReference = userMetadataFieldReference;
}
@Override
public void write(DocumentElement target, Map bridgedElement, PropertyBridgeWriteContext context) {
@SuppressWarnings("unchecked")
Map<String, String> userMetadata = (Map<String, String>) bridgedElement;
DocumentElement indexedUserMetadata = target.addObject( userMetadataFieldReference ); (1)
for ( Map.Entry<String, String> entry : userMetadata.entrySet() ) {
String fieldName = entry.getKey();
String fieldValue = entry.getValue();
indexedUserMetadata.addValue( fieldName, fieldValue ); (2)
}
}
}| 1 | 向当前文档的 userMetadata 对象字段添加一个对象,并获取对该对象的引用。 |
| 2 | 为每个用户元数据条目添加一个字段,字段名和字段值由用户定义。请注意,字段名通常应该在此之前进行验证,以避免出现奇特的字符(空格、点等)。 |
|
虽然很少有必要,但也可以使用 |
还可以向同一个对象添加具有不同类型的多个字段。为此,请确保可以从字段名推断出字段的格式。然后,可以声明多个模板,并为每个模板分配路径模式,如下所示。
public class MultiTypeUserMetadataBinder implements PropertyBinder {
@Override
public void bind(PropertyBindingContext context) {
context.dependencies()
/* ... (declaration of dependencies, not relevant) ... */
IndexSchemaElement schemaElement = context.indexSchemaElement();
IndexSchemaObjectField userMetadataField =
schemaElement.objectField( "multiTypeUserMetadata" ); (1)
userMetadataField.fieldTemplate( (2)
"userMetadataValueTemplate_int", (3)
f -> f.asInteger().sortable( Sortable.YES ) (4)
)
.matchingPathGlob( "*_int" ); (5)
userMetadataField.fieldTemplate( (6)
"userMetadataValueTemplate_default",
f -> f.asString().analyzer( "english" )
);
context.bridge( Map.class, new Bridge( userMetadataField.toReference() ) );
}
}| 1 | 使用 objectField 声明一个对象字段。 |
| 2 | 使用 fieldTemplate 声明整数的字段模板。 |
| 3 | 传递 模板 名称。 |
| 4 | 将字段类型定义为整数,可排序。 |
| 5 | 为模板分配路径模式,以便只有以 _int 结尾的字段才会被视为整数。 |
| 6 | 声明另一个字段模板,以便如果字段不匹配先前的模板,则将其视为英文文本。 |
@SuppressWarnings("rawtypes")
private static class Bridge implements PropertyBridge<Map> {
private final IndexObjectFieldReference userMetadataFieldReference;
private Bridge(IndexObjectFieldReference userMetadataFieldReference) {
this.userMetadataFieldReference = userMetadataFieldReference;
}
@Override
public void write(DocumentElement target, Map bridgedElement, PropertyBridgeWriteContext context) {
@SuppressWarnings("unchecked")
Map<String, Object> userMetadata = (Map<String, Object>) bridgedElement;
DocumentElement indexedUserMetadata = target.addObject( userMetadataFieldReference ); (1)
for ( Map.Entry<String, Object> entry : userMetadata.entrySet() ) {
String fieldName = entry.getKey();
Object fieldValue = entry.getValue();
indexedUserMetadata.addValue( fieldName, fieldValue ); (2)
}
}
}| 1 | 向当前文档的 userMetadata 对象字段添加一个对象,并获取对该对象的引用。 |
| 2 | 为每个用户元数据条目添加一个字段,字段名和字段值由用户定义。请注意,字段值应该在此之前进行验证;在本例中,添加名为 foo_int 且值为 String 类型的字段会导致在索引时出现 SearchException。 |
|
字段模板的优先级
Hibernate Search 尝试按声明顺序匹配模板,因此应该始终先声明具有最具体路径模式的模板。 在给定模式元素上声明的模板可以在该元素的子元素中匹配。例如,如果在实体的根目录(通过 类型桥接器)中声明模板,则这些模板将在该实体的每个属性桥接器中隐式可用。在这种情况下,在属性桥接器中声明的模板将优先于在类型桥接器中声明的模板。 |
12.9. 定义索引字段类型
12.9.1. 基础知识
基于 Lucene 的搜索引擎(包括 Elasticsearch)的一个特性是,字段类型比简单的“字符串”、“整数”等数据类型要复杂得多。
在声明字段时,不仅要声明数据类型,还要声明各种特性来定义数据的具体存储方式:字段是否可排序,是否可投影,是否已分析以及使用哪个分析器等。
由于这种复杂性,当必须在各种绑定器(ValueBinder、PropertyBinder、TypeBinder)中定义字段类型时,可以使用专门的 DSL 来定义它们。
该 DSL 的入口点是 IndexFieldTypeFactory。类型工厂通常可以通过传递给绑定器的上下文对象来访问(context.typeFactory())。在 PropertyBinder 和 TypeBinder 的情况下,也可以将类型工厂传递给传递给 field 方法的 lambda 表达式,以便内联定义字段类型。
类型工厂公开了各种 as*() 方法,例如 asString 或 asLocalDate。这些是类型定义 DSL 的第一步,其中定义了数据类型。它们会返回其他步骤,从中可以设置选项,例如分析器。请参阅下面的示例。
IndexFieldType<String> type = context.typeFactory() (1)
.asString() (2)
.normalizer( "isbn" ) (3)
.sortable( Sortable.YES ) (3)
.toIndexFieldType(); (4)| 1 | 从绑定上下文获取 IndexFieldTypeFactory。 |
| 2 | 定义数据类型。 |
| 3 | 定义选项。可用的选项因字段类型而异:例如,normalizer 可用于 String 字段,但不可用于 Double 字段。 |
| 4 | 获取索引字段类型。 |
|
在 在传递给 字段声明 DSL 的 |
12.9.2. 可用的数据类型
所有可用的数据类型在 IndexFieldTypeFactory 中都具有专门的 as*() 方法。有关详细信息,请参阅 IndexFieldTypeFactory 的 javadoc 或特定于后端的文档。
12.9.4. DSL 转换器
|
本部分与 |
各种搜索 DSL 公开了某些期望字段值的方法:matching()、between()、atMost()、missingValue().use() 等。默认情况下,期望类型将与数据类型相同,即如果调用了 asString() 则为 String,如果调用了 asLocalDate() 则为 LocalDate 等。
当桥接器在索引时从不同的类型转换值时,这可能会很烦人。例如,如果桥接器在索引时将枚举转换为字符串,则可能不希望将字符串传递给搜索谓词,而是传递枚举。
通过在字段类型上设置 DSL 转换器,可以更改传递给各种 DSL 的值的预期类型,请参见下面的示例。
IndexFieldType<String> type = context.typeFactory()
.asString() (1)
.normalizer( "isbn" )
.sortable( Sortable.YES )
.dslConverter( (2)
ISBN.class, (3)
(value, convertContext) -> value.getStringValue() (4)
)
.toIndexFieldType();| 1 | 将数据类型定义为 String。 |
| 2 | 定义一个从 ISBN 转换为 String 的 DSL 转换器。此转换器将被搜索 DSL 透明地使用。 |
| 3 | 通过将 ISBN.class 作为第一个参数传递,将输入类型定义为 ISBN。 |
| 4 | 通过将转换器作为第二个参数传递,定义如何将 ISBN 转换为 String。 |
ISBN expectedISBN = /* ... */
List<Book> result = searchSession.search( Book.class )
.where( f -> f.match().field( "isbn" )
.matching( expectedISBN ) ) (1)
.fetchHits( 20 );| 1 | 由于 DSL 转换器,默认情况下,针对使用我们类型的字段的谓词接受 ISBN 值。 |
| 如果需要,可以在各种 DSL 中禁用 DSL 转换器。请参见 传递给 DSL 的参数类型。 |
12.9.5. 投影转换器
|
本节与 |
默认情况下,字段投影 或 聚合 返回的值类型将与相应字段的数据类型相同,例如,如果调用了 asString(),则为 String;如果调用了 asLocalDate(),则为 LocalDate,等等。
当桥接在索引时将值从不同类型转换而来时,这可能会让人感到困扰。例如,如果桥接在索引时将枚举转换为字符串,那么您可能不希望投影返回字符串,而是枚举。
通过在字段类型上设置投影转换器,可以更改字段投影或聚合返回的值类型。请参见下面的示例。
IndexFieldType<String> type = context.typeFactory()
.asString() (1)
.projectable( Projectable.YES )
.projectionConverter( (2)
ISBN.class, (3)
(value, convertContext) -> ISBN.parse( value ) (4)
)
.toIndexFieldType();| 1 | 将数据类型定义为 String。 |
| 2 | 定义一个从 String 转换为 ISBN 的投影转换器。此转换器将被搜索 DSL 透明地使用。 |
| 3 | 通过将 ISBN.class 作为第一个参数传递,将转换后的类型定义为 ISBN。 |
| 4 | 通过将转换器作为第二个参数传递,定义如何将 String 转换为 ISBN。 |
List<ISBN> result = searchSession.search( Book.class )
.select( f -> f.field( "isbn", ISBN.class ) ) (1)
.where( f -> f.matchAll() )
.fetchHits( 20 );| 1 | 由于投影转换器,默认情况下,使用我们类型的字段被投影为 ISBN。 |
| 如果需要,可以在投影 DSL 中禁用投影转换器。请参见 投影值的类型。 |
12.10. 定义命名谓词
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
在实现 PropertyBinder 或 TypeBinder 时,可以将“命名谓词”分配给索引模式元素(索引根或 对象字段)。
然后,这些命名谓词可以通过 搜索 DSL 使用,通过名称引用它们,并可以选择传递参数。主要点是,实现对调用者隐藏:他们不需要了解数据的索引方式即可使用命名谓词。
下面是一个使用 DSL 在属性绑定器中声明对象字段并将命名谓词分配给该字段的简单示例。
/**
* A binder for Stock Keeping Unit (SKU) identifiers, i.e. Strings with a specific format.
*/
public class SkuIdentifierBinder implements PropertyBinder {
@Override
public void bind(PropertyBindingContext context) {
context.dependencies().useRootOnly();
IndexSchemaObjectField skuIdObjectField = context.indexSchemaElement()
.objectField( context.bridgedElement().name() );
IndexFieldType<String> skuIdPartType = context.typeFactory()
.asString().normalizer( "lowercase" ).toIndexFieldType();
context.bridge( String.class, new Bridge(
skuIdObjectField.toReference(),
skuIdObjectField.field( "departmentCode", skuIdPartType ).toReference(),
skuIdObjectField.field( "collectionCode", skuIdPartType ).toReference(),
skuIdObjectField.field( "itemCode", skuIdPartType ).toReference()
) );
skuIdObjectField.namedPredicate( (1)
"skuIdMatch", (2)
new SkuIdentifierMatchPredicateDefinition() (3)
);
}
// ... class continues below| 1 | 绑定器定义了一个命名谓词。请注意,此谓词分配给对象字段。 |
| 2 | 谓词名称将用于在 调用命名谓词 时引用此谓词。由于谓词分配给对象字段,因此调用者必须在谓词名称前加上该对象字段的路径。 |
| 3 | 谓词定义将定义在搜索时如何创建谓词。 |
// ... class SkuIdentifierBinder (continued)
private static class Bridge implements PropertyBridge<String> { (1)
private final IndexObjectFieldReference skuIdObjectField;
private final IndexFieldReference<String> departmentCodeField;
private final IndexFieldReference<String> collectionCodeField;
private final IndexFieldReference<String> itemCodeField;
private Bridge(IndexObjectFieldReference skuIdObjectField,
IndexFieldReference<String> departmentCodeField,
IndexFieldReference<String> collectionCodeField,
IndexFieldReference<String> itemCodeField) {
this.skuIdObjectField = skuIdObjectField;
this.departmentCodeField = departmentCodeField;
this.collectionCodeField = collectionCodeField;
this.itemCodeField = itemCodeField;
}
@Override
public void write(DocumentElement target, String skuId, PropertyBridgeWriteContext context) {
DocumentElement skuIdObject = target.addObject( this.skuIdObjectField );(2)
// An SKU identifier is formatted this way: "<department code>.<collection code>.<item code>".
String[] skuIdParts = skuId.split( "\\." );
skuIdObject.addValue( this.departmentCodeField, skuIdParts[0] ); (3)
skuIdObject.addValue( this.collectionCodeField, skuIdParts[1] ); (3)
skuIdObject.addValue( this.itemCodeField, skuIdParts[2] ); (3)
}
}
// ... class continues below| 1 | 这里桥梁类嵌套在绑定程序类中,因为这样更方便,但您可以自由地根据需要实现它:作为 lambda 表达式,在单独的 Java 文件中等等。 |
| 2 | 桥接创建了一个对象来保存 SKU 标识符的各个组成部分。 |
| 3 | 桥接填充了 SKU 标识符的各个组成部分。 |
// ... class SkuIdentifierBinder (continued)
private static class SkuIdentifierMatchPredicateDefinition implements PredicateDefinition { (1)
@Override
public SearchPredicate create(PredicateDefinitionContext context) {
SearchPredicateFactory f = context.predicate(); (2)
String pattern = context.params().get( "pattern", String.class ); (3)
return f.and().with( and -> { (4)
// An SKU identifier pattern is formatted this way: "<department code>.<collection code>.<item code>".
// Each part supports * and ? wildcards.
String[] patternParts = pattern.split( "\\." );
if ( patternParts.length > 0 ) {
and.add( f.wildcard()
.field( "departmentCode" ) (5)
.matching( patternParts[0] ) );
}
if ( patternParts.length > 1 ) {
and.add( f.wildcard()
.field( "collectionCode" )
.matching( patternParts[1] ) );
}
if ( patternParts.length > 2 ) {
and.add( f.wildcard()
.field( "itemCode" )
.matching( patternParts[2] ) );
}
} ).toPredicate(); (6)
}
}
}| 1 | 谓词定义必须实现 PredicateDefinition 接口。这里,谓词定义类嵌套在绑定器类中,因为这样更方便,但显然您可以自由地在单独的 Java 文件中实现它。 |
| 2 | 传递给定义的上下文公开了谓词工厂,它是 谓词 DSL 的入口点,用于创建谓词。 |
| 3 | 定义可以访问在调用命名谓词时传递的参数。 如果未定义参数,则 |
| 4 | 定义使用谓词工厂创建谓词。在此示例中,此实现将具有自定义格式的模式转换为三个模式,每个模式对应于桥接填充的每个字段。 |
| 5 | 注意:搜索谓词工厂期望相对于注册命名谓词的对象字段的路径。这里,路径 departmentCode 将被理解为 <path to the object field>.departmentCode。另请参见 字段路径。 |
| 6 | 不要忘记调用 toPredicate() 以返回 SearchPredicate 实例。 |
@Entity
@Indexed
public class ItemStock {
@Id
@PropertyBinding(binder = @PropertyBinderRef(type = SkuIdentifierBinder.class)) (1)
private String skuId;
private int amountInStock;
// Getters and setters
// ...
}| 1 | 使用 @PropertyBinding 注释应用桥接。谓词将在搜索 DSL 中可用,如 named:调用映射中定义的谓词 中所示。 |
12.11. 使用桥接解析器分配默认桥接
12.11.1. 基础
@*Field 注释和 @DocumentId 注释都默认支持广泛的标准类型,无需告诉 Hibernate Search 如何将值转换为可以索引的内容。
在幕后,对默认类型的支持由桥接解析器处理。例如,当使用 @GenericField 映射属性并且未设置 @GenericField.valueBridge 或 @GenericField.valueBinder 时,Hibernate Search 将解析此属性的类型,然后将其传递给桥接解析器,桥接解析器将返回一个合适的桥接,如果没有合适的桥接,则会失败。
可以自定义桥接解析器,以覆盖现有的默认桥接(例如,以不同的方式索引 java.util.Date),或为其他类型定义默认桥接(例如,来自外部库的地理空间类型)。
为此,请定义一个映射配置器,如 程序化映射 中所述,然后按如下所示定义桥接
public class MyDefaultBridgesConfigurer implements HibernateOrmSearchMappingConfigurer {
@Override
public void configure(HibernateOrmMappingConfigurationContext context) {
context.bridges().exactType( MyCoordinates.class )
.valueBridge( new MyCoordinatesBridge() ); (1)
context.bridges().exactType( MyProductId.class )
.identifierBridge( new MyProductIdBridge() ); (2)
context.bridges().exactType( ISBN.class )
.valueBinder( new ValueBinder() { (3)
@Override
public void bind(ValueBindingContext<?> context) {
context.bridge( ISBN.class, new ISBNValueBridge(),
context.typeFactory().asString().normalizer( "isbn" ) );
}
} );
}
}| 1 | 当类型为 MyCoordinates 的属性映射到索引字段(例如,使用 @GenericField)时,默认情况下使用我们的自定义桥接 (MyCoordinatesBridge)。 |
| 2 | 当类型为 MyProductId 的属性映射到文档标识符(例如,使用 @DocumentId)时,默认情况下使用我们的自定义桥接 (MyProductBridge)。 |
| 3 | 也可以指定绑定器而不是桥接,以便可以调整其他设置。这里,每次将 ISBN 映射到索引字段时,我们都会分配“isbn”规范化器。 |
12.11.2. 将单个绑定器分配给多个类型
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
对于更高级的用例,也可以将单个绑定器分配给给定类型的子类型。当许多类型应该以类似的方式索引时,这很有用。
以下是一个示例,其中枚举不会像它们的 .name()(这是默认设置)那样索引,而是像从外部服务检索的标签那样索引。
context.bridges().subTypesOf( Enum.class ) (1)
.valueBinder( new ValueBinder() {
@Override
public void bind(ValueBindingContext<?> context) {
Class<?> enumType = context.bridgedElement().rawType(); (2)
doBind( context, enumType );
}
private <T> void doBind(ValueBindingContext<?> context, Class<T> enumType) {
BeanHolder<EnumLabelService> serviceHolder = context.beanResolver()
.resolve( EnumLabelService.class, BeanRetrieval.ANY ); (3)
context.bridge(
enumType,
new EnumLabelBridge<>( enumType, serviceHolder )
); (4)
}
} );| 1 | 匹配 Enum 的所有子类型。 |
| 2 | 检索正在桥接的元素的类型. |
| 3 | 检索外部服务(通过 CDI/Spring)。 |
| 4 | 创建并分配桥接。 |
12.12. 投影绑定器
12.12.1. 基础
投影绑定器是一个高级功能,应用程序开发人员通常不需要担心它。在诉诸自定义投影绑定器之前,请考虑依赖 显式投影构造函数参数映射,使用内置注释,例如 @IdProjection、@FieldProjection、@ObjectProjection,等等。 |
投影绑定器可以检查构造函数参数,并期望将投影定义分配给该构造函数参数,以便每当调用 投影构造函数 时,Hibernate Search 都会将该投影的结果通过该构造函数参数传递。
实现投影绑定器需要两个组件
-
ProjectionBinder的自定义实现,用于在引导时将投影定义绑定到参数。这涉及根据需要检查构造函数参数,并实例化投影定义。 -
ProjectionDefinition的自定义实现,用于在运行时实例化投影。这涉及使用 投影 DSL 并返回生成的SearchProjection。
下面是一个自定义投影绑定器的示例,它将类型为 String 的参数绑定到索引中 title 字段的投影。
| 无需自定义投影绑定器即可获得类似的结果。这只是为了使示例保持简单。 |
ProjectionBinderpublic class MyFieldProjectionBinder implements ProjectionBinder { (1)
@Override
public void bind(ProjectionBindingContext context) { (2)
context.definition( (3)
String.class, (4)
new MyProjectionDefinition() (5)
);
}
// ... class continues below| 1 | 绑定器必须实现 ProjectionBinder 接口。 |
| 2 | 在绑定器中实现 bind 方法。 |
| 3 | 调用 context.definition(…) 以定义要使用的投影。 |
| 4 | 传递构造函数参数的预期类型。 |
| 5 | 传递投影定义实例,该实例将在运行时创建投影。 |
// ... class MyFieldProjectionBinder (continued)
private static class MyProjectionDefinition (1)
implements ProjectionDefinition<String> { (2)
@Override
public SearchProjection<String> create(SearchProjectionFactory<?, ?> factory,
ProjectionDefinitionContext context) {
return factory.field( "title", String.class ) (3)
.toProjection(); (4)
}
}
}| 1 | 这里,定义类嵌套在绑定器类中,因为这样更方便,但显然您可以自由地按您希望的方式实现它:作为 lambda 表达式,在单独的 Java 文件中,等等。 |
| 2 | 定义必须实现 ProjectionDefinition 接口。必须提供一个泛型类型参数:投影值的类型,即构造函数参数的类型。 |
| 3 | 使用提供的 SearchProjectionFactory 和 投影 DSL 来定义适当的投影。 |
| 4 | 通过调用 .toProjection() 获取生成的投影并返回它。 |
@ProjectionConstructor
public record MyBookProjection(
@ProjectionBinding(binder = @ProjectionBinderRef( (1)
type = MyFieldProjectionBinder.class
))
String title) {
}| 1 | 使用 @ProjectionBinding 注释应用绑定器。 |
然后,图书投影可以用作任何 自定义投影类型,并且它的 title 参数将使用自定义投影定义返回的值进行初始化。
List<MyBookProjection> hits = searchSession.search( Book.class )
.select( MyBookProjection.class )
.where( f -> f.matchAll() )
.fetchHits( 20 );12.12.2. 多值投影
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
您可以在传递给投影绑定器的上下文中调用 .multi(),以发现正在绑定的构造函数参数是否为多值(根据与 隐式内部投影推断 相同的规则),并绑定多值投影。
ProjectionBinderpublic class MyFieldProjectionBinder implements ProjectionBinder {
@Override
public void bind(ProjectionBindingContext context) {
Optional<? extends ProjectionBindingMultiContext> multi = context.multi(); (1)
if ( multi.isPresent() ) {
multi.get().definition( String.class, new MyProjectionDefinition() ); (2)
}
else {
throw new RuntimeException( "This binder only supports multi-valued constructor parameters" ); (3)
}
}
private static class MyProjectionDefinition
implements ProjectionDefinition<List<String>> { (4)
@Override
public SearchProjection<List<String>> create(SearchProjectionFactory<?, ?> factory,
ProjectionDefinitionContext context) {
return factory.field( "tags", String.class )
.multi() (4)
.toProjection();
}
}
}| 1 | multi() 返回一个可选值,该可选值仅当构造函数参数被视为多值时才包含上下文。 |
| 2 | 调用 multi.definition(…) 以定义要使用的投影。 |
| 3 | 这里,我们在处理单值构造函数参数时遇到了失败,但理论上我们可以回退到单值投影。 |
| 4 | 投影定义,作为多值定义,必须实现 ProjectionDefinition<List<T>>,其中 T 是预期投影值的类型,并且必须相应地配置返回的投影。 |
@ProjectionConstructor
public record MyBookProjection(
@ProjectionBinding(binder = @ProjectionBinderRef( (1)
type = MyFieldProjectionBinder.class
))
List<String> tags) {
}| 1 | 使用 @ProjectionBinding 注释应用绑定器。 |
然后,书籍投影可以用作任何 自定义投影类型,它的 tags 参数将使用自定义投影定义返回的值进行初始化。
List<MyBookProjection> hits = searchSession.search( Book.class )
.select( MyBookProjection.class )
.where( f -> f.matchAll() )
.fetchHits( 20 );12.12.3. 组合投影构造函数
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
你可以在传递给投影绑定器的上下文中调用 .createObjectDefinition( "someFieldPath", SomeType.class ),以根据 SomeType 的 投影构造函数映射 检索 对象投影 的定义。
这实际上允许在投影绑定器中使用投影构造函数,只需将生成的定义传递给 .definition(…),或在自定义投影定义中委托给它。
绑定上下文中公开的其他方法的工作方式类似。
下面是一个使用 .createObjectDefinition(…) 委托给另一个投影构造函数的示例。
在没有自定义投影绑定器的情况下也可以实现类似的结果,只需依靠 隐式内部投影推断 或使用 @ObjectProjection。这只是为了使示例更简单。 |
ProjectionBinderpublic class MyObjectFieldProjectionBinder implements ProjectionBinder {
@Override
public void bind(ProjectionBindingContext context) {
var authorProjection = context.createObjectDefinition( (1)
"author", (2)
MyBookProjection.MyAuthorProjection.class, (3)
TreeFilterDefinition.includeAll() (4)
);
context.definition( (5)
MyBookProjection.MyAuthorProjection.class,
authorProjection
);
}
}| 1 | 调用 createObjectDefinition(…) 来创建要委托给的定义。 |
| 2 | 传递要投影的 对象字段的名称。 |
| 3 | 传递 投影类型。 |
| 4 | 传递嵌套投影的过滤器;这里我们没有过滤。这控制与 @ObjectProjection 中的 includePaths/excludePaths/includeDepths 相同的功能。 |
| 5 | 调用 definition(…) 并传递刚刚创建的定义。 |
@ProjectionConstructor
public record MyBookProjection(
@ProjectionBinding(binder = @ProjectionBinderRef( (1)
type = MyObjectFieldProjectionBinder.class
))
MyAuthorProjection author) {
@ProjectionConstructor (2)
public record MyAuthorProjection(String name) {
}
}| 1 | 使用 @ProjectionBinding 注释应用绑定器。 |
| 2 | 确保传递给 createObjectDefinition(…) 的投影类型具有投影构造函数。 |
然后,书籍投影可以用作任何 自定义投影类型,它的 author 参数将使用自定义投影定义返回的值进行初始化。
List<MyBookProjection> hits = searchSession.search( Book.class )
.select( MyBookProjection.class )
.where( f -> f.matchAll() )
.fetchHits( 20 );12.12.4. 传递参数
有两种方法可以将参数传递给属性桥接。
-
一种方法(主要)限于字符串参数,但实现起来很简单。
-
另一种方法可以允许任何类型的参数,但需要您声明自己的注解。
简单的字符串参数
你可以将字符串参数传递给 @ProjectionBinderRef 注解,然后在绑定器中使用它们。
@ProjectionBinderRef 注解将参数传递给 ProjectionBinderpublic class MyFieldProjectionBinder implements ProjectionBinder {
@Override
public void bind(ProjectionBindingContext context) {
String fieldName = context.param( "fieldName", String.class ); (1)
context.definition(
String.class,
new MyProjectionDefinition( fieldName ) (2)
);
}
private static class MyProjectionDefinition
implements ProjectionDefinition<String> {
private final String fieldName;
public MyProjectionDefinition(String fieldName) { (2)
this.fieldName = fieldName;
}
@Override
public SearchProjection<String> create(SearchProjectionFactory<?, ?> factory,
ProjectionDefinitionContext context) {
return factory.field( fieldName, String.class ) (3)
.toProjection();
}
}
}| 1 | 使用绑定上下文获取参数值。 如果未定义参数,则 |
| 2 | 将参数值作为参数传递给定义构造函数。 |
| 3 | 在投影定义中使用参数值。 |
@ProjectionConstructor
public record MyBookProjection(
@ProjectionBinding(binder = @ProjectionBinderRef(
type = MyFieldProjectionBinder.class,
params = @Param( name = "fieldName", value = "title" )
)) String title) { (1)
}| 1 | 定义要应用于构造函数参数的绑定器,设置 fieldName 参数。 |
带有自定义注解的参数
您可以通过定义具有属性的 自定义注解 将任何类型的参数传递给桥接。
PropertyBinder@Retention(RetentionPolicy.RUNTIME) (1)
@Target({ ElementType.PARAMETER }) (2)
@MethodParameterMapping(processor = @MethodParameterMappingAnnotationProcessorRef( (3)
type = MyFieldProjectionBinding.Processor.class
))
@Documented (4)
public @interface MyFieldProjectionBinding {
String fieldName() default ""; (5)
class Processor (6)
implements MethodParameterMappingAnnotationProcessor<MyFieldProjectionBinding> { (7)
@Override
public void process(MethodParameterMappingStep mapping, MyFieldProjectionBinding annotation,
MethodParameterMappingAnnotationProcessorContext context) {
MyFieldProjectionBinder binder = new MyFieldProjectionBinder(); (8)
if ( !annotation.fieldName().isEmpty() ) { (9)
binder.fieldName( annotation.fieldName() );
}
mapping.projection( binder ); (10)
}
}
}| 1 | 定义一个具有 RUNTIME 保留策略的注解。任何其他保留策略都将导致 Hibernate Search 忽略该注解。 |
| 2 | 由于我们将把投影定义映射到投影构造函数,因此允许注解针对方法参数(构造函数是方法)。 |
| 3 | 将此注解标记为方法参数映射,并指示 Hibernate Search 在找到此注解时应用给定的处理器。也可以通过 CDI/Spring Bean 名称引用处理器。 |
| 4 | 可选地,将注解标记为已记录,以便将其包含在实体的 javadoc 中。 |
| 5 | 定义一个类型为 String 的属性来指定字段名称。 |
| 6 | 这里处理器类嵌套在注解类中,因为这样更方便,但您可以自由地在单独的 Java 文件中实现它。 |
| 7 | 处理器必须实现 MethodParameterMappingAnnotationProcessor 接口,并将泛型类型参数设置为对应注解的类型。 |
| 8 | 在注解处理器中,实例化绑定器。 |
| 9 | 处理注解属性并将数据传递给绑定器。 这里我们使用的是 setter,但通过构造函数传递数据也可以。 |
| 10 | 将绑定器应用于构造函数参数。 |
public class MyFieldProjectionBinder implements ProjectionBinder {
private String fieldName = "name";
public MyFieldProjectionBinder fieldName(String fieldName) { (1)
this.fieldName = fieldName;
return this;
}
@Override
public void bind(ProjectionBindingContext context) {
context.definition(
String.class,
new MyProjectionDefinition( fieldName ) (2)
);
}
private static class MyProjectionDefinition
implements ProjectionDefinition<String> {
private final String fieldName;
public MyProjectionDefinition(String fieldName) { (2)
this.fieldName = fieldName;
}
@Override
public SearchProjection<String> create(SearchProjectionFactory<?, ?> factory,
ProjectionDefinitionContext context) {
return factory.field( fieldName, String.class ) (3)
.toProjection();
}
}
}| 1 | 在绑定器中实现 setter。或者,我们可以公开一个参数化的构造函数。 |
| 2 | 在 bind 方法中,使用参数的值。这里,我们将参数值作为参数传递给定义构造函数。 |
| 3 | 在投影定义中使用参数值。 |
@ProjectionConstructor
public record MyBookProjection(
@MyFieldProjectionBinding(fieldName = "title") (1)
String title) {
}| 1 | 使用自定义注解应用绑定器,设置 fieldName 参数。 |
12.12.5. 将 Bean 注入绑定器
使用 兼容框架,Hibernate Search 支持将 Bean 注入
-
如果你使用 自定义注解,则使用
MethodParameterMappingAnnotationProcessor。 -
如果你使用
@ProjectionBinding注解,则使用ProjectionBinder。
这仅适用于通过 Hibernate Search 的bean 解析实例化的 bean。作为经验法则,如果您需要在某个时刻显式调用new MyBinder(),则绑定器不会自动注入。 |
传递给属性绑定器bind方法的上下文还公开了一个beanResolver()方法,用于访问 bean 解析器并显式实例化 bean。
有关详细信息,请参阅 Bean 注入。
12.12.6. 程序化映射
你也可以通过 程序化映射 应用投影绑定器。只需将绑定器的实例传递给 .projection(…)。你可以通过绑定器的构造函数或 setter 传递参数。
.projection(…) 应用 ProjectionBinderTypeMappingStep myBookProjectionMapping = mapping.type( MyBookProjection.class );
myBookProjectionMapping.mainConstructor().projectionConstructor();
myBookProjectionMapping.mainConstructor().parameter( 0 )
.projection( new MyFieldProjectionBinder().fieldName( "title" ) );12.12.7. 其他孵化功能
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
传递给投影绑定器 bind 方法的上下文公开了 constructorParameter() 方法,该方法提供对正在绑定的构造函数参数的元数据的访问。
元数据可用于详细检查构造函数参数。
-
获取构造函数参数的名称。
-
检查构造函数参数的类型。
类似地,用于多值投影绑定的上下文 公开了 containerElement() 方法,该方法提供对(多值)构造函数参数类型的元素类型的访问。
有关更多信息,请参阅 javadoc。
|
构造函数参数的名称仅在以下情况下可用
|
下面是一个使用此元数据的最简单示例,获取构造函数参数名称并将其用作字段名称。
ProjectionBinder 中将名称与构造函数参数名称相同的字段进行投影public class MyFieldProjectionBinder implements ProjectionBinder {
@Override
public void bind(ProjectionBindingContext context) {
var constructorParam = context.constructorParameter(); (1)
context.definition(
String.class,
new MyProjectionDefinition( constructorParam.name().orElseThrow() ) (2)
);
}
private static class MyProjectionDefinition
implements ProjectionDefinition<String> {
private final String fieldName;
private MyProjectionDefinition(String fieldName) {
this.fieldName = fieldName;
}
@Override
public SearchProjection<String> create(SearchProjectionFactory<?, ?> factory,
ProjectionDefinitionContext context) {
return factory.field( fieldName, String.class ) (3)
.toProjection();
}
}
}| 1 | 使用绑定上下文获取构造函数参数。 |
| 2 | 将构造函数参数的名称传递给投影定义。 |
| 3 | 将构造函数参数的名称用作投影字段名称。 |
@ProjectionConstructor
public record MyBookProjection(
@ProjectionBinding(binder = @ProjectionBinderRef( (1)
type = MyFieldProjectionBinder.class
))
String title) {
}| 1 | 使用 @ProjectionBinding 注释应用绑定器。 |
13. 管理索引模式
13.1. 基础
在索引可用于索引或搜索之前,必须在磁盘(Lucene)或远程集群(Elasticsearch)上创建它们。特别是使用 Elasticsearch 时,此创建可能并不明显,因为它需要描述每个索引的模式,其中特别包括
-
在此索引中使用的每个分析器或规范化的定义;
-
在此索引中使用的每个字段的定义,特别是包括其类型、分配给它的分析器、是否需要文档值等。
Hibernate Search 拥有生成此模式所需的所有信息,因此可以将管理模式的任务委托给 Hibernate Search。
13.2. 启动/关闭时的自动模式管理
属性 hibernate.search.schema_management.strategy 可以设置为以下值之一,以定义在启动和关闭时如何处理索引及其模式。
| 策略 | 定义 | 警告 |
|---|---|---|
在启动或关闭时不执行任何操作的策略。 索引及其模式不会在启动或关闭时创建或删除。Hibernate Search **甚至不会检查** 索引是否实际存在。 |
使用 Elasticsearch 时,必须在启动之前显式创建索引及其模式。 |
|
不更改索引或其模式的策略,但在启动时检查索引是否存在并验证其模式。 如果以下情况发生,将在启动时抛出异常:
“兼容”差异(例如额外的字段 会被忽略)。 |
必须在启动之前显式创建索引及其模式。 使用 Lucene 后端时,验证仅限于检查索引是否存在,因为 本地 Lucene 索引没有模式。 |
|
仅在 Elasticsearch 后端中,如果一些索引已存在,但其模式与 Hibernate Search 映射的要求不匹配,则将在启动时抛出异常:缺少字段、字段类型错误、缺少分析器定义或规范化定义等。 “兼容”差异(例如额外的字段 会被忽略)。 |
使用 Lucene 后端时,验证仅限于检查索引是否存在,因为 本地 Lucene 索引没有模式。 |
|
此策略不适合生产环境,因为它存在几个限制,包括 无法更改现有字段的类型 或 需要在更新分析器定义时关闭索引(这在 AWS 上完全不可能)。 使用 Lucene 后端时,模式更新是无操作,因为 本地 Lucene 索引没有模式。 |
||
在启动时删除现有索引,重新创建它们及其模式的策略。 |
所有索引数据都将在 启动时丢失。 |
|
在启动时删除现有索引,重新创建它们及其模式的策略,然后在关闭时删除索引。 |
所有索引数据都将在 启动和关闭时丢失。 |
13.3. 手动模式管理
模式管理不必在启动和关闭时自动进行。
使用 SearchSchemaManager 接口,可以显式地触发模式管理操作,Hibernate Search 启动后。
|
最常见的用例是将 自动模式管理策略 设置为 在模式管理操作完成后,你通常需要填充索引。为此,请使用 批量索引器。 |
SearchSchemaManager 接口公开了以下方法。
| 方法 | 定义 | 警告 |
|---|---|---|
不更改索引或其模式,但检查索引是否存在并验证其模式。 |
使用 Lucene 后端时,验证仅限于检查索引是否存在,因为 本地 Lucene 索引没有模式。 |
|
创建缺失的索引及其模式,但不触碰现有索引,并假设它们的模式正确,而无需验证。 |
||
创建缺失的索引及其模式,并验证现有索引的模式。 |
使用 Lucene 后端时,验证仅限于检查索引是否存在,因为 本地 Lucene 索引没有模式。 |
|
创建缺少的索引及其架构,并尽可能更新现有索引的架构。 |
使用 Elasticsearch 后端时,更新架构可能会失败。 使用 Elasticsearch 后端时,更新架构可能会在更新分析器定义时关闭索引(在 Amazon OpenSearch 服务 上完全不可能)。 使用 Lucene 后端时,架构更新是一个空操作,因为 本地 Lucene 索引没有架构。(它只是创建缺少的索引)。 |
|
删除现有索引。 |
||
删除现有索引并重新创建它们及其架构。 |
以下示例使用 SearchSchemaManager 删除并创建索引,然后使用 批量索引器 重新填充索引。 批量索引器的 dropAndCreateSchemaOnStart 设置 将是实现相同结果的另一种解决方案。
SearchSchemaManager 重新初始化索引SearchSession searchSession = /* ... */ (1)
SearchSchemaManager schemaManager = searchSession.schemaManager(); (2)
schemaManager.dropAndCreate(); (3)
searchSession.massIndexer()
.purgeAllOnStart( false )
.startAndWait(); (4)| 1 | 检索 SearchSession. |
| 2 | 获取架构管理器。 |
| 3 | 删除并创建索引。此方法是同步的,只有在操作完成后才会返回。 |
| 4 | 可选地,触发 批量索引。 |
您也可以在创建架构管理器时选择实体类型,以仅管理这些类型的索引(以及它们的索引子类型,如果有)。
SearchSchemaManager 仅重新初始化某些索引SearchSchemaManager schemaManager = searchSession.schemaManager( Book.class ); (1)
schemaManager.dropAndCreate(); (2)| 1 | 获取针对映射到 Book 实体类型的索引的架构管理器。 |
| 2 | 仅删除并创建 Book 实体的索引。其他索引不受影响。 |
13.4. 架构管理的工作原理
这是设计使然:重新索引是一个可能很耗时的任务,应该显式触发。要使用数据库中的预先存在数据填充索引,请使用 批量索引。
- 删除架构意味着丢失索引数据
-
删除架构将删除整个索引,包括所有索引数据。
已删除的索引需要通过架构管理重新创建,然后通过 批量索引 使用数据库中的预先存在数据填充。
- 架构更新可能会失败
-
由
create-or-update策略触发的架构更新可能会简单地失败。这是因为架构可能以不兼容的方式发生更改,例如字段的类型发生更改或其分析器发生更改等。更糟糕的是,由于更新是在每个索引的基础上处理的,因此架构更新可能对一个索引成功,但对另一个索引失败,导致您的整个架构半更新。
出于这些原因,**不建议在生产环境中使用架构更新**。只要架构发生更改,您应该要么
-
删除并创建索引,然后 重新索引。
-
或者通过自定义脚本手动更新架构。
在这种情况下,
create-or-update策略将阻止 Hibernate Search 启动,但它可能已经成功为另一个索引更新了架构,从而使回滚变得困难。 -
- Elasticsearch 上的架构更新可能会关闭索引
-
Elasticsearch 不允许在打开的索引上更新分析器/规范器定义。因此,当架构更新需要更新分析器或规范器定义时,Hibernate Search 将暂时停止受影响的索引。
出于这个原因,当多个客户端使用由 Hibernate Search 管理的 Elasticsearch 索引时,应谨慎使用
create-or-update策略:这些客户端应以一种方式同步,即在 Hibernate Search 启动时,没有其他客户端需要访问索引。此外,在运行 Elasticsearch(而不是 OpenSearch)版本 7.1 或更早版本的 Amazon OpenSearch 服务 以及在 Amazon OpenSearch Serverless 上,
_close/_open操作不受支持,因此**当尝试更新分析器定义时,架构更新将失败**。唯一的解决方法是避免在这些平台上进行架构更新。无论如何,它应该在生产环境中避免:请参见 [schema-management-concepts-update-failure]。
13.5. 导出架构
13.5.1. 将架构导出到一组文件
架构管理器 提供了一种将架构导出到文件系统的方法。输出是特定于后端的。
|
架构导出是根据映射信息和配置(例如,后端版本)构建的。生成的导出不会与实际的后端架构进行比较或验证。 |
对于 Elasticsearch,这些文件提供了创建索引(以及它们的设置和映射)所需的必要信息。导出文件树结构如下所示
# For the default backend the index schema will be written to:
.../backend/indexes/<index-name>/create-index.json
.../backend/indexes/<index-name>/create-index-query-params.json
# For additional named backends:
.../backends/<name of a particular backend>/indexes/<index-name>/create-index.json
.../backends/<name of a particular backend>/indexes/<index-name>/create-index-query-params.jsonSearchSchemaManager schemaManager = searchSession.schemaManager(); (1)
schemaManager.exportExpectedSchema( targetDirectory ); (2)| 1 | 从 SearchSession 中检索 SearchSchemaManager。 |
| 2 | 将架构导出到目标目录。 |
13.5.2. 导出到自定义收集器
搜索架构管理器 允许根据这些管理器包含的数据遍历架构导出。为此,必须实现一个 SearchSchemaCollector 并将其传递给架构管理器的 exportExpectedSchema(..) 方法。
|
架构导出是根据映射信息和配置(例如,后端版本)构建的。生成的导出不会与实际的后端架构进行比较或验证。 |
SearchSchemaManager schemaManager = searchSession.schemaManager(); (1)
schemaManager.exportExpectedSchema(
new SearchSchemaCollector() { (2)
@Override
public void indexSchema(Optional<String> backendName, String indexName, SchemaExport export) {
String name = backendName.orElse( "default" ) + ":" + indexName; (3)
// perform any other actions with an index schema export
}
}
);| 1 | 从 SearchSession 中检索 SearchSchemaManager。 |
| 2 | 实例化并传递 SearchSchemaCollector 以遍历架构。 |
| 3 | 从索引和后端名称创建名称。 |
|
要访问特定于后端的功能,可以应用对
|
14. 索引实体
14.1. 基础
在 Hibernate Search 中有多种方法可以索引实体。
如果您想了解最受欢迎的方法,请直接前往下一节。
-
要透明地保持索引同步,因为实体在 Hibernate ORM
Session中发生了更改,请参见 监听器触发的索引。 -
要索引大量数据——例如在将 Hibernate Search 添加到现有应用程序时索引整个数据库——请参见
MassIndexer。
否则,以下表格可能有助于您确定最适合您的用例的方法。
| 名称和链接 | 用例 | API | 映射器 |
|---|---|---|---|
处理应用程序事务中的增量更改 |
无:隐式工作,无需 API 调用 |
仅支持 Hibernate ORM 集成 |
|
以批次重新索引大量数据 |
特定于 Hibernate Search |
||
Jakarta EE 标准 |
仅支持 Hibernate ORM 集成 |
||
其他任何事情 |
特定于 Hibernate Search |
14.2. 索引计划
14.2.1. 基础
索引计划不用于 MassIndexer 或 Jakarta Batch 批量索引作业:这些假设它们处理的所有实体都需要被索引,并且不需要索引计划更微妙的机制。 |
以下是索引计划在高层次上如何工作的。
-
当应用程序执行实体更改时,实体更改事件(实体创建、更新、删除)将添加到计划中。
对于 监听器触发的索引(仅限 Hibernate ORM 集成),这将隐式发生在执行更改时,但也可以 显式 完成。
-
最终,应用程序将决定更改已完成,并且计划将处理到目前为止添加的更改事件,要么推断哪些实体需要重新索引并构建相应的文档(无协调),要么构建要发送到出站箱的事件(
outbox-polling协调)。对于 Hibernate ORM 集成,这发生在 Hibernate ORM
Session被刷新时(显式地或作为事务提交的一部分),而对于 独立 POJO 映射器,这发生在SearchSession关闭时。 -
最后,计划将被执行,触发索引,可能异步进行。
对于 Hibernate ORM 集成,这发生在事务提交时,而对于 独立 POJO 映射器,这发生在
SearchSession关闭时。
以下是索引计划的关键特征摘要以及它们如何根据配置的 协调策略 变化。
| 协调策略 | 无协调(默认) | 出站箱轮询(仅限 Hibernate ORM 集成) |
|---|---|---|
索引更新保证 |
||
索引更新可见性 |
||
应用程序线程开销 |
||
数据库的开销(仅限 Hibernate ORM 集成) |
14.2.2. 与索引同步
基础
|
有关在 Hibernate Search 中写入和读取索引的初步介绍,特别是包括 *提交* 和 *刷新* 的概念,请参见 提交和刷新。 |
|
当使用 |
当事务提交 (Hibernate ORM 集成) 或 SearchSession 关闭 (独立 POJO 映射器) 时,使用默认协调设置,执行索引计划 (隐式(监听器触发) 或 显式) 会阻塞应用程序线程,直到索引达到一定的完成程度。
阻塞线程的主要原因有两个:
-
**已索引数据的安全**:如果数据库事务完成后,索引数据必须安全地存储到磁盘,则需要进行 索引提交。如果没有它,索引更改可能只在几秒钟后才是安全的,因为此时后台会定期进行索引提交。
-
**实时搜索查询**:如果数据库事务完成后(对于 Hibernate ORM 集成)或
SearchSession的close()方法返回(对于 独立 POJO 映射器),任何搜索查询都必须立即将索引更改考虑在内,则需要进行 索引刷新。如果没有它,索引更改可能只在几秒钟后才可见,因为此时后台会定期进行索引刷新。
这两个要求由 *同步策略* 控制。默认策略由配置属性 hibernate.search.indexing.plan.synchronization.strategy 定义。下面是所有可用策略及其保证的参考。
策略 |
吞吐量 |
应用程序线程恢复时的保证 |
||
|---|---|---|---|---|
已应用的更改(无论是否 提交) |
从崩溃/断电中安全的更改 (提交) |
搜索可见的更改 (刷新) |
||
|
最佳 |
无保证 |
无保证 |
无保证 |
|
中等 |
保证 |
保证 |
无保证 |
|
中等到 最差 |
保证 |
无保证 |
保证 |
|
保证 |
保证 |
保证 |
|
|
这就是为什么只建议在您知道后端为此而设计时或用于集成测试时使用此策略。特别是, |
每个会话的覆盖
虽然上述配置属性定义了一个默认值,但可以通过调用 SearchSession#indexingPlanSynchronizationStrategy(…) 并传递不同的策略来覆盖特定会话上的此默认值。
可以通过调用以下方式检索内置策略:
-
IndexingPlanSynchronizationStrategy.async() -
IndexingPlanSynchronizationStrategy.writeSync() -
IndexingPlanSynchronizationStrategy.readSync() -
或
IndexingPlanSynchronizationStrategy.sync()
SearchSession searchSession = /* ... */ (1)
searchSession.indexingPlanSynchronizationStrategy(
IndexingPlanSynchronizationStrategy.sync()
); (2)
entityManager.getTransaction().begin();
try {
Book book = entityManager.find( Book.class, 1 );
book.setTitle( book.getTitle() + " (2nd edition)" ); (3)
entityManager.getTransaction().commit(); (4)
}
catch (RuntimeException e) {
entityManager.getTransaction().rollback();
}
List<Book> result = searchSession.search( Book.class )
.where( f -> f.match().field( "title" ).matching( "2nd edition" ) )
.fetchHits( 20 ); (5)| 1 | 检索 SearchSession,默认情况下,它使用在属性中配置的同步策略。 |
| 2 | 覆盖同步策略。 |
| 3 | 更改实体。 |
| 4 | 提交更改,触发重新索引。 |
| 5 | 覆盖的策略保证修改后的书籍将出现在这些结果中,即使查询是在事务提交 *之后* 执行的(这里我们使用的是 Hibernate ORM 集成)。 |
自定义策略
您还可以实现自定义策略。然后,可以像内置策略一样设置自定义策略:
-
作为默认策略,将配置属性
hibernate.search.indexing.plan.synchronization.strategy设置为指向自定义实现的 Bean 引用,例如class:com.mycompany.MySynchronizationStrategy。 -
在会话级别,将自定义实现的实例传递给
SearchSession#indexingPlanSynchronizationStrategy(…)。
14.2.3. 索引计划过滤器
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
在某些情况下,以编程方式暂停 显式和监听器触发的索引 可能会有所帮助,例如,在导入大量数据时。Hibernate Search 允许配置应用程序范围和会话范围的过滤器来管理哪些类型被跟踪以进行更改和索引。
SearchMapping searchMapping = /* ... */ (1)
searchMapping.indexingPlanFilter( (2)
ctx -> ctx.exclude( EntityA.class ) (3)
.include( EntityExtendsA2.class )
);配置应用程序范围的过滤器需要 SearchMapping 的实例。
| 1 | 检索 SearchMapping. |
| 2 | 开始声明索引计划过滤器。 |
| 3 | 通过 SearchIndexingPlanFilter 配置包含/排除的类型。 |
SearchSession session = /* ... */ (1)
session.indexingPlanFilter(
ctx -> ctx.exclude( EntityA.class ) (2)
.include( EntityExtendsA2.class )
);配置会话范围的过滤器可以通过 SearchSession 的实例获得。
| 1 | 检索 SearchSession |
| 2 | 通过 SearchIndexingPlanFilter 配置包含/排除的类型。 |
可以通过提供已索引和包含的类型及其超类型来定义过滤器。接口是不允许的,将接口类传递给任何过滤器定义方法会导致异常。如果使用由 Map 表示的动态类型,则必须使用其名称来配置过滤器。过滤器规则如下:
-
如果类型
A被过滤器显式包含,那么对类型A的对象的更改将被处理。 -
如果类型
A被过滤器显式排除,那么对类型A的对象的更改将被忽略。 -
如果类型
A被过滤器显式包含,那么对类型B的对象的更改(其中类型B是类型A的子类型)将被处理,除非过滤器显式排除了类型B的更具体的超类型。 -
如果类型
A被过滤器显式排除,那么对类型B的对象的更改(其中类型B是类型A的子类型)将被忽略,除非过滤器显式包含类型B的更具体的超类型。
会话范围的过滤器优先于应用程序范围的过滤器。如果会话范围的过滤器配置既不显式也不通过继承包含/排除实体的精确类型,那么将由应用程序范围的过滤器做出决定。如果应用程序范围的过滤器也未对类型进行显式配置,那么该类型将被视为包含。
在某些情况下,我们可能需要完全禁用索引。逐个列出所有实体可能会很麻烦,但由于过滤器配置隐式地应用于子类型,因此可以使用 .exclude(Object.class) 来排除所有类型。相反,当应用程序范围的过滤器完全禁用索引时,可以使用 .include(Object.class) 在会话过滤器中启用索引。
SearchSession searchSession = /* ... */ (1)
searchSession.indexingPlanFilter(
ctx -> ctx.exclude( Object.class ) (2)
);配置会话范围的过滤器可以通过 SearchSession 的实例获得。
| 1 | 检索 SearchSession |
| 2 | 排除 Object.class 将导致排除其所有子类型,这意味着不会包含任何内容。 |
SearchMapping searchMapping = /* ... */ (1)
searchMapping.indexingPlanFilter(
ctx -> ctx.exclude( Object.class ) (2)
); SearchSession searchSession = /* ... */ (3)
searchSession.indexingPlanFilter(
ctx -> ctx.include( Object.class ) (4)
);
| 1 | 检索 SearchMapping. |
| 2 | 应用程序范围的过滤器禁用任何索引 |
| 3 | 检索 SearchSession |
| 4 | 会话范围的过滤器**仅针对当前会话中发生的更改**重新启用索引 |
|
尝试通过同一个过滤器将同一个类型同时配置为包含和排除会导致抛出异常。 |
|
仅当使用 |
14.3. 隐式、监听器触发的索引
14.3.1. 基础
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
以下是监听器触发的索引在高级别的工作方式:
-
当 Hibernate ORM
Session被刷新(显式地或作为事务提交的一部分)时,Hibernate ORM 会确定确切发生了什么变化(实体创建、更新、删除),并将信息转发给 Hibernate Search。 -
Hibernate Search 将此信息添加到(会话范围的)索引计划 中,并且计划会处理到目前为止添加的更改事件,要么推断哪些实体需要重新索引并构建相应的文档 (无协调),要么构建要发送到出站箱的事件 (
outbox-polling协调)。 -
在数据库事务提交时,计划会执行,要么将文档索引/删除请求发送到后端 (无协调),要么将事件发送到数据库 (
outbox-polling协调)。
以下是监听器触发的索引的关键特性的摘要,以及它们如何根据配置的 协调策略 变化。
点击链接以获取更多详细信息。
| 协调策略 | 无协调(默认) | 出站箱轮询 |
|---|---|---|
检测在 ORM 会话中发生的更改( |
||
检测由 JPQL 或 SQL 查询引起的更改( |
||
关联必须在两端更新 |
||
触发重新索引的更改 |
||
索引更新保证 |
||
索引更新可见性 |
||
应用程序线程开销 |
||
数据库开销 |
||
14.3.2. 配置
如果您的索引是只读的,或者您通过重新索引定期更新索引(使用 MassIndexer、使用 Jakarta Batch 批量索引作业 或 显式),则监听器触发的索引可能是不必要的。
您可以通过将配置属性 hibernate.search.indexing.listeners.enabled 设置为 false 来禁用监听器触发的索引。
由于监听器触发的索引在幕后使用 索引计划,因此影响索引计划的多个配置选项也会影响监听器触发的索引。
14.4. 使用 MassIndexer 索引大量数据
14.4.1. 基础知识
在某些情况下,监听器触发的或显式索引 不够,因为必须对预先存在的数据进行索引。
为了解决这些情况,Hibernate Search 提供了 MassIndexer:一个基于外部数据存储的内容(对于 Hibernate ORM 集成,该数据存储是数据库)完全重建索引的工具。可以告诉 MassIndexer 重新索引几个选定的索引类型,或者全部重新索引。
MassIndexer 采取以下方法来实现相当高的吞吐量。
-
在批量索引开始时,索引将被完全清除。
-
批量索引由多个并行线程执行,每个线程从数据库加载数据并将索引请求发送到索引,不会触发任何 提交或刷新。
-
在批量索引完成后执行隐式 刷新(提交)和 刷新,除了 Amazon OpenSearch Serverless,因为它不支持显式刷新或刷新。
|
由于初始索引清除,并且由于批量索引是一个非常占用资源的操作,建议在 在 |
以下代码片段将重建所有索引实体的索引,删除索引,然后从数据库重新加载所有实体。
MassIndexer 重新索引所有内容SearchSession searchSession = /* ... */ (1)
searchSession.massIndexer() (2)
.startAndWait(); (3)| 1 | 检索 SearchSession. |
| 2 | 创建一个针对每个已索引实体类型的 MassIndexer。 |
| 3 | 启动批量索引过程,并在其结束后返回。 |
|
|
|
对 MySQL 用户的说明: 要避免这种“优化”,请将 |
虽然 MassIndexer 很容易使用,但建议进行一些调整以加快速度。有几个可选参数可用,并且可以在批量索引器启动之前设置,如下所示。有关所有可用参数的参考,请参阅 MassIndexer 参数,有关关键主题的详细信息,请参阅 调整 MassIndexer 以获得最佳性能。
searchSession.massIndexer() (1)
.idFetchSize( 150 ) (2)
.batchSizeToLoadObjects( 25 ) (3)
.threadsToLoadObjects( 12 ) (4)
.startAndWait(); (5)| 1 | 创建一个 MassIndexer。 |
| 2 | 以 150 个元素的批次加载 Book 标识符。 |
| 3 | 以 25 个元素的批次加载要重新索引的 Book 实体。 |
| 4 | 创建 12 个并行线程来加载 Book 实体。 |
| 5 | 启动批量索引过程,并在其结束后返回。 |
|
使用多个线程运行 |
14.4.2. 选择要索引的类型
您可以在创建批量索引器时选择实体类型,以仅重新索引这些类型(及其任何索引的子类型)。
MassIndexer 重新索引选定的类型searchSession.massIndexer( Book.class ) (1)
.startAndWait(); (2)| 1 | 创建一个针对 Book 类型及其任何索引的子类型的 MassIndexer。 |
| 2 | 启动选定类型的批量索引过程,并在完成后返回。 |
14.4.3. 批量索引多个租户
上面各节中的示例从给定会话创建批量索引器,这将始终将批量索引限制在该会话所针对的租户。
使用 多租户 时,您可以通过从 SearchScope 检索批量索引器并传递租户标识符集合来一次性重新索引多个租户。
MassIndexer 重新索引显式列出的多个租户SearchMapping searchMapping = /* ... */ (1)
searchMapping.scope( Object.class ) (2)
.massIndexer( asSet( "tenant1", "tenant2" ) ) (3)
.startAndWait(); (4)| 1 | 检索 SearchMapping. |
| 2 | 检索一个 SearchScope,它针对我们想要重新索引的所有类型;这里我们使用 Object.class,表示“所有扩展 Object 的索引类型”,即简单地所有索引类型。 |
| 3 | 传递我们想要进行批量索引的租户的标识符并创建批量索引器。 |
| 4 | 启动批量索引过程,并在其结束后返回。 |
使用 Hibernate ORM 映射器,如果您 在 Hibernate Search 的配置中包含了完整的租户列表,您可以简单地调用 scope.massIndexer() 而不带任何参数,结果批量索引器将针对所有配置的租户。
MassIndexer 重新索引隐式配置的多个租户SearchMapping searchMapping = /* ... */ (1)
searchMapping.scope( Object.class ) (2)
.massIndexer() (3)
.startAndWait(); (4)| 1 | 检索 SearchMapping. |
| 2 | 检索一个 SearchScope,它针对我们想要重新索引的所有类型;这里我们使用 Object.class,表示“所有扩展 Object 的索引类型”,即简单地所有索引类型。 |
| 3 | 创建一个针对 配置中包含的所有租户 的批量索引器。 |
| 4 | 启动批量索引过程,并在其结束后返回。 |
14.4.4. 异步运行批量索引器
可以异步运行批量索引器,因为它不依赖于原始的 Hibernate ORM 会话。当异步使用时,批量索引器将返回一个完成阶段来跟踪批量索引的完成。
MassIndexer 异步重新索引 searchSession.massIndexer() (1)
.start() (2)
.thenRun( () -> { (3)
log.info( "Mass indexing succeeded!" );
} )
.exceptionally( throwable -> {
log.error( "Mass indexing failed!", throwable );
return null;
} );
// OR
Future<?> future = searchSession.massIndexer()
.start()
.toCompletableFuture(); (4)| 1 | 创建一个 MassIndexer。 |
| 2 | 启动批量索引过程,但不等待过程完成。将返回一个 CompletionStage。 |
| 3 | CompletionStage 公开方法,以便在索引完成后执行更多代码。 |
| 4 | 或者,在返回的对象上调用 toCompletableFuture() 以获得 Future。 |
14.4.5. 条件重新索引
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
您可以通过将条件作为字符串传递给批量索引器来选择要重新索引的目标实体子集。条件将在查询数据库以获取要索引的实体时应用。
条件字符串应遵循 Hibernate 查询语言 (HQL) 语法。可访问的实体属性是正在重新索引的实体的属性(仅此而已)。
SearchSession searchSession = /* ... */ (1)
MassIndexer massIndexer = searchSession.massIndexer(); (2)
massIndexer.type( Book.class ).reindexOnly( "publicationYear < 1950" ); (3)
massIndexer.type( Author.class ).reindexOnly( "birthDate < :cutoff" ) (4)
.param( "cutoff", Year.of( 1950 ).atDay( 1 ) ); (5)
massIndexer.startAndWait(); (6)| 1 | 检索 SearchSession. |
| 2 | 创建一个针对每个已索引实体类型的 MassIndexer。 |
| 3 | 仅重新索引 1950 年之前出版的书籍。 |
| 4 | 仅重新索引在给定本地日期之前出生的作者。 |
| 5 | 在此示例中,截止日期作为查询参数传递。 |
| 6 | 启动批量索引过程,并在其结束后返回。 |
|
即使重新索引应用于实体子集,默认情况下,所有实体也会在开始时被清除。可以 完全禁用清除,但如果启用,则无法过滤将被清除的实体。 有关更多信息,请参阅 HSEARCH-3304。 |
14.4.6. MassIndexer 参数
| 设置器 | 默认值 | 描述 |
|---|---|---|
|
|
并行索引的类型数量。 |
|
用于实体加载的线程数量,用于每个并行索引的类型。也就是说,为实体加载生成的线程数量将为 |
|
|
仅支持 Hibernate ORM 集成。 用于加载主键的获取大小。某些数据库接受特殊值,例如 MySQL 可能从使用 |
|
|
仅支持 Hibernate ORM 集成。 用于从数据库加载实体的获取大小。某些数据库接受特殊值,例如 MySQL 可能从使用 |
|
|
在删除和重新创建期间,索引将不可用一小段时间,因此仅在对索引的并发操作(监听器触发的索引,…)的故障是可以接受的情况下使用。 当已知现有架构已过时时应使用此方法,例如当 Hibernate Search 映射发生更改 并且某些字段现在具有不同的类型、不同的分析器、新功能(可投影,…)等时。 当架构是最新的时,也可以使用此方法,因为它可能比大型索引上的清除( 作为此参数的替代方案,您也可以在您选择的时间手动使用架构管理器管理架构:手动架构管理。 |
|
|
默认值取决于 |
在索引之前从索引中删除所有实体。 仅当您知道索引已经为空时才将其设置为 |
|
一般情况下为 |
在初始索引清除后,就在索引之前,强制将每个索引合并为单个段。如果将 |
|
|
强制将每个索引合并为单个段,以完成索引。此操作并不总是能提高性能:请参见合并段和性能. |
|
|
仅支持Hibernate ORM集成。加载实体时使用的Hibernate |
|
- |
仅在启用JTA的环境中以及使用Hibernate ORM集成时支持。加载要重新索引的ID和实体的交易超时。超时时间应足够长,以便加载和索引所有类型的实体。请注意,这些交易是只读的,因此选择较大的值(例如 |
|
- |
仅支持Hibernate ORM集成。每个实体类型要加载的最大结果数。此参数使您可以定义一个阈值,以避免意外加载过多的实体。定义的值必须大于0。此参数默认情况下不使用。它等效于SQL中的关键字 |
|
日志监控。 |
由于
|
|
错误处理程序。 |
负责处理大规模索引过程中发生的错误的组件。
默认的内置错误处理程序只是将错误转发到全局后台错误处理程序,默认情况下,该处理程序会在
|
|
一个空环境(没有线程局部变量,…)。 |
此功能正在孵化:它仍在积极开发中。孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以不兼容的方式更改(甚至删除)。 负责在大规模索引开始之前在每个线程上设置环境(线程局部变量,…),并在索引完成之后拆除环境的组件。 实现应处理它们的异常,除非它是一个无法恢复的情况,在这种情况下,进一步的大规模索引没有意义:由 |
|
使用默认错误处理程序时为 |
此功能正在孵化:它仍在积极开发中。每个索引类型要处理的最大错误数。超出此数量的任何错误将被忽略,并且不会通过 默认为正在使用的错误处理程序定义的阈值;请参见 |
14.4.7. 调整MassIndexer以获得最佳性能
基础
MassIndexer旨在尽快完成重新索引任务,但是没有一种万能的解决方案,因此需要进行一些配置才能充分利用它。
性能优化可能非常复杂,因此在尝试配置MassIndexer时请牢记以下几点
-
始终测试您的更改以评估其实际效果:本节中提供的建议通常是正确的,但每个应用程序和环境都不一样,一些选项组合在一起可能会产生意想不到的结果。
-
逐步操作:在使用40个索引实体类型(每个类型具有200万个实例)调整大规模索引之前,请尝试更合理的场景,仅使用一个实体类型,可以选择性地限制要索引的实体数量,以更快地评估性能。
-
在尝试调整并行索引多个实体类型的大规模索引操作之前,请单独调整您的实体类型。
线程和连接
提高并行性通常会有所帮助,因为瓶颈通常是数据库/数据存储连接的延迟:尝试使用比实际内核数量明显更高的线程数可能值得。
但是,每个线程都需要一个连接(例如JDBC连接),而连接通常是有限的。为了安全地增加线程数
-
您应该确保数据库/数据存储能够实际处理由此产生的连接数。
-
您的连接池应该配置为提供足够的连接数。
-
以上应考虑到应用程序的其余部分(Web应用程序中的请求线程):忽略此操作可能会在
MassIndexer工作时使其他进程停止。
有一个简单的公式可以理解应用于MassIndexer的不同选项如何影响使用的工作线程和连接数
if ( using the default 'none' coordination strategy ) {
threadsToCoordinate = 0;
}
else {
threadsToCoordinate = 1;
}
threadsToLoadIdentifiers = 1;
threads = threadsToCoordinate + typesToIndexInParallel * (threadsToLoadObjects + threadsToLoadIdentifiers);
required connections = threads;
以下是一些有关影响并行性的参数的大致合理的调整起点建议
typesToIndexInParallel-
可能应该是一个较低的值,例如1或2,具体取决于您的CPU有多少空闲周期以及数据库往返操作的速度。
threadsToLoadObjects-
较高的值会增加从数据库中预加载选定实体的速度,但也增加了内存使用量以及对处理后续索引的线程的压力。请注意,每个线程都会从实体中提取要重新索引的数据,这取决于您的映射,这可能需要访问延迟关联并加载关联实体,从而对数据库/数据存储发出阻塞调用,因此您可能需要大量线程并行工作。
|
所有内部线程组都具有以“Hibernate Search”为前缀的有意义的名称,因此它们应该很容易用大多数诊断工具识别,包括简单的线程转储。 |
14.5. 使用Jakarta Batch集成索引大量数据
14.5.1. 基础
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
Hibernate Search提供了一个Jakarta Batch作业来执行大规模索引。它不仅涵盖了上面描述的大规模索引器的现有功能,而且还受益于Jakarta Batch的一些强大的标准功能,例如使用检查点的故障恢复、面向块的处理以及并行执行。此批处理作业接受不同的实体类型作为输入,从数据库加载相关实体,然后根据这些实体重建全文索引。
执行此作业需要一个批处理运行时,Hibernate Search不提供。您可以自由选择一个适合您需求的运行时,例如嵌入在Jakarta EE容器中的默认批处理运行时。Hibernate Search与JBeret实现(请参见此处如何配置它)提供了完全集成。至于其他实现,它们也可以使用,但需要您这边进行一些额外的配置.
如果运行时是JBeret,则需要添加以下依赖项
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm-jakarta-batch-jberet</artifactId>
<version>7.2.0.Final</version>
</dependency>对于任何其他运行时,您需要添加以下依赖项
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm-jakarta-batch-core</artifactId>
<version>7.2.0.Final</version>
</dependency>以下是如何运行批处理实例的示例
Properties jobProps = MassIndexingJob.parameters() (1)
.forEntities( Book.class, Author.class ) (2)
.build();
JobOperator jobOperator = BatchRuntime.getJobOperator(); (3)
long executionId = jobOperator.start( MassIndexingJob.NAME, jobProps ); (4)| 1 | 开始构建大规模索引作业的参数。 |
| 2 | 定义一些参数。在这种情况下,要索引的实体类型的列表。 |
| 3 | 从框架获取JobOperator。 |
| 4 | 启动作业。 |
14.5.2. 作业参数
下表包含您可以用来自定义大规模索引作业的所有作业参数。
| 参数名称/生成器方法 | 默认值 | 描述 | ||
|---|---|---|---|---|
|
- |
此参数始终是必需的. 在此作业执行中要索引的实体类型,以逗号分隔。 |
||
|
真 |
指定作业开始时是否应清除现有索引。此操作在索引之前进行。
|
||
|
假 |
指定作业开始时是否应删除并创建现有架构。此操作在索引之前进行。
|
||
|
真 |
指定大规模索引器是否应在作业开始时合并段。此操作在清除操作之后但在索引之前进行。 |
||
|
真 |
指定大规模索引器是否应在作业结束时合并段。此操作在索引之后进行。 |
||
|
|
指定加载实体时使用的Hibernate |
||
|
1000 |
指定加载主键时要使用的提取大小。某些数据库接受特殊值,例如MySQL可能会从使用 |
||
|
200,或者 |
指定从数据库加载实体时要使用的提取大小。定义的值必须大于0,并且等于或小于 |
||
|
- |
使用HQL/JPQL索引目标实体类型的实体。您的查询应仅包含一个实体类型。不允许将这种方法与标准限制混合使用。请注意,您的输入没有查询验证。有关更多详细信息和限制,请参见[mapper-orm-indexing-jakarta-batch-indexing-mode]。 |
||
|
- |
每个实体类型要加载的最大结果数。此参数允许您定义一个阈值,以避免意外加载过多实体。定义的值必须大于 0。默认情况下不使用此参数。它等效于 SQL 中的关键字 |
||
|
20,000 |
每个分区要处理的最大行数。定义的值必须大于 0,并且等于或大于 |
||
|
分区数量 |
用于处理作业的最大线程数。请注意,批处理运行时无法保证请求的线程数可用;它将使用尽可能多的线程,直到达到请求的最大值。 |
||
|
2,000,或 |
触发检查点之前要处理的实体数量。定义的值必须大于 0,并且等于或小于 |
||
|
- |
当存在多个持久化单元时,此参数是必需的。 用于标识 |
||
|
- |
14.5.3. 条件索引
您可以通过将条件作为字符串传递给批量索引作业来选择要索引的目标实体的子集。该条件将在查询数据库以获取要索引的实体时应用。
条件字符串应遵循 Hibernate 查询语言 (HQL) 语法。可访问的实体属性是正在重新索引的实体的属性(仅此而已)。
reindexOnly HQL 参数的条件索引Properties jobProps = MassIndexingJob.parameters() (1)
.forEntities( Author.class ) (2)
.reindexOnly( "birthDate < :cutoff", (3)
Map.of( "cutoff", Year.of( 1950 ).atDay( 1 ) ) ) (4)
.build();
JobOperator jobOperator = BatchRuntime.getJobOperator(); (5)
long executionId = jobOperator.start( MassIndexingJob.NAME, jobProps ); (6)| 1 | 开始构建大规模索引作业的参数。 |
| 2 | 定义要索引的实体类型。 |
| 3 | 仅重新索引在给定本地日期之前出生的作者。 |
| 4 | 在此示例中,截止日期作为查询参数传递。 |
| 5 | 从框架中获取 JobOperator。 |
| 6 | 启动作业。 |
|
即使重新索引应用于实体的子集,默认情况下,所有实体都会在开始时被清除。清除 可以完全禁用,但是启用后,无法过滤要清除的实体。 有关更多信息,请参阅 HSEARCH-3304。 |
14.5.4. 并行索引
为了获得更好的性能,索引是使用多个线程并行执行的。要索引的实体集被分成多个分区。每个线程一次处理一个分区。
以下部分将解释如何调整并行执行。
|
线程数量、获取大小、分区大小等的“最佳点”来实现最佳性能高度依赖于您的整体架构、数据库设计甚至数据值。 您应该尝试这些设置,以找出最适合您的特定情况的方法。 |
线程
作业执行使用的方法 maxThreads() 定义了作业执行使用的最大线程数。在给定的 N 个线程中,保留 1 个线程用于核心,因此只有 N - 1 个线程可用于不同的分区。如果 N = 1,程序将正常工作,并且所有批处理元素将在同一个线程中运行。Hibernate Search 中使用的默认线程数是 10。您可以使用您首选的数字覆盖它。
MassIndexingJob.parameters()
.maxThreads( 5 )
...|
请注意,批处理运行时无法保证请求的线程数可用,它将使用尽可能多的线程,直到达到请求的最大值(Jakarta Batch Specification v2.1 Final Release,第 29 页)。还要注意,所有批处理作业共享相同的线程池,因此并发执行作业并不总是好的主意。 |
每个分区中的行数
每个分区包含固定数量的要索引的元素。您可以使用 rowsPerPartition 调整每个分区要包含多少元素。
MassIndexingJob.parameters()
.rowsPerPartition( 5000 )
...|
此属性与“块大小”无关,块大小是指在每次写入之间一起处理多少个元素。处理的这一方面由分块解决。 相反, 请参见 分块部分,以了解如何调整分块。 |
当 rowsPerPartition 较低时,将有许多小分区,因此处理线程不太可能出现饥饿(由于没有更多分区可处理而处于空闲状态),但另一方面,您只能利用较小的获取大小,这将增加数据库访问次数。此外,由于故障恢复机制,启动新分区会产生一些开销,因此,如果分区数量过多,此开销会累加。
当 rowsPerPartition 较高时,将有一些大分区,因此您将能够利用更高的 块大小,从而实现更高的获取大小,这将减少数据库访问次数,并且启动新分区的开销将不太明显,但另一方面,您可能无法使用所有可用的线程。
|
每个分区处理一个根实体类型,因此两个不同的实体类型永远不会在同一个分区下运行。 |
14.5.5. 分块和会话清除
批量索引作业支持从其停止的位置或多或少地重新启动已挂起或失败的作业。
这是通过将每个分区拆分成几个连续的实体块,并在每个块结束时将进程信息保存在检查点中来实现的。当作业重新启动时,它将从最后一个检查点恢复。
每个块的大小由 checkpointInterval 参数确定。
MassIndexingJob.parameters()
.checkpointInterval( 1000 )
...但是,块的大小不仅仅是关于保存进度,它也是关于性能
-
为每个块打开一个新的 Hibernate 会话;
-
为每个块启动一个新的事务;
-
在块内,会话会根据
entityFetchSize参数定期清除,因此该参数必须小于(或等于)块大小; -
在每个块结束时,文档被刷新到索引中。
|
通常,检查点间隔应与每个分区中的行数相比很小。 事实上,由于故障恢复机制,每个分区第一个检查点之前的元素处理时间将比其他元素长,因此,在一个包含 1000 个元素的分区中,具有 100 个元素的检查点间隔将比具有 1000 个元素的检查点间隔更快。 另一方面,块在绝对值上不应该太小。执行检查点意味着您的 Jakarta Batch 运行时将有关作业执行进度的信息写入其持久存储,这也需要付出代价。此外,为每个块创建新的事务和会话是有成本的,这意味着将获取大小设置为大于块大小的值毫无意义。最后,在每个块结束时执行的索引刷新是一个昂贵的操作,它涉及全局锁定,这意味着您执行的次数越少,索引速度就越快。因此,使用 1 个元素的检查点间隔绝对不是一个好主意。 |
14.5.6. 选择持久化单元 (EntityManagerFactory)
|
无论如何获取实体管理器工厂,您都必须确保批量索引器使用的实体管理器工厂在整个批量索引过程中保持打开状态。 |
JBeret
如果您的 Jakarta Batch 运行时是 JBeret(特别是在 WildFly 中使用),您可以使用 CDI 来检索 EntityManagerFactory。
如果您只使用一个持久化单元,批量索引器将能够在没有任何特殊配置的情况下自动访问您的数据库。
如果您想使用多个持久化单元,您将不得不将 EntityManagerFactories 注册为 CDI 上下文中的 Bean。请注意,实体管理器工厂默认情况下可能不被视为 Bean,在这种情况下,您将不得不自己注册它们。您可以使用应用程序范围的 Bean 来做到这一点
@ApplicationScoped
public class EntityManagerFactoriesProducer {
@PersistenceUnit(unitName = "db1")
private EntityManagerFactory db1Factory;
@PersistenceUnit(unitName = "db2")
private EntityManagerFactory db2Factory;
@Produces
@Singleton
@Named("db1") // The name to use when referencing the bean
public EntityManagerFactory createEntityManagerFactoryForDb1() {
return db1Factory;
}
@Produces
@Singleton
@Named("db2") // The name to use when referencing the bean
public EntityManagerFactory createEntityManagerFactoryForDb2() {
return db2Factory;
}
}一旦实体管理器工厂在 CDI 上下文中注册,您可以使用 entityManagerReference 参数命名它,从而指示批量索引器使用其中一个特定工厂。
|
由于 CDI API 的限制,当前无法在使用带有 CDI 的批量索引器时,通过其持久化单元名称引用实体管理器工厂。 |
其他支持 DI 的 Jakarta Batch 实现
如果您想使用不同的 Jakarta Batch 实现,该实现恰好允许依赖注入
-
您必须将以下两个范围注释映射到依赖注入机制中的相关范围
-
org.hibernate.search.jakarta.batch.core.inject.scope.spi.HibernateSearchJobScoped -
org.hibernate.search.jakarta.batch.core.inject.scope.spi.HibernateSearchPartitionScoped
-
-
您必须确保依赖注入机制将注册来自
hibernate-search-mapper-orm-jakarta-batch-core模块的所有注入注释类 (@Named,…) 在依赖注入上下文中。例如,这可以在 Spring DI 中使用@ComponentScan注释来实现。 -
您必须在依赖注入上下文中注册一个实现
EntityManagerFactoryRegistry接口的单一 Bean。
纯 Java 环境(完全没有依赖注入)
以下操作只有在您的 Jakarta Batch 运行时根本不支持依赖注入时才有效,即它忽略批处理工件中的 @Inject 注释。例如,JBatch 在 Java SE 模式下就是这样。
如果您只使用一个持久化单元,批量索引器将能够在没有任何特殊配置的情况下自动访问您的数据库:您只需确保在启动批量索引器之前在应用程序中创建 EntityManagerFactory(或 SessionFactory)。
如果您想使用多个持久化单元,您将不得不启动批量索引器时添加两个参数
-
entityManagerFactoryReference:这是用于标识EntityManagerFactory的字符串。 -
entityManagerFactoryNamespace:这允许您选择如何引用EntityManagerFactory。可能的值是-
persistence-unit-name(默认值):使用persistence.xml中定义的持久化单元名称。 -
session-factory-name:使用 Hibernate 配置中通过hibernate.session_factory_name配置属性定义的会话工厂名称。
-
|
如果您在 Hibernate 配置中设置了 |
14.6. 显式索引
14.6.1. 基础知识
虽然 监听器触发的索引 和 MassIndexer 或 批量索引作业 应该可以满足大多数需求,但有时有必要手动控制索引。
特别是在 监听器触发索引 被 禁用 或根本不支持(例如,使用独立 POJO 映射器)时,或者监听器触发无法检测到实体更改时(例如 JPQL/SQL insert、update 或 delete 查询),这种需求就会出现。
为了解决这些用例,Hibernate Search 公开了几个 API,将在以下部分进行解释。
14.6.3. 手动使用 SearchIndexingPlan
显式访问 索引计划 是在 SearchSession 的上下文中使用 SearchIndexingPlan 接口完成的。此接口表示在会话上下文中计划的(可变)更改集,并将应用于事务提交(对于 Hibernate ORM 集成)或关闭 SearchSession(对于 独立 POJO 映射器)时的索引。
以下是基于 索引计划 的显式索引在高级别上的工作原理。
-
当应用程序想要进行索引更改时,它会调用当前
SearchSession的索引计划上的一个add/addOrUpdate/delete方法。对于 Hibernate ORM 集成,当前
SearchSession绑定到 Hibernate ORMSession,而对于 独立 POJO 映射器,SearchSession由应用程序显式创建。 -
最终,应用程序将决定更改已完成,并且计划将处理到目前为止添加的更改事件,要么推断哪些实体需要重新索引并构建相应的文档(无协调),要么构建要发送到出站箱的事件(
outbox-polling协调)。应用程序可以使用索引计划的
process方法显式触发此操作,但通常不需要,因为它会自动发生:对于 Hibernate ORM 集成,这会在 Hibernate ORMSession被刷新(显式或作为事务提交的一部分)时发生,而对于 独立 POJO 映射器,这会在SearchSession被关闭时发生。 -
最后,计划将被执行,触发索引,可能异步进行。
应用程序可以使用索引计划的
execute方法显式触发此操作,但通常不需要,因为它会自动发生:对于 Hibernate ORM 集成,这会在事务提交时发生,而对于 独立 POJO 映射器,这会在SearchSession被关闭时发生。
SearchIndexingPlan 接口提供以下方法。
add(Object entity)-
(仅适用于 独立 POJO 映射器。)
如果实体类型映射到索引(
@Indexed),则将文档添加到索引中。如果文档已存在,这可能会在索引中创建重复项。除非你确信自己并且需要(稍微)提高性能,否则请优先使用 addOrUpdate。 addOrUpdate(Object entity)-
如果实体类型映射到索引(
@Indexed),则在索引中添加或更新文档,并重新索引嵌入此实体的文档(例如,通过@IndexedEmbedded)。 delete(Object entity)-
如果实体类型映射到索引(
@Indexed),则从索引中删除文档,并重新索引嵌入此实体的文档(例如,通过@IndexedEmbedded)。 purge(Class<?> entityType, Object id)-
从索引中删除实体,但不要尝试重新索引嵌入此实体的文档。
与
delete相比,这在实体已从数据库中删除且不可用时(即使在会话中处于分离状态)特别有用。在这种情况下,重新索引相关实体将由用户负责,因为 Hibernate Search 无法知道哪些实体与不再存在的实体相关联。 purge(String entityName, Object id)-
与
purge(Class<?> entityType, Object id)相同,但实体类型由其名称引用(参见@javax.persistence.Entity#name)。 process()`-
(仅适用于 Hibernate ORM 集成。)
处理迄今为止添加的更改事件,要么推断需要重新索引哪些实体并构建相应的文档(无协调),要么构建要发送到出站邮箱的事件(
outbox-polling协调)。此方法通常会自动执行(参见本节顶部的概述),因此,仅当处理大量项目时,显式调用它才对批处理有用,如 Hibernate ORM 和使用
SearchIndexingPlan的周期性“flush-clear”模式 中所述。 execute()-
(仅适用于 Hibernate ORM 集成。)
执行索引计划,触发索引,可能异步执行。
此方法通常会自动执行(参见本节顶部的概述),因此,仅在非常罕见的情况下,在处理大量项目并且事务不是选项时显式调用它才有用,如 Hibernate ORM 和使用
SearchIndexingPlan的周期性“flush-clear”模式 中所述。
以下是使用 addOrUpdate 和 delete 的示例。
SearchIndexingPlan 显式在索引中添加或更新实体// Not shown: open a transaction if relevant
SearchSession searchSession = /* ... */ (1)
SearchIndexingPlan indexingPlan = searchSession.indexingPlan(); (2)
Book book = entityManager.getReference( Book.class, 5 ); (3)
indexingPlan.addOrUpdate( book ); (4)
// Not shown: commit the transaction or close the session if relevant| 1 | 检索 SearchSession. |
| 2 | 获取搜索会话的索引计划。 |
| 3 | 从数据库中获取我们要索引的 Book;这可以用使用 独立 POJO 映射器 时加载实体的任何其他方式替换。 |
| 4 | 将 Book 提交到索引计划以进行添加或更新操作。此操作不会立即执行,而是在事务提交(Hibernate ORM 集成)或 SearchSession 关闭(独立 POJO 映射器)之前延迟。 |
SearchIndexingPlan 显式从索引中删除实体// Not shown: open a transaction if relevant
SearchSession searchSession = /* ... */ (1)
SearchIndexingPlan indexingPlan = searchSession.indexingPlan(); (2)
Book book = entityManager.getReference( Book.class, 5 ); (3)
indexingPlan.delete( book ); (4)
// Not shown: commit the transaction or close the session if relevant| 1 | 检索 SearchSession. |
| 2 | 获取搜索会话的索引计划。 |
| 3 | 从数据库中获取我们要取消索引的 Book;这可以用使用 独立 POJO 映射器 时加载实体的任何其他方式替换。 |
| 4 | 将 Book 提交到索引计划以进行删除操作。此操作不会立即执行,而是在事务提交(Hibernate ORM 集成)或 SearchSession 关闭(独立 POJO 映射器)之前延迟。 |
|
可以在一个索引计划中执行多个操作。同一个实体甚至可以多次更改,例如添加然后删除:Hibernate Search 将按预期简化操作。 这对于任何合理的实体数量都将正常工作,但是在一个会话中更改或仅仅加载大量实体需要对 Hibernate ORM 进行特殊处理,然后还需要对 Hibernate Search 进行一些额外的处理。有关更多信息,请参阅 Hibernate ORM 和使用 |
14.6.4. Hibernate ORM 和使用 SearchIndexingPlan 的周期性“flush-clear”模式
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
使用 JPA 操作大型数据集时,一个相当常见的用例是 周期性“flush-clear”模式,其中循环在每次迭代中读取或写入实体,并且在每次 n 次迭代后刷新然后清除会话。此模式允许处理大量实体,同时保持内存占用量合理。
以下是在不使用 Hibernate Search 时持久化大量实体的此模式的示例。
entityManager.getTransaction().begin();
try {
for ( int i = 0; i < NUMBER_OF_BOOKS; ++i ) { (1)
Book book = newBook( i );
entityManager.persist( book ); (2)
if ( ( i + 1 ) % BATCH_SIZE == 0 ) {
entityManager.flush(); (3)
entityManager.clear(); (4)
}
}
entityManager.getTransaction().commit();
}
catch (RuntimeException e) {
entityManager.getTransaction().rollback();
throw e;
}| 1 | 在事务内对大量元素执行循环。 |
| 2 | 对于循环的每次迭代,实例化一个新实体并将其持久化。 |
| 3 | 在循环的每次 BATCH_SIZE 次迭代中,flush 实体管理器以将更改发送到数据库端缓冲区。 |
| 4 | 在 flush 之后,clear ORM 会话以释放一些内存。 |
使用 Hibernate Search 6(与 Hibernate Search 5 及更早版本相反),此模式将按预期工作。
-
在协调禁用(默认)的情况下,文档将在刷新时构建,并在事务提交时发送到索引。
-
使用 outbox-polling 协调,实体更改事件将在刷新时持久化,并在事务提交时与其余更改一起提交。
但是,每次 flush 调用都可能向内部缓冲区添加数据,对于大量数据,这可能会导致 OutOfMemoryException,具体取决于 JVM 堆大小、协调策略 以及文档的复杂性和数量。
如果遇到内存问题,第一个解决方案是将批处理过程分解为多个事务,每个事务处理少量元素:内部文档缓冲区将在每个事务之后被清除。
请参阅下面的示例。
|
使用此模式,如果一个事务失败,部分数据将已存在于数据库和索引中,并且无法回滚更改。 但是,索引将与数据库保持一致,并且可以(手动)从失败的最后一个事务重新启动该过程。 |
try {
int i = 0;
while ( i < NUMBER_OF_BOOKS ) { (1)
entityManager.getTransaction().begin(); (2)
int end = Math.min( i + BATCH_SIZE, NUMBER_OF_BOOKS ); (3)
for ( ; i < end; ++i ) {
Book book = newBook( i );
entityManager.persist( book ); (4)
}
entityManager.getTransaction().commit(); (5)
}
}
catch (RuntimeException e) {
entityManager.getTransaction().rollback();
throw e;
}| 1 | 添加一个外部循环,在每次迭代中创建一个事务。 |
| 2 | 在外部循环的每次迭代开始时开始事务。 |
| 3 | 每个事务仅处理有限数量的元素。 |
| 4 | 对于循环的每次迭代,实例化一个新实体并将其持久化。请注意,我们依赖于监听器触发的索引来索引实体,但这在监听器触发的索引被禁用时也能正常工作,只需要额外调用来索引实体即可。请参阅 索引计划。 |
| 5 | 在外部循环的每次迭代结束时提交事务。实体将自动刷新并索引。 |
|
可以将多事务解决方案和原始 此组合解决方案最灵活,因此如果你想微调批处理过程,它最适合。 |
如果将批处理过程分解为多个事务不可行,第二个解决方案是在调用 session.flush()/session.clear() 后立即写入索引,而无需等待数据库事务提交:内部文档缓冲区将在每次写入索引后被清除。
这可以通过在索引计划上调用 execute() 方法来完成,如以下示例所示。
|
使用此模式,如果抛出异常,部分数据将已存在于索引中,并且无法回滚更改,而数据库更改将被回滚。因此,索引将与数据库不一致。 要从这种情况中恢复,您需要手动执行导致失败的数据库更改(使数据库与索引同步),或者手动重新索引交易影响的实体(使索引与数据库同步)。 当然,如果您能承受将索引脱机更长时间,一个更简单的解决方案是清除索引并重新索引所有内容。 |
execute() 的 Hibernate Search 批量处理SearchSession searchSession = Search.session( entityManager ); (1)
SearchIndexingPlan indexingPlan = searchSession.indexingPlan(); (2)
entityManager.getTransaction().begin();
try {
for ( int i = 0; i < NUMBER_OF_BOOKS; ++i ) {
Book book = newBook( i );
entityManager.persist( book ); (3)
if ( ( i + 1 ) % BATCH_SIZE == 0 ) {
entityManager.flush();
entityManager.clear();
indexingPlan.execute(); (4)
}
}
entityManager.getTransaction().commit(); (5)
}
catch (RuntimeException e) {
entityManager.getTransaction().rollback();
throw e;
}15. 搜索
除了简单的索引,Hibernate Search 还公开了高级 API 来搜索这些索引,而无需诉诸本地 API。
这些搜索 API 的一个关键功能是能够使用索引执行搜索,但返回从数据库加载的实体,有效地为 Hibernate ORM 实体提供了一种新的查询类型。
15.1. 查询 DSL
15.1.1. 基础
准备和执行查询只需要几行代码
// Not shown: open a transaction if relevant
SearchSession searchSession = /* ... */ (1)
SearchResult<Book> result = searchSession.search( Book.class ) (2)
.where( f -> f.match() (3)
.field( "title" )
.matching( "robot" ) )
.fetch( 20 ); (4)
long totalHitCount = result.total().hitCount(); (5)
List<Book> hits = result.hits(); (6)
// Not shown: commit the transaction if relevant| 1 | 检索 SearchSession. |
| 2 | 在映射到 Book 实体 的索引上启动搜索查询。 |
| 3 | 定义仅返回匹配给定谓词的文档。谓词使用作为 lambda 表达式参数传递的工厂 f 创建。有关谓词的更多信息,请参见 谓词 DSL。 |
| 4 | 构建查询并获取结果,限制为前 20 个匹配项。 |
| 5 | 检索匹配实体的总数。有关优化总数(命中次数等)计算的方法,请参见获取总数(命中次数等)。 |
| 6 | 检索匹配实体。 |
这将与Hibernate ORM 集成一起正常工作:默认情况下,搜索查询的匹配项将是 Hibernate ORM 管理的实体,绑定到用于创建搜索会话的实体管理器。这提供了 Hibernate ORM 的所有优势,特别是能够在必要时导航实体图以检索关联实体的能力。
|
对于独立 POJO 映射器,上面的代码段默认情况下会失败。 您需要:
|
查询 DSL 提供了许多功能,在以下部分中详细介绍。一些常用的功能包括
15.1.2. 高级实体类型定位
定位多个实体类型
当多个实体类型具有相似的索引字段时,可以在单个搜索查询中跨这些多个类型进行搜索:搜索结果将包含来自任何目标类型的匹配项。
SearchResult<Person> result = searchSession.search( Arrays.asList( (1)
Manager.class, Associate.class
) )
.where( f -> f.match() (2)
.field( "name" )
.matching( "james" ) )
.fetch( 20 ); (3)| 1 | 启动一个搜索查询,定位映射到 Manager 和 Associate 实体类型的索引。由于这两个实体类型都实现了 Person 接口,因此搜索匹配项将是 Person 的实例。 |
| 2 | 像往常一样继续构建查询。对于可以使用哪些字段有一些限制:请参见下面的说明。 |
| 3 | 获取搜索结果。匹配项都将是 Person 的实例。 |
|
多实体(多索引)搜索仅在谓词/排序等中引用的字段在所有目标索引中都相同(相同类型,相同分析器等)时才能正常工作。仅在其中一个目标索引中定义的字段也将正常工作。 如果您想引用在其中一个目标索引中甚至略微不同的索引字段(不同类型,不同分析器等),请参见定位多个字段。 |
按名称定位实体类型
SearchResult<Person> result = searchSession.search( (1)
searchSession.scope( (2)
Person.class,
Arrays.asList( "Manager", "Associate" )
)
)
.where( f -> f.match() (3)
.field( "name" )
.matching( "james" ) )
.fetch( 20 ); (4)| 1 | 启动一个搜索查询。 |
| 2 | 传递一个自定义范围,涵盖映射到 Manager 和 Associate 实体类型的索引,并期望这些实体类型实现 Person 接口(Hibernate Search 将检查这一点)。 |
| 3 | 像往常一样继续构建查询。 |
| 4 | 获取搜索结果。匹配项都将是 Person 的实例。 |
15.1.3. 获取结果
基础
在 Hibernate Search 中,默认的搜索结果比“匹配项列表”复杂一些。这就是为什么默认方法返回一个复合 SearchResult 对象,该对象提供 getter 来检索您想要的结果部分,如下面的示例所示。
SearchResult 中获取信息SearchResult<Book> result = searchSession.search( Book.class ) (1)
.where( f -> f.matchAll() )
.fetch( 20 ); (2)
long totalHitCount = result.total().hitCount(); (3)
List<Book> hits = result.hits(); (4)
// ... (5)| 1 | 像往常一样开始构建查询。 |
| 2 | 获取结果,限制为前 20 个匹配项。 |
| 3 | 检索总匹配次数,即与查询匹配的实体/文档总数,即使您只检索了前 20 个匹配项,也可能达到 10,000。这对于让最终用户了解他们的查询产生了多少匹配项很有用。有关优化总数(命中次数等)计算的方法,请参见获取总数(命中次数等)。 |
| 4 | 检索前几个匹配项,在本例中为前 20 个匹配实体/文档。 |
| 5 | 其他类型的结果和信息可以从 SearchResult 中检索。它们在专门的部分中解释,例如 聚合 DSL。 |
可以单独检索总匹配次数,用于仅对匹配次数感兴趣,而对匹配项本身不感兴趣的情况
long totalHitCount = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.fetchTotalHitCount();也可以直接获取前几个匹配项,而不必通过 SearchResult,这在仅对前几个匹配项有用,而对总匹配次数没有用时很有用
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.fetchHits( 20 );如果预计匹配项为 0 到 1 个,则可以将其作为 Optional 检索。如果返回多个匹配项,则会抛出异常。
Optional<Book> hit = searchSession.search( Book.class )
.where( f -> f.id().matching( 1 ) )
.fetchSingleHit();获取所有匹配项
|
获取所有匹配项很少是一个好主意:如果查询与许多实体/文档匹配,这可能会导致在内存中加载数百万个实体,这很可能会导致 JVM 崩溃,或者至少会使其运行速度减慢。 如果您知道您的查询将始终具有少于 N 个匹配项,请考虑将限制设置为 N 以避免内存问题。 如果您仍然想在一次调用中获取所有匹配项,请注意 Elasticsearch 后端只会一次返回 10,000 个匹配项,这是由于 Elasticsearch 集群中的内部安全机制。 |
SearchResult 中获取所有匹配项SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.id().matchingAny( Arrays.asList( 1, 2 ) ) )
.fetchAll();
long totalHitCount = result.total().hitCount();
List<Book> hits = result.hits();List<Book> hits = searchSession.search( Book.class )
.where( f -> f.id().matchingAny( Arrays.asList( 1, 2 ) ) )
.fetchAllHits();获取总数(命中次数等)
SearchResultTotal 包含与查询匹配的总匹配次数,无论它们是属于当前页面还是不属于当前页面。有关分页,请参见 分页。
默认情况下,总匹配次数是精确的,但在以下情况下可以使用较低界估计值来代替
-
启用了
totalHitCountThreshold选项。请参见totalHitCountThreshold(…):优化总匹配次数计算。 -
启用了
truncateAfter选项并且发生超时。
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.fetch( 20 );
SearchResultTotal resultTotal = result.total(); (1)
long totalHitCount = resultTotal.hitCount(); (2)
long totalHitCountLowerBound = resultTotal.hitCountLowerBound(); (3)
boolean hitCountExact = resultTotal.isHitCountExact(); (4)
boolean hitCountLowerBound = resultTotal.isHitCountLowerBound(); (5)| 1 | 从 SearchResult 中提取 SearchResultTotal。 |
| 2 | 检索精确的总匹配次数。如果仅提供较低界估计值,则此调用将引发异常。 |
| 3 | 检索总匹配次数的较低界估计值。如果可用,这将返回精确的匹配次数。 |
| 4 | 测试计数是否精确。 |
| 5 | 测试计数是否为较低界。 |
totalHitCountThreshold(…):优化总匹配次数计算
在处理大型结果集时,精确地计算匹配次数可能非常耗费资源。
当按分数排序(默认)并通过 fetch(…) 检索结果时,允许 Hibernate Search 返回总匹配次数的较低界估计值,而不是精确的总匹配次数,可以显着提高性能。在这种情况下,底层引擎(Lucene 或 Elasticsearch)将能够跳过大型的非竞争性匹配项块,从而导致更少的索引扫描,进而提高性能。
要启用此性能优化,在构建查询时调用 totalHitCountThreshold(…),如下面的示例所示。
|
此优化在以下情况下无效
|
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.totalHitCountThreshold( 1000 ) (1)
.fetch( 20 );
SearchResultTotal resultTotal = result.total(); (2)
long totalHitCountLowerBound = resultTotal.hitCountLowerBound(); (3)
boolean hitCountExact = resultTotal.isHitCountExact(); (4)
boolean hitCountLowerBound = resultTotal.isHitCountLowerBound(); (5)| 1 | 为当前查询定义一个 totalHitCountThreshold |
| 2 | 从 SearchResult 中提取 SearchResultTotal。 |
| 3 | 检索总匹配次数的较低界估计值。如果可用,这将返回精确的匹配次数。 |
| 4 | 测试计数是否精确。 |
| 5 | 测试计数是否为较低界估计值。 |
分页
分页是将搜索结果分成连续的“页面”的概念,所有页面都包含固定数量的元素(最后一个页面可能除外)。在网页上显示结果时,用户可以转到任意页面并查看相应的结果,例如“14,265 条结果中的第 151 到 170 条”。
Hibernate Search 通过向 fetch 或 fetchHits 方法传递偏移量和限制来实现分页。
-
偏移量定义了应跳过的文档数量,因为这些文档已在之前的页面中显示。它是一个 **文档数量**,而不是页面数量,因此您通常需要根据页码和页面大小来计算它,方法如下:
offset = zero-based-page-number * page-size。 -
限制定义了要返回的最大命中数,即页面大小。
SearchResultSearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.fetch( 40, 20 ); (1)| 1 | 将偏移量设置为 40,限制设置为 20。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.fetchHits( 40, 20 ); (1)| 1 | 将偏移量设置为 40,限制设置为 20。 |
|
两个页面之间的检索过程中索引可能会被修改。由于这种修改,某些命中可能改变位置,并最终出现在两个后续页面上。 如果您正在运行批处理过程并希望避免这种情况,请使用 滚动。 |
滚动
滚动是在搜索查询的最低级别保持游标,并逐步推进该游标以收集后续的搜索命中“块”的概念。
滚动依赖于游标的内部状态(该状态必须在某个时间点关闭),因此不适合无状态操作,例如在网页中向用户显示一页结果。但是,由于这种内部状态,滚动能够保证所有返回的命中都是一致的:给定的命中绝对不可能出现两次。
因此,滚动在将大型结果集作为小块处理时最有用。
以下是在 Hibernate Search 中使用滚动的示例。
SearchScroll 公开了一个 close() 方法,该方法 **必须** 被调用以避免资源泄漏。 |
|
使用 Elasticsearch 后端时,滚动可能会在一段时间后超时并变得不可用;有关更多信息,请参阅 此处。 |
try ( SearchScroll<Book> scroll = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.scroll( 20 ) ) { (1)
for ( SearchScrollResult<Book> chunk = scroll.next(); (2)
chunk.hasHits(); chunk = scroll.next() ) { (3)
for ( Book hit : chunk.hits() ) { (4)
// ... do something with the hits ...
}
totalHitCount = chunk.total().hitCount(); (5)
entityManager.flush(); (6)
entityManager.clear(); (6)
}
}| 1 | 启动滚动,它将返回 20 个命中的块。请注意,滚动在 try-with-resource 块中使用,以避免资源泄漏。 |
| 2 | 通过调用 next() 检索第一个块。每个块将包含最多 20 个命中,因为这是选定的块大小。 |
| 3 | 通过对最后一个检索到的块调用 hasHits() 来检测滚动的结束,并通过再次对滚动调用 next() 来检索下一个块。 |
| 4 | 检索一个块的命中。 |
| 5 | 可选地,检索匹配实体的总数。 |
| 6 | 可选地,如果使用 Hibernate ORM 并检索实体,您可能希望使用 定期的“flush-clear”模式 来确保实体不会留在会话中,从而占用越来越多的内存。 |
15.1.4. 路由
|
有关分片的初步介绍,包括它在 Hibernate Search 中的工作原理及其局限性,请参见 分片和路由。 |
如果对于给定的索引,存在一个文档经常被过滤的不可变值,例如“类别”或“用户 ID”,则可以使用路由键而不是谓词来匹配具有此值的文档。
与谓词相比,路由键的主要优点是,除了过滤文档外,路由键还会过滤 分片。如果启用了分片,这意味着在查询执行期间只会扫描索引的一部分,这可能会提高搜索性能。
|
在搜索查询中使用路由的先决条件是在索引时以这种方式映射您的实体,以便 它被分配一个路由键。 |
在构建查询时,通过调用 .routing(String) 或 .routing(Collection<String>) 方法来指定路由键。
SearchResult<Book> result = searchSession.search( Book.class ) (1)
.where( f -> f.match()
.field( "genre" )
.matching( Genre.SCIENCE_FICTION ) ) (2)
.routing( Genre.SCIENCE_FICTION.name() ) (3)
.fetch( 20 ); (4)| 1 | 开始构建查询。 |
| 2 | 定义只有与给定 genre 匹配的文档才会返回。 |
| 3 | 在本例中,实体以这种方式映射,即 genre 也用作路由键。我们知道所有文档都将具有给定的 genre 值,因此我们可以指定路由键以将查询限制为相关分片。 |
| 4 | 构建查询并获取结果。 |
15.1.5. Hibernate ORM 的实体加载选项
使用 Hibernate ORM 映射器时,Hibernate Search 会执行数据库查询以加载作为搜索查询命中的部分返回的实体。
本节介绍与搜索查询中的实体加载相关的所有可用选项。
缓存查找策略
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
默认情况下,Hibernate Search 将直接从数据库加载实体,而不会查看任何缓存。当缓存大小(Hibernate ORM 会话或二级缓存)远小于已索引实体总数时,这是一个很好的策略。
如果您的实体中有很大一部分存在于二级缓存中,则可以强制 Hibernate Search 尽可能从持久性上下文(会话)和/或二级缓存中检索实体。Hibernate Search 仍然需要执行数据库查询以检索缓存中缺少的实体,但查询可能只需要获取更少的实体,从而提高性能并减轻数据库的压力。
这是通过缓存查找策略来实现的,可以通过设置配置属性 hibernate.search.query.loading.cache_lookup.strategy 来配置它。
-
skip(默认值)不会执行任何缓存查找。 -
persistence-context仅会查看持久性上下文,即会检查实体是否已加载到会话中。如果预期大多数搜索命中已加载到会话中,这很有用,但这一般不太可能。 -
persistence-context-then-second-level-cache会首先查看持久性上下文,然后查看二级缓存(如果在 Hibernate ORM 中为搜索的实体启用了二级缓存)。如果预期大多数搜索命中已缓存,这很有用,如果您的实体数量少且缓存很大,这可能是可能的。
|
在为给定实体类型使用二级缓存之前,需要在 Hibernate ORM 中进行一些配置。 有关更多信息,请参阅 Hibernate ORM 文档的缓存部分。 |
还可以在每个查询的基础上覆盖配置的策略,如下所示。
SearchResult<Book> result = searchSession.search( Book.class ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.loading( o -> o.cacheLookupStrategy( (2)
EntityLoadingCacheLookupStrategy.PERSISTENCE_CONTEXT_THEN_SECOND_LEVEL_CACHE
) )
.fetch( 20 ); (3)| 1 | 开始构建查询。 |
| 2 | 访问查询的加载选项,然后提及在从数据库加载实体之前应检查持久性上下文和二级缓存。 |
| 3 | 获取结果。在持久性上下文或二级缓存中找到的实体越多,从数据库加载的实体就越少。 |
获取大小
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
默认情况下,Hibernate Search 将使用 100 的获取大小,这意味着对于单个查询的单个 fetch*() 调用,它将运行第一个查询以加载前 100 个实体,然后如果有更多命中,它将运行第二个查询以加载接下来的 100 个实体,等等。
可以通过设置配置属性 hibernate.search.query.loading.fetch_size 来配置获取大小。此属性期望一个严格为正的 整数值。
还可以在每个查询的基础上覆盖配置的获取大小,如下所示。
SearchResult<Book> result = searchSession.search( Book.class ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.loading( o -> o.fetchSize( 50 ) ) (2)
.fetch( 200 ); (3)| 1 | 开始构建查询。 |
| 2 | 访问查询的加载选项,然后将获取大小设置为任意值(必须为 1 或更大)。 |
| 3 | 获取结果,限制为前 200 个命中。如果命中数少于给定的获取大小,则将执行一个查询以加载命中;如果命中数大于获取大小但小于获取大小的两倍,则将执行两个查询,等等。 |
实体图
|
此功能仅适用于 Hibernate ORM 集成。 它**不能**与 独立 POJO 映射器 特别是。 |
默认情况下,Hibernate Search 将根据映射的默认值加载关联:标记为延迟的关联将不会加载,而标记为急切的关联将在返回实体之前加载。
可以通过在查询中引用实体图来强制加载延迟关联或阻止加载急切关联。有关示例,请参阅下文,有关实体图的更多信息,请参阅 Hibernate ORM 文档的本节。
EntityManager entityManager = /* ... */
EntityGraph<Manager> graph = entityManager.createEntityGraph( Manager.class ); (1)
graph.addAttributeNodes( "associates" );
SearchResult<Manager> result = Search.session( entityManager ).search( Manager.class ) (2)
.where( f -> f.match()
.field( "name" )
.matching( "james" ) )
.loading( o -> o.graph( graph, GraphSemantic.FETCH ) ) (3)
.fetch( 20 ); (4)| 1 | 构建实体图。 |
| 2 | 开始构建查询。 |
| 3 | 访问查询的加载选项,然后将实体图设置为上面构建的图。您还必须传递一个语义:GraphSemantic.FETCH 表示只会加载图中引用的关联;GraphSemantic.LOAD 表示图中引用的关联 **以及** 映射中标记为 EAGER 的关联将被加载。 |
| 4 | 获取结果。通过此搜索查询加载的所有管理者都将拥有已填充的 associates 关联。 |
除了当场构建实体图之外,您还可以使用 @NamedEntityGraph 注释静态定义实体图,并将您的图的名称传递给 Hibernate Search,如下所示。有关 @NamedEntityGraph 的更多信息,请参阅 Hibernate ORM 文档的本节。
SearchResult<Manager> result = Search.session( entityManager ).search( Manager.class ) (1)
.where( f -> f.match()
.field( "name" )
.matching( "james" ) )
.loading( o -> o.graph( "preload-associates", GraphSemantic.FETCH ) ) (2)
.fetch( 20 ); (3)| 1 | 开始构建查询。 |
| 2 | 访问查询的加载选项,然后将实体图设置为“preload-associates”,它是在其他地方使用 @NamedEntityGraph 注释定义的。 |
| 3 | 获取结果。通过此搜索查询加载的所有管理者都将拥有已填充的 associates 关联。 |
15.1.6. 超时
您可以通过两种方式限制搜索查询执行所需的时间
-
使用
failAfter()在达到时间限制时中止(抛出异常)。 -
使用
truncateAfter()在达到时间限制时截断结果。
|
目前,这两种方法不兼容:尝试同时设置 |
failAfter():在给定时间后中止查询
通过在构建查询时调用 failAfter(…),可以为查询执行设置时间限制。一旦达到时间限制,Hibernate Search 将停止查询执行并抛出 SearchTimeoutException。
|
超时是在尽力而为的基础上处理的。 根据内部时钟的分辨率以及 Hibernate Search 检查该时钟的频率,查询执行可能会超过超时。Hibernate Search 将尝试尽量减少这种超额执行时间。 |
try {
SearchResult<Book> result = searchSession.search( Book.class ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.failAfter( 500, TimeUnit.MILLISECONDS ) (2)
.fetch( 20 ); (3)
}
catch (SearchTimeoutException e) { (4)
// ...
}| 1 | 像往常一样构建查询。 |
| 2 | 调用failAfter设置超时时间。 |
| 3 | 获取结果。 |
| 4 | 如有必要,捕获异常。 |
|
|
truncateAfter():在给定时间后截断结果
通过在构建查询时调用truncateAfter(…),可以为搜索结果的收集设置时间限制。一旦达到时间限制,Hibernate Search 将停止收集匹配项并返回不完整的结果。
|
超时是在尽力而为的基础上处理的。 根据内部时钟的分辨率以及 Hibernate Search 检查该时钟的频率,查询执行可能会超过超时。Hibernate Search 将尝试尽量减少这种超额执行时间。 |
SearchResult<Book> result = searchSession.search( Book.class ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.truncateAfter( 500, TimeUnit.MILLISECONDS ) (2)
.fetch( 20 ); (3)
Duration took = result.took(); (4)
Boolean timedOut = result.timedOut(); (5)| 1 | 像往常一样构建查询。 |
| 2 | 调用truncateAfter设置超时时间。 |
| 3 | 获取结果。 |
| 4 | 可选地提取took:查询执行所花费的时间。 |
| 5 | 可选地提取timedOut:查询是否超时。 |
|
|
15.1.7. 设置查询参数
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
某些查询元素可能利用查询参数。在查询级别调用.param(..)设置这些参数
List<Manager> managers = searchSession.search( Manager.class )
.where(
//...
)
.param( "param1", "name" )
.param( "param2", 10 )
.param( "param3", LocalDate.of( 2002, 02, 20 ) )
.fetchAllHits();另请参阅
15.1.8. 获取查询对象
本文档中大多数示例都在查询定义 DSL 的末尾直接获取查询结果,没有显示任何可操作的“查询”对象。这是因为查询对象通常只会使代码更冗长,而不会带来任何有益的东西。
但是,在某些情况下,查询对象可能会有用。要获取查询对象,只需在查询定义的末尾调用toQuery()
SearchQuery对象SearchQuery<Book> query = searchSession.search( Book.class ) (1)
.where( f -> f.matchAll() )
.toQuery(); (2)
List<Book> hits = query.fetchHits( 20 ); (3)| 1 | 像往常一样构建查询。 |
| 2 | 检索SearchQuery对象。 |
| 3 | 获取结果。 |
Hibernate Search 提供了对 JPA 和 Hibernate ORM 的本机 API 的适配器,即一种将SearchQuery转换为javax.persistence.TypedQuery(JPA)或org.hibernate.query.Query(本机 ORM API)的方法
SearchQuery转换为 JPA 或 Hibernate ORM 查询SearchQuery<Book> query = searchSession.search( Book.class ) (1)
.where( f -> f.matchAll() )
.toQuery(); (2)
jakarta.persistence.TypedQuery<Book> jpaQuery = Search.toJpaQuery( query ); (3)
org.hibernate.query.Query<Book> ormQuery = Search.toOrmQuery( query ); (4)| 1 | 像往常一样构建查询。 |
| 2 | 检索SearchQuery对象。 |
| 3 | 将SearchQuery对象转换为 JPA 查询。 |
| 4 | 将SearchQuery对象转换为 Hibernate ORM 查询。 |
|
生成的查询不支持所有操作,因此建议仅在绝对必要时转换搜索查询,例如在与仅使用 Hibernate ORM 查询的代码集成时。 以下操作预计在大多数情况下都能正常工作,即使它们的行为可能与在某些情况下对 JPA
以下操作已知无法正常工作,目前没有修复计划
|
15.1.9. explain(…):解释分数
为了解释特定文档的分数,使用toQuery()创建一个SearchQuery对象,并在查询定义的末尾使用其中一种后端特定的explain(…)方法;这些方法的结果将包含对特定文档的分数是如何计算的的人类可读描述。
|
无论使用哪种 API,解释在性能方面都相当昂贵:仅将其用于调试目的。 |
LuceneSearchQuery<Book> query = searchSession.search( Book.class )
.extension( LuceneExtension.get() ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.toQuery(); (2)
Explanation explanation1 = query.explain( 1 ); (3)
Explanation explanation2 = query.explain( "Book", 1 ); (4)
LuceneSearchQuery<Book> luceneQuery = query.extension( LuceneExtension.get() ); (5)| 1 | 像往常一样构建查询,但使用 Lucene 扩展,以便检索到的查询公开 Lucene 特定的操作。 |
| 2 | 检索SearchQuery对象。 |
| 3 | 检索 ID 为1的实体的分数解释。解释的类型为Explanation,但可以使用toString()将其转换为可读的字符串。 |
| 4 | 对于多索引查询,需要不仅通过其 ID,还要通过其类型的名称来引用实体。 |
| 5 | 如果您无法更改构建查询的代码以使用 Lucene 扩展,则可以在创建后在SearchQuery上使用 Lucene 扩展来转换它。 |
ElasticsearchSearchQuery<Book> query = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.toQuery(); (2)
JsonObject explanation1 = query.explain( 1 ); (3)
JsonObject explanation2 = query.explain( "Book", 1 ); (4)
ElasticsearchSearchQuery<Book> elasticsearchQuery = query.extension( ElasticsearchExtension.get() ); (5)| 1 | 像往常一样构建查询,但使用 Elasticsearch 扩展,以便检索到的查询公开 Elasticsearch 特定的操作。 |
| 2 | 检索SearchQuery对象。 |
| 3 | 检索 ID 为1的实体的分数解释。 |
| 4 | 对于多索引查询,需要不仅通过其 ID,还要通过其类型的名称来引用实体。 |
| 5 | 如果您无法更改构建查询的代码以使用 Elasticsearch 扩展,则可以在创建后在SearchQuery上使用 Elasticsearch 扩展来转换它。 |
15.1.10. took和timedOut:找出查询花费了多长时间
SearchQuery<Book> query = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.toQuery();
SearchResult<Book> result = query.fetch( 20 ); (1)
Duration took = result.took(); (2)
Boolean timedOut = result.timedOut(); (3)| 1 | 获取结果。 |
| 2 | 提取took:查询花费的时间(在 Elasticsearch 的情况下,忽略应用程序和 Elasticsearch 集群之间的网络延迟)。 |
| 3 | 提取timedOut:查询是否超时(在 Elasticsearch 的情况下,忽略应用程序和 Elasticsearch 集群之间的网络延迟)。 |
15.1.11. Elasticsearch:利用 JSON 操作来利用高级功能
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
Elasticsearch 附带了许多功能。可能在某个时刻,您需要的某个功能不会被 Search DSL 公开。
为了解决这些限制,Hibernate Search 提供了以下方法
-
转换发送到 Elasticsearch 的用于搜索查询的 HTTP 请求。
-
读取从 Elasticsearch 收到的用于搜索查询的 HTTP 响应的原始 JSON。
|
对 HTTP 请求的直接更改可能会与 Hibernate Search 功能冲突,并且不同版本的 Elasticsearch 对其支持的方式也不同。 类似地,HTTP 响应的内容可能会根据 Elasticsearch 的版本而变化,具体取决于使用了哪些 Hibernate Search 功能,甚至取决于 Hibernate Search 功能的实现方式。 因此,依赖于对 HTTP 请求或响应的直接访问的功能无法保证在升级 Hibernate Search 时继续工作,即使是微升级( 使用它需自行承担风险。 |
大多数简单的用例只需要稍微更改 HTTP 请求,如下所示。
List<Book> hits = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.requestTransformer( context -> { (2)
Map<String, String> parameters = context.parametersMap(); (3)
parameters.put( "search_type", "dfs_query_then_fetch" );
JsonObject body = context.body(); (4)
body.addProperty( "min_score", 0.5f );
} )
.fetchHits( 20 ); (5)| 1 | 像往常一样构建查询,但使用 Elasticsearch 扩展,以便 Elasticsearch 特定的选项可用。 |
| 2 | 向查询添加请求转换器。每当要向 Elasticsearch 发送请求时,它的transform方法都会被调用。 |
| 3 | 在transform方法中,更改 HTTP 查询参数。 |
| 4 | 也可以像这里所示更改请求的 JSON 主体,甚至更改请求的路径(本例中未显示)。 |
| 5 | 像往常一样检索结果。 |
对于更复杂的用例,可以访问 HTTP 响应的原始 JSON,如下所示。
ElasticsearchSearchResult<Book> result = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robt" ) )
.requestTransformer( context -> { (2)
JsonObject body = context.body();
body.add( "suggest", jsonObject( suggest -> { (3)
suggest.add( "my-suggest", jsonObject( mySuggest -> {
mySuggest.addProperty( "text", "robt" );
mySuggest.add( "term", jsonObject( term -> {
term.addProperty( "field", "title" );
} ) );
} ) );
} ) );
} )
.fetch( 20 ); (4)
JsonObject responseBody = result.responseBody(); (5)
JsonArray mySuggestResults = responseBody.getAsJsonObject( "suggest" ) (6)
.getAsJsonArray( "my-suggest" );| 1 | 像往常一样构建查询,但使用 Elasticsearch 扩展,以便 Elasticsearch 特定的选项可用。 |
| 2 | 向查询添加请求转换器。 |
| 3 | 向请求主体添加内容,以便 Elasticsearch 在响应中返回更多数据。这里要求 Elasticsearch 应用一个建议器。 |
| 4 | 像往常一样检索结果。由于在构建查询时使用了 Elasticsearch 扩展,因此结果为ElasticsearchSearchResult,而不是通常的SearchResult。 |
| 5 | 将响应主体作为JsonObject获取。 |
| 6 | 从响应主体中提取有用的信息。这里正在提取我们上面配置的建议器结果。 |
|
Gson 的 API 用于构建 JSON 对象非常冗长,因此上面的示例依赖于一个小的自定义帮助器方法来使代码更具可读性 |
|
当需要从每个命中中提取数据时,使用 |
15.1.12. Lucene:检索底层组件
Lucene 查询允许检索某些底层组件。这应该只对集成人员有用,但为了完整起见,这里有文档记录。
LuceneSearchQuery<Book> query = searchSession.search( Book.class )
.extension( LuceneExtension.get() ) (1)
.where( f -> f.match()
.field( "title" )
.matching( "robot" ) )
.sort( f -> f.field( "title_sort" ) )
.toQuery(); (2)
Sort sort = query.luceneSort(); (3)
LuceneSearchResult<Book> result = query.fetch( 20 ); (4)
TopDocs topDocs = result.topDocs(); (5)| 1 | 像往常一样构建查询,但使用 Lucene 扩展,以便 Lucene 特定的选项可用。 |
| 2 | 由于在构建查询时使用了 Lucene 扩展,因此查询为LuceneSearchQuery,而不是通常的SearchQuery。 |
| 3 | 检索此查询依赖的org.apache.lucene.search.Sort。 |
| 4 | 像往常一样检索结果。LuceneSearchQuery返回LuceneSearchResult,而不是通常的SearchResult。 |
| 5 | 检索此结果的org.apache.lucene.search.TopDocs。请注意,TopDocs根据fetch方法的参数(如果有)进行偏移。 |
15.2. 谓词 DSL
15.2.1. 基础知识
搜索查询的主要组成部分是谓词,即每个文档必须满足的条件才能被包含在搜索结果中。
在构建搜索查询时配置谓词
SearchSession searchSession = /* ... */ (1)
List<Book> result = searchSession.search( Book.class ) (2)
.where( f -> f.match().field( "title" ) (3)
.matching( "robot" ) )
.fetchHits( 20 ); (4)| 1 | 检索 SearchSession. |
| 2 | 开始构建查询。 |
| 3 | 提及查询结果预计具有与值robot匹配的title字段。如果字段不存在或无法进行搜索,则会抛出异常。 |
| 4 | 获取与给定谓词匹配的结果。 |
或者,如果您不想使用 lambda
SearchSession searchSession = /* ... */
SearchScope<Book> scope = searchSession.scope( Book.class );
List<Book> result = searchSession.search( scope )
.where( scope.predicate().match().field( "title" )
.matching( "robot" )
.toPredicate() )
.fetchHits( 20 );谓词 DSL 提供了更多谓词类型,以及每种谓词类型的多种选项。要了解有关match谓词以及所有其他谓词类型的更多信息,请参阅以下部分。
15.2.2. matchAll:匹配所有文档
matchAll谓词只匹配所有文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.fetchHits( 20 );except(…):排除与给定谓词匹配的文档
可选地,您可以从命中中排除一些文档
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll()
.except( f.match().field( "title" )
.matching( "robot" ) )
)
.fetchHits( 20 );其他选项
-
matchAll谓词的评分默认情况下是常数,等于 1,但可以通过 使用.boost(…)提升。
15.2.3. matchNone:不匹配任何文档
matchNone 谓词是 matchAll 的逆运算,不匹配任何文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchNone() )
.fetchHits( 20 );15.2.4. id:匹配文档标识符
id 谓词通过文档标识符匹配文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.id().matching( 1 ) )
.fetchHits( 20 );您也可以在单个谓词中匹配多个 ID
List<Integer> ids = new ArrayList<>();
ids.add( 1 );
ids.add( 2 );
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.id().matchingAny( ids ) )
.fetchHits( 20 );预期参数类型
默认情况下,id 谓词期望 matching(…)/matchingAny(…) 方法的参数与对应于文档 ID 的实体属性具有相同的类型。
例如,如果文档标识符是从类型为 Long 的实体标识符生成的,则文档标识符将仍然是 String 类型。matching(…)/matchingAny(…) 将期望其参数为 Long 类型,无论如何。
这通常是你想要的,但如果你需要绕过转换并将未转换的参数(String 类型)传递给 matching(…)/matchingAny(…),请参见 传递给 DSL 的参数类型。
其他选项
-
id谓词的评分默认情况下是常数,等于 1,但可以通过 使用.boost(…)提升。
15.2.5. match:匹配值
match 谓词匹配给定字段具有给定值的文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match().field( "title" )
.matching( "robot" ) )
.fetchHits( 20 );预期参数类型
默认情况下,match 谓词期望 matching(…) 方法的参数与对应于目标字段的实体属性具有相同的类型。
例如,如果实体属性是枚举类型,则对应的字段可能为 String 类型。.matching(…) 将期望其参数具有枚举类型,无论如何。
这通常是你想要的,但如果你需要绕过转换并将未转换的参数(如上例中的 String 类型)传递给 .matching(…),请参见 传递给 DSL 的参数类型。
分析
对于大多数字段类型(数字、日期等),匹配是精确的。但是,对于 全文 字段或 规范化关键字 字段,传递给 matching(…) 方法的值将在与索引中的值比较之前进行分析或规范化。这意味着匹配更微妙,有两个方面。
首先,谓词不会只匹配给定字段具有完全相同值的文档:它将匹配所有给定字段具有规范化形式相同的文档。请参见下面的示例。
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.match().field( "lastName" )
.matching( "ASIMOV" ) )(1)
.fetchHits( 20 );
assertThat( hits ).extracting( Author::getLastName )
.contains( "Asimov" );(2)| 1 | 对于分析/规范化字段,传递给 matching 的值将被分析/规范化。在这种情况下,分析结果是小写字符串:asimov。 |
| 2 | 所有返回的匹配项都将具有规范化形式相同的词语。在这种情况下,Asimov 也被规范化为 asimov,因此它匹配。 |
其次,对于 全文 字段,传递给 matching(…) 方法的值将被分词。这意味着可以从输入值中提取多个词语,谓词将匹配所有给定字段具有包含任何这些词语的值的文档,无论位置和顺序。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match().field( "title" )
.matching( "ROBOT Dawn" ) ) (1)
.fetchHits( 20 );
assertThat( hits ).extracting( Book::getTitle )
.contains( "The Robots of Dawn", "I, Robot" ); (2)| 1 | 对于全文字段,传递给 matching 的值将被分词和规范化。在这种情况下,分析结果是词语 robot 和 dawn(注意它们是小写的)。 |
| 2 | 所有返回的匹配项将匹配给定字符串的至少一个词语。The Robots of Dawn 包含规范化词语 robot 和 dawn,因此它匹配,但 I, Robot 也匹配,即使它不包含 dawn:只需要一个词语即可。 |
|
匹配多个词语或匹配更相关词语的匹配项将具有更高的 评分。因此,如果你按评分排序,最相关的匹配项将出现在结果列表的顶部。这通常弥补了谓词不需要匹配文档中所有词语这一事实。 |
|
如果你需要匹配文档中所有词语,你应该可以使用 |
fuzzy:近似匹配文本值
.fuzzy() 选项允许近似匹配,即它允许匹配给定字段具有与传递给 matching(…) 的值不完全相同的值,但接近的值,例如有一个字母被替换成另一个字母的文档。
| 此选项仅适用于文本字段。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" )
.matching( "robto" )
.fuzzy() )
.fetchHits( 20 );粗略地说,编辑距离是两个词语之间的更改次数:交换字符、删除字符等。它在启用模糊匹配时默认为 2,但也可以设置为 0(禁用模糊匹配)或 1(只允许一次更改,因此“不太模糊”。)大于 2 的值不允许。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" )
.matching( "robto" )
.fuzzy( 1 ) )
.fetchHits( 20 );可选地,你可以强制匹配对前 n 个字符进行精确匹配。n 称为“精确前缀长度”。出于性能原因,对于包含大量不同词语的索引,建议将此值设置为非零值。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" )
.matching( "robto" )
.fuzzy( 1, 3 ) )
.fetchHits( 20 );minimumShouldMatch:微调需要匹配的词语数量
可以要求匹配字符串中的任意数量的词语出现在文档中,以便 match 谓词匹配。这是 minimumShouldMatch* 方法的目的,如下所示。
minimumShouldMatch 微调匹配要求List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" )
.matching( "investigation detective automatic" )
.minimumShouldMatchNumber( 2 ) ) (1)
.fetchHits( 20 ); (2)| 1 | 此谓词至少需要匹配两个词语才能匹配。 |
| 2 | 所有返回的匹配项将至少匹配两个词语:它们的标题将匹配 investigation 和 detective,investigation 和 automatic,detective 和 automatic,或所有三个词语。 |
其他选项
-
match谓词的评分默认情况下对于文本字段是可变的,但可以通过 使用.constantScore()使其成为常数。 -
match谓词的评分可以 提升,无论是在每个字段的基础上使用.field(…)/.fields(…)之后的.boost(…)调用,还是使用.matching(…)之后的.boost(…)调用提升整个谓词。
15.2.6. range:匹配值的范围
range 谓词匹配给定字段具有给定范围内的值的文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.range().field( "pageCount" )
.between( 210, 250 ) )
.fetchHits( 20 );between 方法包含两个边界,即值恰好为其中一个边界的文档将匹配 range 谓词。
必须提供至少一个边界。如果边界为 null,它将不限制匹配。例如,.between( 2, null ) 将匹配所有大于或等于 2 的值。
可以调用不同的方法来代替 between,以控制上下边界的包含情况
atLeast-
示例 206. 匹配等于或大于给定值的文档
List<Book> hits = searchSession.search( Book.class ) .where( f -> f.range().field( "pageCount" ) .atLeast( 400 ) ) .fetchHits( 20 ); greaterThan-
示例 207. 匹配严格大于给定值的文档
List<Book> hits = searchSession.search( Book.class ) .where( f -> f.range().field( "pageCount" ) .greaterThan( 400 ) ) .fetchHits( 20 ); atMost-
示例 208. 匹配等于或小于给定值的文档
List<Book> hits = searchSession.search( Book.class ) .where( f -> f.range().field( "pageCount" ) .atMost( 400 ) ) .fetchHits( 20 ); lessThan-
示例 209. 匹配严格小于给定值的文档
List<Book> hits = searchSession.search( Book.class ) .where( f -> f.range().field( "pageCount" ) .lessThan( 400 ) ) .fetchHits( 20 );
或者,您可以显式指定边界是否包含或排除
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.range().field( "pageCount" )
.between(
200, RangeBoundInclusion.EXCLUDED,
250, RangeBoundInclusion.EXCLUDED
) )
.fetchHits( 20 );List<Book> hits = searchSession.search( Book.class )
.where( f -> f.range().field( "pageCount" )
.withinAny(
Range.between( 200, 250 ),
Range.between( 500, 800 )
) )
.fetchHits( 20 );预期参数类型
默认情况下,range 谓词期望 between(…)/atLeast(…)/etc. 方法的参数与对应于目标字段的实体属性具有相同的类型。
例如,如果实体属性是 java.util.Date 类型,则对应的字段可能为 java.time.Instant 类型;between(…)/atLeast(…)/etc. 将期望其参数为 java.util.Date 类型,无论如何。类似地,range(…) 将期望 Range<java.util.Date> 类型的参数。
这通常是你想要的,但如果你需要绕过转换并将未转换的参数(如上例中的 java.time.Instant 类型)传递给 between(…)/atLeast(…)/etc.,请参见 传递给 DSL 的参数类型。
其他选项
-
range谓词的评分默认情况下是常数,等于 1,但可以通过 提升,无论是在每个字段的基础上使用.field(…)/.fields(…)之后的.boost(…)调用,还是使用.between(…)/atLeast(…)/etc. 之后的.boost(…)调用提升整个谓词。
15.2.7. phrase:匹配词语序列
phrase 谓词匹配给定字段包含给定词语序列(按给定顺序)的文档。
| 此谓词仅适用于 全文字段。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.phrase().field( "title" )
.matching( "robots of dawn" ) )
.fetchHits( 20 );slop:近似匹配词语序列
指定slop 允许近似匹配,即它允许匹配给定字段包含给定词语序列,但顺序略有不同或包含额外的词语的文档。
斜率表示可以应用于单词序列以匹配的编辑操作数,其中每个编辑操作将一个单词移动一个位置。因此,斜率为 1 的 quick fox 可以变成 quick <word> fox,其中 <word> 可以是任何单词。斜率为 2 的 quick fox 可以变成 quick <word> fox,或 quick <word1> <word2> fox,甚至 fox quick(两个操作:将 fox 向左移动,将 quick 向右移动)。对于更高的斜率和包含更多单词的短语,也是如此。
slop(…) 近似匹配单词序列List<Book> hits = searchSession.search( Book.class )
.where( f -> f.phrase().field( "title" )
.matching( "dawn robot" )
.slop( 3 ) )
.fetchHits( 20 );其他选项
-
默认情况下,
phrase谓词的分数是可变的,但可以 使用.constantScore()使其成为常数。 -
phrase谓词的分数可以 增强,可以在.field(…)/.fields(…)之后调用.boost(…)对每个字段进行增强,或者在.matching(…)之后调用.boost(…)对整个谓词进行增强。
15.2.8. exists:匹配包含内容的字段
exists 谓词匹配给定字段具有非空值的文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.exists().field( "comment" ) )
.fetchHits( 20 );|
没有内置谓词来匹配给定字段为 null 的文档,但是您可以轻松地自己创建一个,方法是否定 这可以通过将 |
对象字段
exists 谓词也可以应用于对象字段。在这种情况下,它将匹配所有给定对象字段的至少一个内部字段具有非空值的文档。
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.exists().field( "placeOfBirth" ) )
.fetchHits( 20 );|
对象字段需要至少包含一个具有内容的内部字段,才能被视为“存在”。 让我们考虑上面的例子,假设
因此,最好在已知至少包含一个永远不为 null 的内部字段的对象字段上使用 |
其他选项
-
默认情况下,
exists谓词的分数为常数,等于 1,但可以 使用.boost(…)增强。
15.2.9. wildcard:匹配简单模式
wildcard 谓词匹配给定字段包含匹配给定模式的单词的文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.wildcard().field( "description" )
.matching( "rob*t" ) )
.fetchHits( 20 );模式可能包含以下字符
-
*匹配零个、一个或多个字符。 -
?匹配零个或一个字符。 -
\转义后面的字符,例如\?被解释为文字?,\\被解释为文字\等。 -
任何其他字符都被解释为文字。
|
如果在字段上定义了规范器,则通配符谓词中使用的模式将被规范化。 如果在字段上定义了分析器
例如,当目标字段具有在索引时应用小写过滤器规范器时, 当目标字段在空格上进行标记化时, 当目标是匹配用户提供的查询字符串时,应优先使用 简单查询字符串谓词。 |
其他选项
-
默认情况下,
wildcard谓词的分数为常数,等于 1,但可以 增强,可以在.field(…)/.fields(…)之后调用.boost(…)对每个字段进行增强,或者在.matching(…)之后调用.boost(…)对整个谓词进行增强。
15.2.10. regexp:匹配正则表达式模式
regexp 谓词匹配给定字段包含匹配给定正则表达式的单词的文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.regexp().field( "description" )
.matching( "r.*t" ) )
.fetchHits( 20 );正则表达式谓词和分析
| 有关分析以及如何配置分析的介绍,请参阅 分析 部分。 |
正则表达式谓词对分析/规范化字段的行为有点复杂,因此以下是它的工作原理的总结。
- 正则表达式必须匹配 **整个** 分析/规范化标记
-
对于在空格上进行小写和标记化的字段(使用分析器),正则表达式
robots?-
将匹配
Robot:索引标记robot匹配。 -
将匹配
I love robots:索引标记robots匹配。 -
将 **不** 匹配
Mr. Roboto:索引标记roboto不匹配。对于进行小写但不进行标记化的字段(使用规范器),正则表达式
robots? -
将匹配
Robot:索引标记robot匹配。 -
将 **不** 匹配
I love robots:索引标记i love robots不匹配。 -
将 **不** 匹配
Mr. Roboto:索引标记mr. roboto不匹配。
-
- 正则表达式永远不会被标记化,即使字段被标记化也是如此
-
特别要注意正则表达式中的空格。
对于在空格上进行标记化的字段(使用分析器),正则表达式
.*love .* robots?将永远不会匹配任何内容,因为它需要标记内的空格,而索引标记不包含任何空格(因为标记化发生在空格上)。对于进行小写但不进行标记化的字段(使用规范器),正则表达式
.*love .* robots?-
将匹配
I love robots,它被索引为i love robots。 -
将匹配
I love my Robot,它被索引为i love my robot。 -
将 **不** 匹配
I love Mr. Roboto,它被索引为i love mr. roboto:roboto不匹配robots?。
-
- 使用 Lucene 后端时,正则表达式永远不会被分析或规范化
-
对于进行小写和空格标记化的字段
-
正则表达式
Robots?不会被规范化,并且永远不会匹配任何内容,因为它需要大写字母,而索引标记不包含任何大写字母(因为它们是小写的)。 -
正则表达式
[Rr]obots?不会被规范化,但将匹配I love Robots:索引标记robots匹配。 -
正则表达式
love .* robots?不会被规范化,并且将匹配I love my Robot以及I love robots,但不会匹配Robots love me。
-
- 使用 Elasticsearch 后端时,正则表达式不会在文本(标记化)字段上进行分析或规范化,但在 **关键字(非标记化)字段上进行规范化**
-
对于进行小写和空格标记化的字段(使用分析器)
-
正则表达式
Robots?不会被规范化,并且永远不会匹配任何内容,因为它需要大写字母,而索引标记不包含任何大写字母(因为它们是小写的)。 -
正则表达式
[Rr]obots?不会被规范化,但将匹配I love Robots:索引标记robots匹配。 -
正则表达式
love .* robots?不会被规范化,并且将匹配I love my Robot以及I love robots,但不会匹配Robots love me。但是,**规范化字段的行为与 Lucene 不同!** 对于进行小写但不进行标记化的字段(使用规范器)
-
正则表达式
Robots?+将被规范化为robots?,并且将匹配I love robots:索引标记robots匹配。 -
正则表达式
[Rr]obots?+将被规范化为[rr]obots?,并且将匹配I love Robots:索引标记robots匹配。 -
正则表达式
love .* robots?将匹配I love my Robot以及I love robots,但不会匹配Robots love me。由于 Elasticsearch 会规范化正则表达式,因此规范器会干扰正则表达式元字符,并完全改变正则表达式的含义。
例如,对于规范器将
*和?字符替换为_的字段,正则表达式Robots?将被规范化为Robots_,并且可能永远不会匹配任何内容。此行为被视为错误,并且已 报告给 Elasticsearch 项目。
-
flags:仅启用特定语法结构
默认情况下,Hibernate Search 不会启用任何可选运算符。要启用其中一些,可以指定 flags 属性。
hits = searchSession.search( Book.class )
.where( f -> f.regexp().field( "description" )
.matching( "r@t" )
.flags( RegexpQueryFlag.ANY_STRING )
)
.fetchHits( 20 );以下标志/运算符可用
-
INTERVAL:<>运算符匹配非负整数范围,两端都包括在内。例如,
a<1-10>匹配a1、a2、…a9、a10,但不匹配a11。前导零是有意义的,例如
a<01-10>匹配a01和a02,但不匹配a1或a2。 -
INTERSECTION:&运算符使用 AND 运算符组合两个正则表达式。例如,
.*a.*&.*z.*匹配az、za、babzb、bzbab,但不匹配a或z。 -
ANYSTRING:@运算符匹配任何字符串;等效于.*。此运算符主要用于否定模式,例如
@&~(ab)匹配除字符串ab之外的任何内容。
其他选项
-
默认情况下,
regexp谓词的分数为常数,等于 1,但可以 增强,可以在.field(…)/.fields(…)之后调用.boost(…)对每个字段进行增强,或者在.matching(…)之后调用.boost(…)对整个谓词进行增强。
15.2.11. terms:匹配一组术语
terms 谓词匹配给定字段包含某些术语的文档,所有或部分术语。
matchingAny 期望传递 **术语**,而不仅仅是任何字符串。给定的术语不会被分析。请参阅 `terms` 谓词和分析。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.terms().field( "genre" )
.matchingAny( Genre.CRIME_FICTION, Genre.SCIENCE_FICTION ) )
.fetchHits( 20 );
matchingAll 期望传递 **术语**,而不仅仅是任何字符串。给定的术语不会被分析。请参阅 `terms` 谓词和分析。 |
|
默认情况下,`matchingAll` 不会接受超过 1024 个术语。 可以通过后端特定的配置提高此限制。
但是,请记住,限制的存在是有原因的:尝试匹配非常大量的术语会导致性能低下,甚至可能导致崩溃。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.terms().field( "genre" )
.matchingAny( Genre.CRIME_FICTION, Genre.SCIENCE_FICTION ) )
.fetchHits( 20 );terms 谓词和分析
| 有关分析以及如何配置分析的介绍,请参阅 分析 部分。 |
与其他谓词不同,传递给 `matchingAny()` 或 `matchingAll()` 的术语永远不会被分析,也 **通常** 不会被规范化。
|
如果在字段上定义了分析器,则术语不会被分析或规范化。 如果在字段上定义了规范器
例如,术语 `Cat` 可以在目标字段具有应用小写过滤器以进行索引的规范器时匹配 `cat`,但仅在使用 Elasticsearch 后端时。在使用 Lucene 后端时,只有术语 `cat` 可以匹配 `cat`。 |
预期参数类型
默认情况下,`terms` 谓词期望 `matchingAny(…)` 或 `matchingAll(…)` 方法的参数与对应于目标字段的实体属性具有相同的类型。
例如,如果实体属性是枚举类型,则对应字段可能为 `String` 类型。`matchingAny(…)` 将期望其参数具有枚举类型,无论如何。
这通常是你想要的,但如果你需要绕过转换并传递未转换的参数(在上面的示例中为 `String` 类型)到 `matchingAny(…)` 或 `matchingAll(…)`,请参阅 传递给 DSL 的参数类型。
其他选项
-
`terms` 谓词的分数默认情况下为常数,等于 1,但可以 提升,可以在字段基础上调用 `field(…)`/`fields(…)` 后的 `boost(…)`,或者在整个谓词上调用 `matchingAny(…)` 或 `matchingAll(…)` 后的 `boost(…)`。
15.2.12. `and`:匹配所有子句
`and` 谓词匹配与所有内部谓词(称为“子句”)匹配的文档。
匹配的“and”子句在 得分 计算期间被考虑在内。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.and(
f.match().field( "title" )
.matching( "robot" ), (1)
f.match().field( "description" )
.matching( "crime" ) (2)
) )
.fetchHits( 20 ); (3)| 1 | 命中 **必须** 具有与文本 `robot` 匹配的 `title` 字段,与同一布尔谓词中的其他子句无关。 |
| 2 | 命中 **必须** 具有与文本 `crime` 匹配的 `description` 字段,与同一布尔谓词中的其他子句无关。 |
| 3 | 所有返回的命中 **必须** 与以上所有子句匹配:它们将具有与文本 `robot` 匹配的 `title` 字段,**并且** 它们将具有与文本 `crime` 匹配的 `description` 字段。 |
使用 lambda 语法动态添加子句
可以在 lambda 表达式中定义 `and` 谓词。这在需要动态向 `and` 谓词添加子句时尤其有用,例如根据用户输入。
MySearchParameters searchParameters = getSearchParameters(); (1)
List<Book> hits = searchSession.search( Book.class )
.where( (f, root) -> { (2)
root.add( f.matchAll() ); (3)
if ( searchParameters.getGenreFilter() != null ) { (4)
root.add( f.match().field( "genre" )
.matching( searchParameters.getGenreFilter() ) );
}
if ( searchParameters.getFullTextFilter() != null ) {
root.add( f.match().fields( "title", "description" )
.matching( searchParameters.getFullTextFilter() ) );
}
if ( searchParameters.getPageCountMaxFilter() != null ) {
root.add( f.range().field( "pageCount" )
.atMost( searchParameters.getPageCountMaxFilter() ) );
}
} )
.fetchHits( 20 );| 1 | 获取一个自定义对象,该对象保存用户通过 Web 表单提供的搜索参数,例如。 |
| 2 | 调用 `where(BiConsumer)`。由 lambda 表达式实现的消费者将接收谓词工厂和子句收集器作为参数,并将根据需要将子句添加到该收集器中。 |
| 3 | 默认情况下,布尔谓词如果没有子句将不匹配任何内容。要在没有子句时匹配所有文档,请添加一个匹配所有内容的 `and` 子句。 |
| 4 | 在 lambda 内部,代码可以自由使用任何 Java 语言结构,例如 `if` 或 `for`,来控制子句的添加。在本例中,我们仅在用户填写了相关参数时才添加子句。 |
当 `and` 谓词不是根谓词时,另一种依赖于方法 `with(…)` 的语法可能很有用
MySearchParameters searchParameters = getSearchParameters(); (1)
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.and().with( and -> { (2)
and.add( f.matchAll() ); (3)
if ( searchParameters.getGenreFilter() != null ) { (4)
and.add( f.match().field( "genre" )
.matching( searchParameters.getGenreFilter() ) );
}
if ( searchParameters.getFullTextFilter() != null ) {
and.add( f.match().fields( "title", "description" )
.matching( searchParameters.getFullTextFilter() ) );
}
if ( searchParameters.getPageCountMaxFilter() != null ) {
and.add( f.range().field( "pageCount" )
.atMost( searchParameters.getPageCountMaxFilter() ) );
}
} ) )
.fetchHits( 20 );| 1 | 获取一个自定义对象,该对象保存用户通过 Web 表单提供的搜索参数,例如。 |
| 2 | 调用 `where(Function)`。由 lambda 表达式实现的函数将接收谓词工厂,使用它构建一个 `and` 谓词,调用 `with(Consumer)` 方法并返回该谓词。由 lambda 表达式实现的消费者将接收 `and` 谓词的子句收集器作为参数,并将根据需要将子句添加到该收集器中。 |
| 3 | 默认情况下,布尔谓词如果没有子句将不匹配任何内容。要在没有子句时匹配所有文档,请添加一个匹配所有内容的 `and` 子句。 |
| 4 | 在 lambda 内部,代码可以自由使用任何 Java 语言结构,例如 `if` 或 `for`,来控制子句的添加。在本例中,我们仅在用户填写了相关参数时才添加子句。 |
选项
-
`and` 谓词的分数默认情况下是可变的,但可以 使用 `constantScore()` 使其成为常数。
-
`and` 谓词的分数可以通过调用 `boost(…)` 来 提升。
15.2.13. `or`:匹配任何子句
`or` 谓词匹配与任何内部谓词(称为“子句”)匹配的文档。
匹配的 `or` 子句在 得分 计算期间被考虑在内。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.or(
f.match().field( "title" )
.matching( "robot" ), (1)
f.match().field( "description" )
.matching( "investigation" ) (2)
) )
.fetchHits( 20 ); (3)| 1 | 命中 **应该** 具有与文本 `robot` 匹配的 `title` 字段,**或者** 它们应该与同一布尔谓词中的任何其他子句匹配。 |
| 2 | 命中 **应该** 具有与文本 `investigation` 匹配的 `description` 字段,**或者** 它们应该与同一布尔谓词中的任何其他子句匹配。 |
| 3 | 所有返回的命中 **至少** 与以上一个子句匹配:它们将具有与文本 `robot` 匹配的 `title` 字段,**或者** 它们将具有与文本 `investigation` 匹配的 `description` 字段。 |
使用 lambda 语法动态添加子句
可以在 lambda 表达式中定义 `or` 谓词。这在需要动态向 `or` 谓词添加子句时尤其有用,例如根据用户输入。
MySearchParameters searchParameters = getSearchParameters(); (1)
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.or().with( or -> { (2)
if ( !searchParameters.getAuthorFilters().isEmpty() ) {
for ( String authorFilter : searchParameters.getAuthorFilters() ) { (3)
or.add( f.match().fields( "authors.firstName", "authors.lastName" )
.matching( authorFilter ) );
}
}
} ) )
.fetchHits( 20 );| 1 | 获取一个自定义对象,该对象保存用户通过 Web 表单提供的搜索参数,例如。0 |
| 2 | 调用 `where(Function)`。由 lambda 表达式实现的函数将接收谓词工厂,使用它构建一个 `or` 谓词,调用 `with(Consumer)` 方法并返回该谓词。由 lambda 表达式实现的消费者将接收 `or` 谓词的子句收集器作为参数,并将根据需要将子句添加到该收集器中。 |
| 3 | 在 lambda 内部,代码可以自由使用任何 Java 语言结构,例如 `if` 或 `for`,来控制子句的添加。在本例中,我们仅在用户填写了相关参数时才添加子句。 |
选项
-
`or` 谓词的分数默认情况下是可变的,但可以 使用 `constantScore()` 使其成为常数。
-
`or` 谓词的分数可以通过调用 `boost(…)` 来 提升。
15.2.14. `not`:否定另一个谓词
`not` 谓词匹配与给定谓词不匹配的文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.not(
f.match()
.field( "genre" )
.matching( Genre.SCIENCE_FICTION )
) )
.fetchHits( 20 );其他选项
-
`not` 谓词的分数默认情况下为常数,等于 0,但如果 使用 `boost(…)` 提升,则默认值将更改为 1,并将应用相应的提升。
15.2.15. `bool`:谓词的 advanced 组合 (or/and/…)
`bool` 谓词匹配与一个或多个内部谓词(称为“子句”)匹配的文档。它可用于构建 `AND` / `OR` 运算符,并具有附加设置。
内部谓词作为以下类型之一的子句添加
must-
`must` 子句是必需匹配的:如果它们不匹配,则 `bool` 谓词将不匹配。
匹配的“must”子句在 得分 计算期间被考虑在内。
mustNot-
`mustNot` 子句是必需不匹配的:如果它们匹配,则 `bool` 谓词将不匹配。
“must not”子句在 得分 计算期间被忽略。
filter-
`filter` 子句是必需匹配的:如果它们不匹配,则布尔谓词将不匹配。
`filter` 子句在 得分 计算期间被忽略,因此包含在过滤器子句中的布尔谓词的任何子句(即使是 `must` 或 `should` 子句)也会被忽略。
should-
`should` 子句可以选择匹配,并且根据上下文要求匹配。
匹配的 `should` 子句在 得分 计算期间被考虑在内。
`should` 子句的确切行为如下
-
当 `bool` 谓词中没有任何 `must` 子句或 `filter` 子句时,至少需要匹配一个“should”子句。简而言之,在这种情况下,“should”子句的行为就像它们之间存在一个 `OR` 运算符一样。
-
当 `bool` 谓词中至少存在一个 `must` 子句或一个 `filter` 子句时,则“should”子句不需要匹配,并且仅用于评分。
-
可以通过指定
minimumShouldMatch约束 来更改此行为。
-
模拟 `OR` 运算符
仅包含 `should` 子句且没有 minimumShouldMatch 规范 的 `bool` 谓词将表现为 `OR` 运算符。在这种情况下,建议使用更简单的 `or` 语法。
模拟 `AND` 运算符
仅包含 `must` 子句的 `bool` 谓词将表现为 `AND` 运算符。在这种情况下,建议使用更简单的 and 语法。
mustNot:排除与给定谓词匹配的文档
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.bool()
.must( f.match().field( "title" )
.matching( "robot" ) ) (1)
.mustNot( f.match().field( "description" )
.matching( "investigation" ) ) (2)
)
.fetchHits( 20 ); (3)| 1 | 命中 **必须** 具有与文本 `robot` 匹配的 `title` 字段,与同一布尔谓词中的其他子句无关。 |
| 2 | 命中结果 **不能** 包含与文本 `investigation` 匹配的 `description` 字段,与同一布尔谓词中的其他子句无关。 |
| 3 | 所有返回的命中结果将匹配上述 **所有** 子句:它们将包含与文本 `robot` 匹配的 `title` 字段 **并且** 它们将不包含与文本 `investigation` 匹配的 `description` 字段。 |
|
虽然可以执行只包含 "否定" 子句(`mustNot`)的布尔谓词,但性能可能令人失望,因为在这种情况下无法充分利用索引的功能。 |
filter:匹配与给定谓词匹配的文档,但不影响分数
filter 子句本质上是 `must` 子句,只有一点不同:它们在计算文档的总 分数 时被忽略。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.bool() (1)
.should( f.bool() (2)
.filter( f.match().field( "genre" )
.matching( Genre.SCIENCE_FICTION ) ) (3)
.must( f.match().fields( "description" )
.matching( "crime" ) ) (4)
)
.should( f.bool() (5)
.filter( f.match().field( "genre" )
.matching( Genre.CRIME_FICTION ) ) (6)
.must( f.match().fields( "description" )
.matching( "robot" ) ) (7)
)
)
.fetchHits( 20 ); (8)| 1 | 创建一个顶级的布尔谓词,包含两个 `should` 子句。 |
| 2 | 在第一个 `should` 子句中,创建一个嵌套的布尔谓词。 |
| 3 | 使用 `filter` 子句要求文档具有 `science-fiction` 类型,在评分时不考虑此谓词。 |
| 4 | 使用 `must` 子句要求具有 `science-fiction` 类型的文档具有与 `crime` 匹配的 `title` 字段,并在评分时考虑此谓词。 |
| 5 | 在第二个 `should` 子句中,创建一个嵌套的布尔谓词。 |
| 6 | 使用 `filter` 子句要求文档具有 `crime fiction` 类型,在评分时不考虑此谓词。 |
| 7 | 使用 `must` 子句要求具有 `crime fiction` 类型的文档具有与 `robot` 匹配的 `description` 字段,并在评分时考虑此谓词。 |
| 8 | 命中结果的分数将忽略 `filter` 子句,如果 "crime fiction" 文档比 "science-fiction" 文档多得多,则会导致更公平的排序。 |
should 作为调整评分的一种方式
除了 单独使用模拟 `OR` 运算符 之外,`should` 子句也可以与 `must` 子句一起使用。在这种情况下,`should` 子句将完全可选,它们的唯一目的是提高与这些子句匹配的文档的分数。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.bool()
.must( f.match().field( "title" )
.matching( "robot" ) ) (1)
.should( f.match().field( "description" )
.matching( "crime" ) ) (2)
.should( f.match().field( "description" )
.matching( "investigation" ) ) (3)
)
.fetchHits( 20 ); (4)| 1 | 命中 **必须** 具有与文本 `robot` 匹配的 `title` 字段,与同一布尔谓词中的其他子句无关。 |
| 2 | 命中结果 **应该** 包含与文本 `crime` 匹配的 `description` 字段,但它们可能不包含,因为与上面的 `must` 子句匹配就足够了。但是,匹配此 `should` 子句将提高文档的分数。 |
| 3 | 命中结果 **应该** 包含与文本 `investigation` 匹配的 `description` 字段,但它们可能不包含,因为与上面的 `must` 子句匹配就足够了。但是,匹配此 `should` 子句将提高文档的分数。 |
| 4 | 所有返回的命中结果将匹配 `must` 子句,并可选地匹配 `should` 子句:它们将包含与文本 `robot` 匹配的 `title` 字段,而那些描述与 `crime` 或 `investigation` 匹配的命中结果将具有更高的分数。 |
minimumShouldMatch:微调需要匹配的 `should` 子句数量
可以要求任意数量的 `should` 子句匹配,以使 `bool` 谓词匹配。这就是 `minimumShouldMatch*` 方法的目的,如下所示。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.bool()
.minimumShouldMatchNumber( 2 ) (1)
.should( f.match().field( "description" )
.matching( "robot" ) ) (2)
.should( f.match().field( "description" )
.matching( "investigation" ) ) (3)
.should( f.match().field( "description" )
.matching( "disappearance" ) ) (4)
)
.fetchHits( 20 ); (5)| 1 | 为了使此布尔谓词匹配,至少需要两个 "should" 子句匹配。 |
| 2 | 命中结果 **应该** 包含与文本 `robot` 匹配的 `description` 字段。 |
| 3 | 命中结果 **应该** 包含与文本 `investigate` 匹配的 `description` 字段。 |
| 4 | 命中结果 **应该** 包含与文本 `crime` 匹配的 `description` 字段。 |
| 5 | 所有返回的命中结果将匹配至少两个 `should` 子句:它们的描述将匹配 `robot` 和 `investigate`、`robot` 和 `crime`、`investigate` 和 `crime`,或者所有三个术语。 |
使用 lambda 语法动态添加子句
可以在 lambda 表达式中定义 `bool` 谓词。当需要动态将子句添加到 `bool` 谓词中时,这特别有用,例如根据用户输入。
如果你只是想构建一个匹配多个动态生成的子句的根谓词,请考虑使用 .where( (f, root) → … ) 语法 代替。 |
MySearchParameters searchParameters = getSearchParameters(); (1)
List<Book> hits = searchSession.search( Book.class )
.where( (f, root) -> { (2)
root.add( f.matchAll() );
if ( searchParameters.getGenreFilter() != null ) {
root.add( f.match().field( "genre" )
.matching( searchParameters.getGenreFilter() ) );
}
if ( !searchParameters.getAuthorFilters().isEmpty() ) {
root.add( f.bool().with( b -> { (3)
for ( String authorFilter : searchParameters.getAuthorFilters() ) { (4)
b.should( f.match().fields( "authors.firstName", "authors.lastName" )
.matching( authorFilter ) );
}
} ) );
}
} )
.fetchHits( 20 );| 1 | 获取一个自定义对象,该对象保存用户通过 Web 表单提供的搜索参数,例如。 |
| 2 | 调用 .where(BiConsumer) 创建根谓词,这不是我们这里感兴趣的谓词。 |
| 3 | 调用 .bool().with(Consumer) 创建一个内部的、非根谓词。由 lambda 表达式实现的消费者将接收一个收集器作为参数,并根据需要将子句添加到该收集器中。 |
| 4 | 在 lambda 内部,代码可以自由使用任何 Java 语言结构,例如 `if` 或 `for`,来控制子句的添加。在本例中,我们为每个作者过滤器添加一个子句。 |
已弃用的变体
|
本节中详细介绍的功能已 *弃用*:应该避免使用它们,而应使用非弃用的替代方案。 通常的 兼容性策略 适用,这意味着这些功能预计至少在 Hibernate Search 的下一个主要版本之前仍然可用。除此之外,它们可能会以与以前不兼容的方式更改,甚至被删除。 不建议使用已弃用的功能。 |
可以使用另一种语法来 从 lambda 表达式创建布尔谓词,但它已弃用。
.bool 的已弃用变体MySearchParameters searchParameters = getSearchParameters(); (1)
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.bool( b -> { (2)
b.must( f.matchAll() ); (3)
if ( searchParameters.getGenreFilter() != null ) { (4)
b.must( f.match().field( "genre" )
.matching( searchParameters.getGenreFilter() ) );
}
if ( searchParameters.getFullTextFilter() != null ) {
b.must( f.match().fields( "title", "description" )
.matching( searchParameters.getFullTextFilter() ) );
}
if ( searchParameters.getPageCountMaxFilter() != null ) {
b.must( f.range().field( "pageCount" )
.atMost( searchParameters.getPageCountMaxFilter() ) );
}
} ) )
.fetchHits( 20 );| 1 | 获取一个自定义对象,该对象保存用户通过 Web 表单提供的搜索参数,例如。 |
| 2 | 调用 .bool(Consumer)。由 lambda 表达式实现的消费者将接收一个收集器作为参数,并根据需要将子句添加到该收集器中。 |
| 3 | 默认情况下,如果布尔谓词没有子句,则它将不匹配任何内容。如果要匹配所有文档,即使没有子句,也要添加一个匹配所有内容的 `must` 子句。 |
| 4 | 在 lambda 内部,代码可以自由使用任何 Java 语言结构,例如 `if` 或 `for`,来控制子句的添加。在本例中,我们仅在用户填写了相关参数时才添加子句。 |
其他选项
-
默认情况下,`bool` 谓词的分数是可变的,但可以使用
.constantScore()使其成为常数。 -
可以使用对
.boost(…)的调用来 提升 `bool` 谓词的分数。
15.2.16. simpleQueryString:匹配用户提供的查询字符串
simpleQueryString 谓词根据作为字符串给出的结构化查询匹配文档。
它的语法非常简单,因此在最终用户期望能够提交包含一些语法元素(如布尔运算符、引号等)的文本查询时,它特别有用。
布尔运算符
该语法包括三个布尔运算符
-
使用 `+` 表示 AND
-
使用 `|` 表示 OR
-
使用 `-` 表示 NOT
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "description" )
.matching( "robots + (crime | investigation | disappearance)" ) )
.fetchHits( 20 );List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "description" )
.matching( "robots + -investigation" ) )
.fetchHits( 20 );默认布尔运算符
默认情况下,如果未显式定义运算符,则查询将使用 OR 运算符。如果希望使用 AND 运算符作为默认运算符,则可以调用 .defaultOperator(…)。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "description" )
.matching( "robots investigation" )
.defaultOperator( BooleanOperator.AND ) )
.fetchHits( 20 );前缀
该语法通过 `*` 通配符支持前缀谓词。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "description" )
.matching( "rob*" ) )
.fetchHits( 20 );| `*` 通配符只会被理解为单词的结尾。`rob*t` 将被解释为字面量。这确实是 *前缀* 谓词,而不是 *通配符* 谓词。 |
模糊匹配
该语法支持模糊运算符 `~`。它的行为类似于 match 谓词中的模糊匹配。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "description" )
.matching( "robto~2" ) )
.fetchHits( 20 );短语
该语法支持使用引号括起来的要匹配的术语序列来进行 phrase 谓词。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "title" )
.matching( "\"robots of dawn\"" ) )
.fetchHits( 20 );可以使用 NEAR 运算符 `~` 为短语谓词分配一个 slop。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "title" )
.matching( "\"dawn robot\"~3" ) )
.fetchHits( 20 );flags:仅启用特定语法结构
默认情况下,所有语法功能都已启用。可以通过 .flags(…) 方法显式选择要启用的运算符。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "title" )
.matching( "I want a **robot**" )
.flags( SimpleQueryFlag.AND, SimpleQueryFlag.OR, SimpleQueryFlag.NOT ) )
.fetchHits( 20 );如果你愿意,可以禁用所有语法结构
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "title" )
.matching( "**robot**" )
.flags( Collections.emptySet() ) )
.fetchHits( 20 );minimumShouldMatch:微调需要匹配的 `should` 子句数量
从查询字符串解析的查询结果可能导致包含 should 子句的布尔查询。控制需要匹配多少个 `should` 子句才能将文档视为匹配项可能会有所帮助。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "title" )
.matching( "crime robot investigate automatic detective" )
.minimumShouldMatchNumber( 2 ) )
.fetchHits( 20 );目标多个字段
可选地,谓词可以定位多个字段。在这种情况下,谓词将匹配任何给定字段匹配的文档。
参见 在一个谓词中定位多个字段。
| 如果目标字段具有不同的分析器,则会抛出异常。你可以通过 显式选择分析器 来避免这种情况,但要确保你知道自己在做什么。 |
字段类型和字段值的预期格式
查询字符串中使用的字符串字面量的格式是特定于后端的。对于 Lucene 后端,这些字面量的格式应与 具有内置值桥的属性类型 中定义的解析逻辑兼容,对于具有自定义桥的字段,则必须定义。对于 Elasticsearch 后端,请参见 Elasticsearch 后端支持的字段类型。
其他选项
-
默认情况下,`simpleQueryString` 谓词的分数是可变的,但可以使用
.constantScore()使其成为常数。 -
simpleQueryString谓词的得分可以提升, 可以在调用.field(…)/.fields(…)之后,在每个字段的基础上使用.boost(…)调用, 或者在.matching(…)之后,使用.boost(…)对整个谓词进行调用。
15.2.17. nested:匹配嵌套文档
nested 谓词可以用于被索引为嵌套文档 的对象字段, 以要求两个或更多内部谓词匹配同一个对象。 这是如何确保 authors.firstname:isaac AND authors.lastname:asimov 不会匹配一个作者是 "Jane Asimov" 和 "Isaac Deutscher" 的书籍。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.nested( "authors" ) (1)
.add( f.match().field( "authors.firstName" )
.matching( "isaac" ) ) (2)
.add( f.match().field( "authors.lastName" )
.matching( "asimov" ) ) ) (3)
.fetchHits( 20 ); (4)| 1 | 在 authors 对象字段上创建嵌套谓词。 |
| 2 | 作者的第一个名字必须匹配 isaac。 |
| 3 | 作者的最后一个名字必须匹配 asimov。 |
| 4 | 所有返回的命中将是至少有一个作者的第一个名字匹配 isaac 并且最后一个名字匹配 asimov 的书籍。 碰巧有多个作者的书籍,其中一个作者的第一个名字匹配 isaac, 而另一个作者的最后一个名字匹配 asimov, 将不会匹配。 |
隐式嵌套
Hibernate Search 在必要时会自动在其他谓词周围包装一个嵌套谓词。 但是, 这是针对每个单个谓词进行的, 所以隐式嵌套不会像显式嵌套那样将多个内部谓词分组在一起。 请参见下面的示例。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.and()
.add( f.match().field( "authors.firstName" ) (1)
.matching( "isaac" ) ) (2)
.add( f.match().field( "authors.lastName" )
.matching( "asimov" ) ) ) (3)
.fetchHits( 20 ); (4)| 1 | 嵌套谓词是隐式创建的, 因为这里的目标字段属于一个嵌套对象。 |
| 2 | 作者的第一个名字必须匹配 isaac。 |
| 3 | 作者的最后一个名字必须匹配 asimov。 |
| 4 | 所有返回的命中将是至少有一个作者的第一个名字匹配 isaac 并且最后一个名字匹配 asimov 的书籍。 碰巧有多个作者的书籍,其中一个作者的第一个名字匹配 isaac, 而另一个作者的最后一个名字匹配 asimov, 将会匹配, 因为我们对每个匹配谓词都单独应用嵌套谓词。 |
已弃用的变体
|
本节中详细介绍的功能已 *弃用*:应该避免使用它们,而应使用非弃用的替代方案。 通常的 兼容性策略 适用,这意味着这些功能预计至少在 Hibernate Search 的下一个主要版本之前仍然可用。除此之外,它们可能会以与以前不兼容的方式更改,甚至被删除。 不建议使用已弃用的功能。 |
可以使用另一种语法来创建嵌套谓词, 但它更冗长, 并且已被弃用。
.nested 的已弃用变体List<Book> hits = searchSession.search( Book.class )
.where( f -> f.nested().objectField( "authors" ) (1)
.nest( f.and()
.add( f.match().field( "authors.firstName" )
.matching( "isaac" ) ) (2)
.add( f.match().field( "authors.lastName" )
.matching( "asimov" ) ) ) ) (3)
.fetchHits( 20 ); (4)| 1 | 在 authors 对象字段上创建嵌套谓词。 |
| 2 | 作者的第一个名字必须匹配 isaac。 |
| 3 | 作者的最后一个名字必须匹配 asimov。 |
| 4 | 所有返回的命中将是至少有一个作者的第一个名字匹配 isaac 并且最后一个名字匹配 asimov 的书籍。 碰巧有多个作者的书籍,其中一个作者的第一个名字匹配 isaac, 而另一个作者的最后一个名字匹配 asimov, 将不会匹配。 |
15.2.18. within:匹配圆形、矩形、多边形内的点
within 谓词匹配那些给定字段是包含在给定圆形、边界框或多边形内的地理点的文档。
| 此谓词仅适用于地理点字段。 |
匹配圆形内的点(在到点的距离内)
使用 .circle(…), 匹配的点必须在给定点(中心)的给定距离内。
GeoPoint center = GeoPoint.of( 53.970000, 32.150000 );
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.spatial().within().field( "placeOfBirth.coordinates" )
.circle( center, 50, DistanceUnit.KILOMETERS ) )
.fetchHits( 20 );还有其他距离单位可用, 特别是 METERS、 YARDS 和 MILES。 当省略距离单位时, 它默认为 METERS。 |
您还可以将中心的坐标作为两个双精度数传递(纬度, 然后是经度)。
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.spatial().within().field( "placeOfBirth.coordinates" )
.circle( 53.970000, 32.150000, 50, DistanceUnit.KILOMETERS ) )
.fetchHits( 20 );匹配边界框内的点
使用 .boundingBox(…), 匹配的点必须在由左上角和右下角定义的给定边界框内。
GeoBoundingBox box = GeoBoundingBox.of(
53.99, 32.13,
53.95, 32.17
);
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.spatial().within().field( "placeOfBirth.coordinates" )
.boundingBox( box ) )
.fetchHits( 20 );您还可以将左上角和右下角的坐标作为四个双精度数传递: 左上角纬度、 左上角经度、 右下角纬度、 右下角经度。
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.spatial().within().field( "placeOfBirth.coordinates" )
.boundingBox( 53.99, 32.13,
53.95, 32.17 ) )
.fetchHits( 20 );匹配多边形内的点
使用 .polygon(…), 匹配的点必须在给定的多边形内。
GeoPolygon polygon = GeoPolygon.of(
GeoPoint.of( 53.976177, 32.138627 ),
GeoPoint.of( 53.986177, 32.148627 ),
GeoPoint.of( 53.979177, 32.168627 ),
GeoPoint.of( 53.876177, 32.159627 ),
GeoPoint.of( 53.956177, 32.155627 ),
GeoPoint.of( 53.976177, 32.138627 )
);
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.spatial().within().field( "placeOfBirth.coordinates" )
.polygon( polygon ) )
.fetchHits( 20 );其他选项
-
within谓词的得分默认情况下是常数, 等于 1, 但可以提升, 可以在调用.field(…)/.fields(…)之后,在每个字段的基础上使用.boost(…)调用, 或者在.circle(…)/.boundingBox(…)/.polygon(…)之后,使用.boost(…)对整个谓词进行调用。
15.2.19. knn: K-近邻, 也称为向量搜索
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
knn 谓词(其中 k 是一个正整数)匹配给定向量字段的值与给定向量“最近”的 k 个文档。
距离是根据为给定的向量字段 配置的向量相似度进行衡量的。
float[] coverImageEmbeddingsVector = /*...*/
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.knn( 5 ).field( "coverImageEmbeddings" ).matching( coverImageEmbeddingsVector ) )
.fetchHits( 20 );预期参数类型
knn 谓词期望 matching(…) 方法的参数具有与目标字段的索引类型相同的类型。
例如, 如果一个实体属性在索引中映射到一个字节数组类型(byte[]), 则 .matching(…) 将期望其参数仅为一个字节数组(byte[])。
过滤邻居
可选地, 谓词可以使用谓词的 .filter(..) 子句过滤掉一些邻居。 .filter(…) 期望传递一个谓词。
float[] coverImageEmbeddingsVector = /*...*/
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.knn( 5 ).field( "coverImageEmbeddings" ).matching( coverImageEmbeddingsVector )
.filter( f.match().field( "authors.firstName" ).matching( "isaac" ) ) )
.fetchHits( 20 );将 knn 与其他谓词组合
knn 谓词可以与常规的文本搜索谓词组合。 通过根据向量嵌入特征增加相关文档的得分, 它可以提高搜索结果的质量。
float[] coverImageEmbeddingsVector = /*...*/
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.bool()
.must( f.match().field( "genre" ).matching( Genre.SCIENCE_FICTION ) ) (1)
.should( f.knn( 10 ).field( "coverImageEmbeddings" ).matching( coverImageEmbeddingsVector ) ) (2)
)
.fetchHits( 20 );| 1 | 查找科幻小说。 |
| 2 | 提高封面与我们正在搜索的封面相似的科幻小说的得分。 |
使用 knn 相似度过滤掉不相关的结果
knn 谓词本质上总是试图找到 k 个最近的向量, 即使找到的向量彼此之间相距很远, 即并不那么相似。 这可能会导致查询返回不相关的结果。
为了解决这个问题, knn 谓词允许配置所需的最小相似度。 如果配置了此项, knn 谓词将找到 k 个最近的向量, 并过滤掉任何相似度低于此配置阈值的向量。 请注意, 此属性的预期值是根据配置的向量相似度 计算的两个向量之间的距离值。
float[] coverImageEmbeddingsVector = /*...*/
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.knn( 5 ).field( "coverImageEmbeddings" ).matching( coverImageEmbeddingsVector ) (1)
.requiredMinimumSimilarity( 5 ) ) (2)
.fetchHits( 20 );| 1 | 像往常一样创建 knn 谓词。 |
| 2 | 指定所需的最小相似度值, 以过滤掉不相关的结果。 |
或者, 由于在 knn 谓词的情况下, 得分和相似度紧密相关, 如此表 所述, 有时可能更简单地应用基于得分的过滤器。
float[] coverImageEmbeddingsVector = /*...*/
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.knn( 5 ).field( "coverImageEmbeddings" ).matching( coverImageEmbeddingsVector ) (1)
.requiredMinimumScore( 0.5f ) ) (2)
.fetchHits( 20 );| 1 | 像往常一样创建 knn 谓词。 |
| 2 | 指定所需的最小得分值, 以过滤掉不相关的结果。 |
此配置在OpenSearch 分布的Elasticsearch 后端 中具有略微不同的行为。 此分布允许同时使用以下选项之一: k、 最小得分、 最小相似度。 因此, 如果应用了 requiredMinimumSimilarity(..) 或 requiredMinimumScore(..), 则 k 值将被忽略, 并且不会发送到 OpenSearch 集群。 |
后端细节和限制
参数 k 在后端及其分布之间具有不同的行为。
使用Lucene 后端 时, k 是将限制knn 谓词 匹配的最终文档数量的数字。 使用Elastic 分布的Elasticsearch 后端 时, k 将被视为 k 和 num_candidates。 有关更多详细信息, 请参见 Elasticsearch 文档。 而当使用OpenSearch 分布时, k 将映射到 knn 查询的 k 属性。 请注意, 在这种情况下, 当索引配置为具有多个分片时, 您可能会获得超过 k 个结果。 有关更多详细信息, 请参见 OpenSearch 文档 中的本节。
在具有 Elasticsearch 后端的嵌套谓词内使用 knn 谓词有一些限制。 特别是, 当隐式应用租户 或路由 过滤器时, 生成的结果可能包含少于预期的文档。 为了解决此限制, 需要进行模式更改, 并且应该在未来的主要版本之一中解决(HSEARCH-5085)。
其他选项
-
knn谓词的得分默认情况下是可变的(对于“更近”的文档, 得分更高), 但可以使用.constantScore()使得分变为常数。 -
knn谓词的得分可以在.matching(…)之后,使用.boost(…)调用,对整个谓词进行提升。
15.2.20. queryString:匹配用户提供的查询字符串
queryString 谓词根据作为字符串给出的结构化查询来匹配文档。 它允许构建更高级的查询字符串, 并且具有比simpleQueryString 谓词更多的配置选项。
在本指南中, 我们不会详细介绍查询语法的细节。 要熟悉它, 请参考您的后端(Elasticsearch/OpenSearch/Lucene)指南。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "description" )
.matching(
"robots +(crime investigation disappearance)^10 +\"investigation help\"~2 -/(dis)?a[p]+ea?ance/" ) ) (1)
.fetchHits( 20 );| 1 | 此查询字符串将生成一个包含 4 个子句的布尔查询
请注意, 上述每个子句最终都可能被翻译成其他类型的查询。 |
默认布尔运算符
默认情况下,如果未显式定义运算符,则查询将使用 OR 运算符。如果希望使用 AND 运算符作为默认运算符,则可以调用 .defaultOperator(…)。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "description" )
.matching( "robots investigation" )
.defaultOperator( BooleanOperator.AND ) )
.fetchHits( 20 );短语偏移量
短语 slop 选项定义了构造的短语谓词的容许度;换句话说,短语中允许多少个转置才能仍然被认为是匹配。对于查询谓词,此选项可以在查询字符串本身中设置。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "title" )
.matching( "\"dawn robot\"~3" ) )
.fetchHits( 20 );或者,.phraseSlop(…) 可以应用于查询字符串谓词。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "title" )
.matching( "\"dawn robot\"" )
.phraseSlop( 3 ) )
.fetchHits( 20 );请注意,将值传递给 .phraseSlop(…) 会设置默认的短语 slop 值,该值可以在查询字符串中覆盖。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "title" )
.matching( "\"dawn robot\"~3 -\"automatic detective\"" ) (1)
.phraseSlop( 1 ) ) (2)
.fetchHits( 20 );| 1 | 查询字符串是两个短语查询的组合。第一个短语查询 "dawn robot" 覆盖了默认的短语 slop 参数并将其设置为 3。第二个短语查询 "automatic detective" 使用在 (2) 中设置的默认短语 slop。 |
| 2 | 设置默认的短语 slop 值以应用于在查询字符串中未明确指定 slop 的短语查询。 |
允许前导通配符
默认情况下,查询字符串可以在查询中的任何位置使用通配符。如果需要阻止用户使用前导通配符,则可以调用 .allowLeadingWildcard(..),其值为 false 以禁止此类查询。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "title" )
.matching( "robo?" )
.allowLeadingWildcard( false ) )
.fetchHits( 20 );在此示例中,查询在单词末尾使用通配符;因此,无论选项值如何,它都是可接受的。如果提供类似 ?obot 或 *bot 的查询,并且同时禁止前导通配符,则会导致抛出异常。
请注意,此选项不仅会影响整个查询字符串,还会影响该查询字符串中的各个子句。例如,在查询字符串 robot ?etective 中,通配符 ? 不是前导字符,但此查询被分解为 robot 和 ?etecitve 的两个子句,在第二个子句中,? 通配符成为前导字符。
启用位置增量
默认情况下启用位置增量。默认情况下启用位置增量,允许短语查询考虑由 stopwords 过滤器删除的停用词。可以禁用位置增量,如下所示,这会导致短语查询的行为发生变化:假设文档中存在短语 book at the shelve,并且停用词过滤器删除了 at 和 the,在禁用位置增量的情况下,短语查询 "book shelve" 将不会匹配此类文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "title" )
.matching( "\"crime robots\"" )
.enablePositionIncrements( false ) )
.fetchHits( 20 );重写方法
重写方法确定后端的查询解析器如何重写和评分多项查询。
要更改默认的 CONSTANT_SCORE 重写方法,可以将允许的 RewriteMethod 枚举值之一传递给 .rewriteMethod(RewriteMethod)/rewriteMethod(RewriteMethod, int)。
请注意,即使默认的重写方法称为 CONSTANT_SCORE,但这并不意味着匹配的文档的最终分数在所有结果中都是恒定的,更多的是关于查询解析如何在内部工作。要为结果实现恒定分数,请参阅 此文档部分 中的查询字符串谓词。
本指南不会详细介绍不同的重写方法。要详细了解它们,请参阅您后端的指南 (Elasticsearch/OpenSearch/Lucene).
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.queryString().field( "title" )
.matching(
// some complex query string
)
.rewriteMethod( RewriteMethod.CONSTANT_SCORE_BOOLEAN ) )
.fetchHits( 20 );minimumShouldMatch:微调需要匹配多少个 should 子句
从查询字符串解析的查询结果可能导致包含 should 子句的布尔查询。控制需要匹配多少个 `should` 子句才能将文档视为匹配项可能会有所帮助。
minimumShouldMatch 微调 should 子句匹配要求List<Book> hits = searchSession.search( Book.class )
.where( f -> f.simpleQueryString().field( "title" )
.matching( "crime robot investigate automatic detective" )
.minimumShouldMatchNumber( 2 ) )
.fetchHits( 20 );定位多个字段
可选地,谓词可以定位多个字段。在这种情况下,谓词将匹配任何给定字段匹配的文档。
参见 在一个谓词中定位多个字段。
| 如果目标字段具有不同的分析器,则会抛出异常。你可以通过 显式选择分析器 来避免这种情况,但要确保你知道自己在做什么。 |
字段类型和预期字段值格式
查询字符串中使用的字符串字面量的格式是特定于后端的。对于 Lucene 后端,这些字面量的格式应与 具有内置值桥的属性类型 中定义的解析逻辑兼容,对于具有自定义桥的字段,则必须定义。对于 Elasticsearch 后端,请参见 Elasticsearch 后端支持的字段类型。
请记住,并非所有查询结构都可以应用于非字符串字段,例如,创建正则表达式查询、使用通配符/slop/模糊性将不起作用。
其他选项
-
默认情况下,
queryString谓词的分数是可变的,但可以通过 使用.constantScore()使其变为常数。 -
queryString谓词的分数可以 提升,无论是通过在.field(…)/.fields(…)之后立即调用.boost(…)以每字段为基础,还是通过在.matching(…)之后调用.boost(…)以整个谓词为基础。
15.2.21. prefix:根据字段的开头匹配文档
prefix 谓词匹配字段值以给定字符串开头的文档。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.prefix().field( "description" )
.matching( "rob" ) )
.fetchHits( 20 );|
如果在字段上定义了规范器,则前缀谓词中使用的前缀将被规范化。 如果在字段上定义了分析器
当目标是匹配用户提供的查询字符串时,应优先使用 简单查询字符串谓词。 此谓词也可能不适合自动完成目的。请参阅您特定后端的文档以确定实现自动完成功能的最佳选项。 |
15.2.22. named:调用映射中定义的谓词
可以调用 named 谓词(即映射中定义的谓词)并将其包含在查询中。
以下示例调用了 定义命名谓词 部分示例中的命名谓词。
List<ItemStock> hits = searchSession.search( ItemStock.class )
.where( f -> f.named( "skuId.skuIdMatch" ) (1)
.param( "pattern", "*.WI2012" ) ) (2)
.fetchHits( 20 );| 1 | 命名谓词由其名称引用,以定义谓词的对象路径和一个点作为前缀。 这里,谓词名为 |
| 2 | 命名谓词可以接受参数,这些参数将根据 定义命名谓词 中的说明进行处理。 |
15.2.23. withParameters:创建访问查询参数的谓词
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
withParameters 谓词允许使用 查询参数 构建谓词。当需要使用相同的谓词但不同的输入值执行查询时,或者当作为查询参数传递的相同输入值在查询的多个部分中使用时(例如,在谓词、投影、排序、聚合中),此谓词很有用。
此类型的谓词需要一个函数,该函数接受查询参数并返回一个谓词。该函数将在查询构建时被调用。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.withParameters( params -> f.bool() (1)
.should( f.match().field( "title" )
.matching( params.get( "title-param", String.class ) ) ) (2)
.filter( f.match().field( "genre" )
.matching( params.get( "genre-param", Genre.class ) ) ) (3)
) )
.param( "title-param", "robot" ) (4)
.param( "genre-param", Genre.CRIME_FICTION )
.fetchHits( 20 );| 1 | 开始创建 .withParameters() 谓词。 |
| 2 | 在构建谓词时访问 String 类型的查询参数 title-param。 |
| 3 | 在构建谓词时访问 Genre 枚举类型的查询参数 genre-param。 |
| 4 | 在查询级别设置谓词所需的 parameters。 |
15.2.24. 后端特定扩展
通过在构建查询时调用 .extension(…),可以访问后端特定的谓词。
|
顾名思义,后端特定的谓词不能从一个后端技术移植到另一个后端技术。 |
Lucene:fromLuceneQuery
.fromLuceneQuery(…) 将本机 Lucene Query 转换为 Hibernate Search 谓词。
|
此功能意味着应用程序代码直接依赖 Lucene API。 即使是针对错误修复(微型)版本的 Hibernate Search 升级也可能需要升级 Lucene,这可能会导致 Lucene 的 API 发生重大更改。 如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
org.apache.lucene.search.QueryList<Book> hits = searchSession.search( Book.class )
.extension( LuceneExtension.get() ) (1)
.where( f -> f.fromLuceneQuery( (2)
new RegexpQuery( new Term( "description", "neighbor|neighbour" ) )
) )
.fetchHits( 20 );| 1 | 像往常一样构建查询,但使用 Lucene 扩展,以便 Lucene 特定的选项可用。 |
| 2 | 添加由给定 Lucene Query 对象定义的谓词。 |
Elasticsearch:fromJson
.fromJson(…) 将表示 Elasticsearch 查询的 JSON 转换为 Hibernate Search 谓词。
|
此功能要求直接在应用程序代码中操作 JSON。 此 JSON 的语法可能会发生更改
如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
JsonObject 提供的本机 Elasticsearch JSON 查询JsonObject jsonObject =
/* ... */; (1)
List<Book> hits = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() ) (2)
.where( f -> f.fromJson( jsonObject ) ) (3)
.fetchHits( 20 );| 1 | 使用 Gson 构建 JSON 对象。 |
| 2 | 像往常一样构建查询,但使用 Lucene 扩展,以便 Lucene 特定的选项可用。 |
| 3 | 添加由给定 JsonObject 定义的谓词。 |
List<Book> hits = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() ) (1)
.where( f -> f.fromJson( "{" (2)
+ " \"regexp\": {"
+ " \"description\": \"neighbor|neighbour\""
+ " }"
+ "}" ) )
.fetchHits( 20 );| 1 | 像往常一样构建查询,但使用 Lucene 扩展,以便 Lucene 特定的选项可用。 |
| 2 | 添加由给定 JSON 格式字符串定义的谓词。 |
15.2.25. 多个谓词类型共有的选项
在单个谓词中定位多个字段
一些谓词提供在同一个谓词中定位多个字段的能力。
在这种情况下,谓词将匹配任何给定字段匹配的文档。
以下示例使用 match 谓词。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" ).field( "description" )
.matching( "robot" ) )
.fetchHits( 20 );List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.fields( "title", "description" )
.matching( "robot" ) )
.fetchHits( 20 );可以单独提升每个字段的分数;请参阅 提升谓词的分数。
调整分数
如果谓词匹配了文档,则每个谓词都会产生一个分数。对于给定谓词,文档的相关性越高,分数就越高。
当 按分数排序(默认排序)时,可以使用该分数来使结果列表顶部的命中率更高。
以下是一些调整分数的方法,从而充分利用相关性排序。
提升谓词的分数
每个谓词的分数可以分配一个乘数,称为boost
| boost 始终应大于 0。 |
以下示例使用 match 谓词。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.and(
f.match()
.field( "title" )
.matching( "robot" )
.boost( 2.0f ),
f.match()
.field( "description" )
.matching( "self-aware" )
) )
.fetchHits( 20 );对于针对多个字段的谓词,也可以通过在调用 .field(…)/.fields(…) 后调用 .boost(…) 来为给定字段(或一组字段)上的匹配分配更多重要性。
以下示例使用 match 谓词。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" ).boost( 2.0f )
.field( "description" )
.matching( "robot" ) )
.fetchHits( 20 );可变得分和固定得分
有些谓词默认情况下具有固定得分,因为对它们而言,可变得分没有意义。例如,id 谓词 默认情况下具有固定得分。
具有固定得分的谓词对文档总得分的影响是“非此即彼”:要么文档匹配,它将从该谓词的得分中获益(默认情况下为 1.0f,但可以boost),要么它不匹配,它将不会从该谓词的得分中获益。
具有可变得分的谓词对得分的影响更加微妙。例如,match 谓词 在文本字段上将对包含要匹配的项多次的文档产生更高的得分。
当不希望出现这种“可变得分”行为时,您可以通过调用 .constantScore() 来抑制它。如果只有谓词匹配的事实相关,而文档的内容无关紧要,这可能很有用。
以下示例使用 match 谓词。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.and(
f.match()
.field( "genre" )
.matching( Genre.SCIENCE_FICTION )
.constantScore(),
f.match()
.field( "title" )
.matching( "robot" )
.boost( 2.0f )
) )
.fetchHits( 20 );或者,您可以利用布尔谓词中的filter 子句,它等效于 must 子句,但完全抑制了子句对得分的影响。 |
覆盖分析
在某些情况下,可能需要使用不同的分析器来分析搜索文本,而不是用于分析索引文本的分析器。
这可以通过调用 .analyzer(…) 并传递要使用的分析器的名称来实现。
以下示例使用 match 谓词。
如果您始终在搜索时应用相同的分析器,您可能希望在您的字段上配置一个搜索分析器。这样,您在搜索时就不需要使用 .analyzer(…) 了。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title_autocomplete" )
.matching( "robo" )
.analyzer( "autocomplete_query" ) )
.fetchHits( 20 );如果您需要完全禁用搜索文本的分析,请调用 .skipAnalysis()。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match()
.field( "title" )
.matching( "robot" )
.skipAnalysis() )
.fetchHits( 20 );15.3. 排序 DSL
15.3.1. 基础知识
默认情况下,查询结果按匹配得分(相关性)排序。在构建搜索查询时,可以配置其他排序,包括按字段值排序。
SearchSession searchSession = /* ... */ (1)
List<Book> result = searchSession.search( Book.class ) (2)
.where( f -> f.matchAll() )
.sort( f -> f.field( "pageCount" ).desc() (3)
.then().field( "title_sort" ) )
.fetchHits( 20 ); (4)| 1 | 检索 SearchSession. |
| 2 | 像往常一样开始构建查询。 |
| 3 | 提到查询结果预计按“pageCount”字段降序排序,然后(对于具有相同页数的那些结果)按“title_sort”字段升序排序。如果该字段不存在或无法按其排序,则会抛出异常。 |
| 4 | 获取结果,这些结果将根据说明进行排序。 |
或者,如果您不想使用 lambda
SearchSession searchSession = /* ... */
SearchScope<Book> scope = searchSession.scope( Book.class );
List<Book> result = searchSession.search( scope )
.where( scope.predicate().matchAll().toPredicate() )
.sort( scope.sort()
.field( "pageCount" ).desc()
.then().field( "title_sort" )
.toSort() )
.fetchHits( 20 );排序 DSL 提供了更多排序类型,以及每种排序类型的多种选项。要详细了解 field 排序以及所有其他类型的排序,请参阅以下部分。
15.3.2. score:按匹配得分(相关性)排序
score 按每个文档的得分进行排序。
-
降序(默认情况下),得分更高的文档将出现在命中列表中的前面。
-
升序,得分更低的文档将出现在命中列表中的前面。
对于每个查询,分数的计算方式都不同,但总的来说,您可以认为得分越高表示匹配的谓词 越多,或者匹配得越好。因此,给定文档的得分表示该文档与特定查询的相关性程度。
|
为了充分利用按得分排序,您需要通过 boosting 某些谓词来为您的谓词分配权重。 高级用户甚至可能希望通过指定不同的Similarity 来更改评分公式。 |
按得分排序是默认排序,因此通常不需要显式要求按得分排序,但以下是如何执行此操作的示例。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match().field( "title" )
.matching( "robot dawn" ) )
.sort( f -> f.score() )
.fetchHits( 20 );选项
-
您可以通过更改排序顺序 按升序得分排序。但是,这意味着相关性最小的命中将出现在前面,这完全没有意义。此选项仅出于完整性考虑提供。
15.3.3. indexOrder:根据存储中文档的顺序排序
indexOrder 按内部存储中文档的位置进行排序。
这种排序不可预测,但效率最高。当性能比命中顺序更重要时,请使用它。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.indexOrder() )
.fetchHits( 20 );15.3.4. field:按字段值排序
field 按每个文档的给定字段的值进行排序。
排序顺序定义如下:
-
升序(默认情况下),值较低的文档将出现在命中列表中的前面。
-
降序,值较高的文档将出现在命中列表中的前面。
|
对于文本字段,“较低”表示“在字母顺序中较低”。 |
语法
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "title_sort" ) )
.fetchHits( 20 );选项
-
排序顺序默认情况下为升序,但可以使用
.asc()/.desc()显式控制。 -
缺失值的行为可以通过使用
.missing()显式控制。 -
多值字段的行为可以通过使用
.mode(…)显式控制。 -
对于嵌套对象中的字段,默认情况下将考虑所有嵌套对象,但这可以通过使用
.filter(…)显式控制。
15.3.5. distance:按到点的距离排序
distance 按从给定中心到每个文档的给定字段的地理点值的距离进行排序。
-
升序(默认情况下),距离较低的文档将出现在命中列表中的前面。
-
降序,距离较高的文档将出现在命中列表中的前面。
先决条件
为了使 distance 排序在给定字段上可用,您需要在映射中将该字段标记为可排序的。
语法
GeoPoint center = GeoPoint.of( 47.506060, 2.473916 );
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.matchAll() )
.sort( f -> f.distance( "placeOfBirth", center ) )
.fetchHits( 20 );选项
-
排序顺序默认情况下为升序,但可以使用
.asc()/.desc()显式控制。 -
多值字段的行为可以通过使用
.mode(…)显式控制。 -
对于嵌套对象中的字段,默认情况下将考虑所有嵌套对象,但这可以通过使用
.filter(…)显式控制。
15.3.6. withParameters:使用查询参数创建排序
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
withParameters 排序允许使用查询参数 构建排序。
这种类型的排序需要一个接受查询参数并返回排序的函数。该函数将在构建查询时被调用。
GeoPoint center = GeoPoint.of( 47.506060, 2.473916 );
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.matchAll() )
.sort( f -> f.withParameters( params -> f (1)
.distance( "placeOfBirth", params.get( "center", GeoPoint.class ) ) ) ) (2)
.param( "center", center ) (3)
.fetchHits( 20 );| 1 | 开始创建 .withParameters() 排序。 |
| 2 | 在构建排序时访问 GeoPoint 类型的查询参数 center。 |
| 3 | 在查询级别设置排序所需的參數。 |
15.3.7. composite:组合排序
composite 按顺序应用多个排序。它在应用不完整排序时很有用。
composite() 按多个组合排序进行排序List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.composite() (1)
.add( f.field( "genre_sort" ) ) (2)
.add( f.field( "title_sort" ) ) ) (3)
.fetchHits( 20 ); (4)| 1 | 开始一个 composite 排序。 |
| 2 | 在 genre_sort 字段上添加一个 field 排序。由于许多书籍共享相同的类型,因此这种排序不完整:具有相同类型的书籍的相对顺序是不确定的,并且可能会在每次查询执行时发生变化。 |
| 3 | 在 title_sort 字段上添加一个 field 排序。当两本书具有相同的类型时,它们的相对顺序将通过比较它们的标题来确定。如果两本书可以具有相同的标题,我们可以在通过在 id 上添加最后一个排序来进一步稳定排序。 |
| 4 | 命中将按类型排序,然后按标题排序。 |
或者,您可以通过在第一个排序之后调用 .then() 将排序追加到另一个排序。
then() 按多个组合排序进行排序List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "genre_sort" )
.then().field( "title_sort" ) )
.fetchHits( 20 );使用 lambda 语法动态添加排序
可以在 lambda 表达式中定义 composite 排序。当内部排序需要动态添加到 composite 排序时,这尤其有用,例如,基于用户输入。
MySearchParameters searchParameters = getSearchParameters(); (1)
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.composite( b -> { (2)
for ( MySort mySort : searchParameters.getSorts() ) { (3)
switch ( mySort.getType() ) {
case GENRE:
b.add( f.field( "genre_sort" ).order( mySort.getOrder() ) );
break;
case TITLE:
b.add( f.field( "title_sort" ).order( mySort.getOrder() ) );
break;
case PAGE_COUNT:
b.add( f.field( "pageCount" ).order( mySort.getOrder() ) );
break;
}
}
} ) )
.fetchHits( 20 ); (4)| 1 | 获取一个自定义对象,该对象保存用户通过 Web 表单提供的搜索参数,例如。 |
| 2 | 调用 .composite(Consumer)。由 lambda 表达式实现的消费者将接收一个生成器作为参数,并将根据需要向该生成器添加排序。 |
| 3 | 在 lambda 中,代码可以自由地执行在添加排序之前必要的任何操作。在本例中,我们遍历用户选择的排序并相应地添加排序。 |
| 4 | 命中将根据 lambda 表达式添加的排序进行排序。 |
稳定排序
如果您的第一个排序(例如,按字段值)导致许多文档出现平局(例如,许多文档具有相同的字段值),您可能希望追加一个任意排序来稳定您的排序:确保如果执行相同的查询,搜索命中将始终按相同的顺序排列。
在大多数情况下,稳定排序的快速简便解决方案是更改您的映射,以便在您的实体 ID 上添加一个可排序字段,并将按 id 的 field 排序追加到您的不稳定排序
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "genre_sort" ).then().field( "id_sort" ) )
.fetchHits( 20 );15.3.8. 后端特定扩展
通过在构建查询时调用 .extension(…),可以访问后端特定的排序。
|
顾名思义,后端特定排序无法从一种后端技术移植到另一种后端技术。 |
Lucene:fromLuceneSort
.fromLuceneSort(…) 将本机 Lucene Sort 转换为 Hibernate Search 排序。
|
此功能意味着应用程序代码直接依赖 Lucene API。 即使是针对错误修复(微型)版本的 Hibernate Search 升级也可能需要升级 Lucene,这可能会导致 Lucene 的 API 发生重大更改。 如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
org.apache.lucene.search.Sort 排序List<Book> hits = searchSession.search( Book.class )
.extension( LuceneExtension.get() )
.where( f -> f.matchAll() )
.sort( f -> f.fromLuceneSort(
new Sort(
new SortedSetSortField( "genre_sort", false ),
new SortedSetSortField( "title_sort", false )
)
) )
.fetchHits( 20 ); Lucene: fromLuceneSortField
.fromLuceneSortField(…) 将本机 Lucene SortField 转换为 Hibernate Search 排序。
|
此功能意味着应用程序代码直接依赖 Lucene API。 即使是针对错误修复(微型)版本的 Hibernate Search 升级也可能需要升级 Lucene,这可能会导致 Lucene 的 API 发生重大更改。 如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
org.apache.lucene.search.SortField 排序List<Book> hits = searchSession.search( Book.class )
.extension( LuceneExtension.get() )
.where( f -> f.matchAll() )
.sort( f -> f.fromLuceneSortField(
new SortedSetSortField( "title_sort", false )
) )
.fetchHits( 20 );Elasticsearch: fromJson
.fromJson(…) 将表示 Elasticsearch 排序的 JSON 转换为 Hibernate Search 排序。
|
此功能要求直接在应用程序代码中操作 JSON。 此 JSON 的语法可能会发生更改
如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
JsonObject 形式的本机 Elasticsearch JSON 排序排序JsonObject jsonObject =
/* ... */;
List<Book> hits = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() )
.where( f -> f.matchAll() )
.sort( f -> f.fromJson( jsonObject ) )
.fetchHits( 20 );List<Book> hits = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() )
.where( f -> f.matchAll() )
.sort( f -> f.fromJson( "{"
+ " \"title_sort\": \"asc\""
+ "}" ) )
.fetchHits( 20 );15.3.9. 多种排序类型共有的选项
排序顺序
大多数排序默认情况下使用升序,得分排序是一个值得注意的例外。
通过以下选项显式控制顺序
-
.asc()用于升序。 -
.desc()用于降序。 -
.order(…)用于由给定参数定义的顺序:SortOrder.ASC/SortOrder.DESC。
以下是使用 字段排序的一些示例。
asc() 按字段值以显式升序排序List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "title_sort" ).asc() )
.fetchHits( 20 );desc() 按字段值以显式降序排序List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "title_sort" ).desc() )
.fetchHits( 20 );order(…) 按字段值以显式降序排序List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "title_sort" ).order( SortOrder.DESC ) )
.fetchHits( 20 );缺失值
默认情况下
可以使用 .missing() 选项显式控制缺失值的处理方式
-
.missing().first()将没有值的文档放在第一位置(与排序顺序无关)。 -
.missing().last()将没有值的文档放在最后位置(与排序顺序无关)。 -
.missing().lowest()将缺失值解释为最小值:在使用升序时将没有值的文档放在第一位置,在使用降序时将没有值的文档放在最后位置。 -
.missing().highest()将缺失值解释为最大值:在使用升序时将没有值的文档放在最后位置,在使用降序时将没有值的文档放在第一位置。 -
.missing().use(…)使用给定值作为没有值的文档的默认值。
|
所有这些选项都适用于使用 Lucene 后端的按字段值排序和按距离到某点排序。 当使用 Elasticsearch 后端按距离到某点排序时,由于 Elasticsearch API 的限制,仅支持以下组合
|
以下是使用 字段排序的一些示例。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "pageCount" ).missing().first() )
.fetchHits( 20 );List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "pageCount" ).missing().last() )
.fetchHits( 20 );List<Book> hits = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "pageCount" ).missing().use( 300 ) )
.fetchHits( 20 );参数的预期类型
默认情况下,.use(…) 期望其参数与目标字段对应的实体属性具有相同的类型。
例如,如果实体属性的类型为 java.util.Date,相应的字段可能为 java.time.Instant 类型。无论如何,.use(…) 都期望其参数为 java.util.Date 类型。
这通常是你想要的,但如果你需要绕过转换并将未转换的参数(在上面的示例中为 java.time.Instant 类型)传递给 .use(…),请参见 传递给 DSL 的参数类型。
多值字段的排序模式
对于排序字段有多个值的文档,也可以进行排序。为了将每个文档与其他文档进行比较,每个文档都会选择一个值。选择值的方式称为 **排序模式**,使用 .mode(…) 选项指定。以下排序模式可用
模式 |
描述 |
支持的值类型 |
不支持的值类型 |
|
对于字段排序,选择最小值;对于距离排序,选择最小距离。 这是升序的默认值。 |
所有。 |
- |
|
对于字段排序,选择最大值;对于距离排序,选择最大距离。 这是降序的默认值。 |
所有。 |
- |
|
计算每个文档的所有值的总和,并选择该总和与其他文档进行比较。 |
数字字段 ( |
文本和时间字段 ( |
|
计算每个文档的所有值的 算术平均值,并选择该平均值与其他文档进行比较。 |
数字和时间字段 ( |
文本字段 ( |
|
计算每个文档的所有值的 中位数,并选择该中位数与其他文档进行比较。 |
数字和时间字段 ( |
文本字段 ( |
以下是使用 字段排序的示例。
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "books.pageCount" ).mode( SortMode.AVG ) )
.fetchHits( 20 );嵌套对象中字段的过滤器
可以使用 filter(…) 方法之一筛选将被考虑用于排序的嵌套文档及其值。
以下是使用 字段排序的示例:作者按其书籍的平均页数排序,但只考虑“犯罪小说”类型的书籍
List<Author> hits = searchSession.search( Author.class )
.where( f -> f.matchAll() )
.sort( f -> f.field( "books.pageCount" )
.mode( SortMode.AVG )
.filter( pf -> pf.match().field( "books.genre" )
.matching( Genre.CRIME_FICTION ) ) )
.fetchHits( 20 );15.4. 投影 DSL
15.4.1. 基础知识
对于某些用例,你只需要查询返回域对象中包含的数据的一个小子集。在这些情况下,返回托管实体并从这些实体中提取数据可能过于繁琐:直接从索引中提取数据将避免数据库往返。
投影正是这样做的:它们允许查询返回比“匹配实体”更精确的结果。在构建搜索查询时可以配置投影
SearchSession searchSession = /* ... */ (1)
List<String> result = searchSession.search( Book.class ) (2)
.select( f -> f.field( "title", String.class ) ) (3)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (4)| 1 | 检索 SearchSession. |
| 2 | 像往常一样开始构建查询。 |
| 3 | 提及其期望的查询结果是字段“title”上的投影,类型为 String。如果该类型不合适或该字段不存在,则将抛出异常。 |
| 4 | 获取结果,其类型将如预期。 |
或者,如果您不想使用 lambda
SearchSession searchSession = /* ... */
SearchScope<Book> scope = searchSession.scope( Book.class );
List<String> result = searchSession.search( scope )
.select( scope.projection().field( "title", String.class )
.toProjection() )
.where( scope.predicate().matchAll().toPredicate() )
.fetchHits( 20 );|
为了使用基于给定字段值的投影,你需要在映射中将该字段标记为 可投影。 这在 Elasticsearch 后端 中是可选的,在 Elasticsearch 后端中,默认情况下所有字段都是可投影的。 |
虽然 field 投影无疑是最常见的,但它们并不是唯一的投影类型。其他投影允许 组合包含提取数据的自定义 bean,获取对 提取文档 或 对应实体 的引用,或获取与搜索查询本身相关的信息 (得分 等)。
15.4.2. 投影到自定义(带注解的)类型
对于更复杂的投影,可以 定义自定义(带注解的)记录或类,并让 Hibernate Search 从自定义类型的构造函数参数推断出相应的投影。
|
在注释自定义投影类型时,需要牢记以下几点约束
|
@ProjectionConstructor (1)
public record MyBookProjection(
@IdProjection Integer id, (2)
String title, (3)
List<MyBookProjection.Author> authors) { (4)
@ProjectionConstructor (5)
public record Author(String firstName, String lastName) {
}
}| 1 | 在记录类型上使用 `@ProjectionConstructor` 进行注释,可以在类型级别(如果只有一个构造函数)或构造函数级别(如果有多个构造函数,请参阅 多个构造函数)。 |
| 2 | 要在实体标识符上进行投影,请使用 @IdProjection 对相关构造函数参数进行注释。大多数投影都有一个相应的注释,可以在构造函数参数上使用。 |
| 3 | 要在值字段上进行投影,请添加一个以该字段命名的构造函数参数,其类型与该字段相同。有关如何定义构造函数参数的更多信息,请参阅 隐式内部投影推理。 或者,可以使用 |
| 4 | 要在对象字段上进行投影,请添加一个以该字段命名的构造函数参数,并使用其自己的自定义投影类型。多值投影 必须建模为 `List<…>` 或超类型。 或者,可以使用 |
| 5 | 对用于对象字段的任何自定义投影类型使用 `@ProjectionConstructor` 进行注释。 |
List<MyBookProjection> hits = searchSession.search( Book.class )
.select( MyBookProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 .select(…)。Hibernate Search 将 从自定义类型的构造函数参数推断出内部投影。 |
| 2 | 每个匹配项将是自定义投影类型的实例,并填充从索引检索到的数据。 |
|
自定义的非记录类也可以使用 `@ProjectionConstructor` 进行注释,如果您由于某种原因(例如您仍在使用 Java 13 或更低版本)而无法使用记录,这将很有用。 |
| 有关映射自定义投影类型的更多信息,请参见 将索引内容映射到自定义类型(投影构造函数)。 |
除了 .select(Class<?>) 之外,一些投影还允许使用自定义投影类型;请参见 composite 投影 和 object 投影。有关映射投影类型的更多信息,请参见 将索引内容映射到自定义类型(投影构造函数)。
15.4.3. documentReference:返回对匹配文档的引用
documentReference 投影将返回对匹配文档的引用,作为 DocumentReference 对象。
语法
List<DocumentReference> hits = searchSession.search( Book.class )
.select( f -> f.documentReference() )
.where( f -> f.matchAll() )
.fetchHits( 20 );由于它是对文档的引用,而不是实体的引用,因此 DocumentReference 仅公开低级概念,例如类型名称和文档标识符 (String)。使用 entityReference 投影来获取对实体的引用。 |
投影到自定义类型中的 @DocumentReferenceProjection
要在 投影到带注解的自定义类型 中实现 documentReference 投影,请使用 @DocumentReferenceProjection 注解
@ProjectionConstructor (1)
public record MyBookDocRefAndTitleProjection(
@DocumentReferenceProjection (2)
DocumentReference ref, (3)
String title (4)
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用 @DocumentReferenceProjection 注解应该接收文档引用的参数。 |
| 3 | 构造函数参数的类型必须可从 DocumentReference 赋值。 |
| 4 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookDocRefAndTitleProjection> hits = searchSession.search( Book.class )
.select( MyBookDocRefAndTitleProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每个命中都是自定义投影类型的一个实例,用请求的文档引用和字段填充。 |
对于 编程映射,请使用 DocumentReferenceProjectionBinder.create()。
documentReference 投影TypeMappingStep myBookDocRefAndTitleProjection =
mapping.type( MyBookDocRefAndTitleProjection.class );
myBookDocRefAndTitleProjection.mainConstructor()
.projectionConstructor();
myBookDocRefAndTitleProjection.mainConstructor().parameter( 0 )
.projection( DocumentReferenceProjectionBinder.create() );15.4.4. entityReference:返回对匹配实体的引用
entityReference 投影将返回对匹配实体的引用,作为 EntityReference 对象。
语法
List<? extends EntityReference> hits = searchSession.search( Book.class )
.select( f -> f.entityReference() )
.where( f -> f.matchAll() )
.fetchHits( 20 );实体不会作为投影的一部分被加载。如果你想要实际的实体实例,请使用 entity 投影 |
投影到自定义类型中的 @EntityReferenceProjection
要在 投影到带注解的自定义类型 中实现 entityReference 投影,请使用 @EntityReferenceProjection 注解
@ProjectionConstructor (1)
public record MyBookEntityRefAndTitleProjection(
@EntityReferenceProjection (2)
EntityReference ref, (3)
String title (4)
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@EntityReferenceProjection注释应该接收实体引用的参数。 |
| 3 | 构造函数参数的类型必须可以从EntityReference赋值。 |
| 4 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookEntityRefAndTitleProjection> hits = searchSession.search( Book.class )
.select( MyBookEntityRefAndTitleProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每次命中将是自定义投影类型的实例,填充有请求的实体引用和字段。 |
对于编程映射,请使用EntityReferenceProjectionBinder.create()。
entityReference投影进行编程映射TypeMappingStep myBookEntityRefAndTitleProjection =
mapping.type( MyBookEntityRefAndTitleProjection.class );
myBookEntityRefAndTitleProjection.mainConstructor()
.projectionConstructor();
myBookEntityRefAndTitleProjection.mainConstructor().parameter( 0 )
.projection( EntityReferenceProjectionBinder.create() );15.4.5. id: 返回匹配实体的标识符
id投影返回匹配实体的标识符。
语法
List<Integer> hits = searchSession.search( Book.class )
.select( f -> f.id( Integer.class ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );如果提供的标识符类型与目标实体类型的标识符类型不匹配,则会抛出异常。另请参阅投影值的类型。
您可以省略“标识符类型”参数,但您将获得类型为Object的投影
List<Object> hits = searchSession.search( Book.class )
.select( f -> f.id() )
.where( f -> f.matchAll() )
.fetchHits( 20 );@IdProjection 在投影到自定义类型中
要在投影到带注释的自定义类型中实现id投影,请使用@IdProjection注释
@ProjectionConstructor (1)
public record MyBookIdAndTitleProjection(
@IdProjection (2)
Integer id, (3)
String title) { (4)
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@IdProjection注释应该接收实体标识符的参数。 |
| 3 | 构造函数参数的类型必须可以从目标实体标识符的类型赋值。 |
| 4 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookIdAndTitleProjection> hits = searchSession.search( Book.class )
.select( MyBookIdAndTitleProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每次命中将是自定义投影类型的实例,填充有请求的标识符和字段。 |
对于编程映射,请使用IdProjectionBinder.create()。
id投影进行编程映射TypeMappingStep myBookIdAndTitleProjectionMapping =
mapping.type( MyBookIdAndTitleProjection.class );
myBookIdAndTitleProjectionMapping.mainConstructor()
.projectionConstructor();
myBookIdAndTitleProjectionMapping.mainConstructor().parameter( 0 )
.projection( IdProjectionBinder.create() );15.4.6. entity: 返回匹配的实体
entity投影返回与匹配文档相对应的实体。
实体的加载方式取决于您的映射器和配置
-
使用Hibernate ORM 集成,返回的对象是由 Hibernate ORM 从数据库加载的管理实体。您可以像使用从传统 Hibernate ORM 查询返回的任何实体一样使用它们。
-
使用独立 POJO 映射器,如果已配置,实体将从外部数据存储加载,或者(如果失败)从索引中投影(如果实体类型声明了投影构造函数)。如果没有找到加载配置或投影构造函数,
entity投影将简单地失败。
语法
List<Book> hits = searchSession.search( Book.class )
.select( f -> f.entity() )
.where( f -> f.matchAll() )
.fetchHits( 20 );如果无法从外部数据存储/数据库加载实体(例如,它在那里被删除,并且索引尚未更新),则命中将被省略,并且不会出现在返回的List中。但是,总命中数不会考虑此省略。 |
请求特定实体类型
在某些(罕见)情况下,创建投影的代码可能需要使用SearchProjectionFactory<?, ?>,即一个不包含有关加载实体类型的任何信息的工厂。
在这些情况下,可以请求特定类型的实体:Hibernate Search 将在创建投影时检查请求的类型是否与加载的实体的类型匹配。
entity投影请求特定实体类型f.entity( Book.class )@EntityProjection 在投影到自定义类型中
要在投影到带注释的自定义类型中实现entity投影,请使用@EntityProjection注释
@ProjectionConstructor (1)
public record MyBookEntityAndTitleProjection(
@EntityProjection (2)
Book entity, (3)
String title (4)
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@EntityProjection注释应该接收实体的参数。 |
| 3 | 构造函数参数的类型必须可以从搜索到的实体类型赋值——在针对多个索引的查询的情况下,必须可以从所有搜索到的实体类型赋值。 |
| 4 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookEntityAndTitleProjection> hits = searchSession.search( Book.class )
.select( MyBookEntityAndTitleProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每次命中将是自定义投影类型的实例,填充有请求的实体和字段。 |
对于编程映射,请使用EntityProjectionBinder.create()。
entity投影进行编程映射TypeMappingStep myBookEntityAndTitleProjection =
mapping.type( MyBookEntityAndTitleProjection.class );
myBookEntityAndTitleProjection.mainConstructor()
.projectionConstructor();
myBookEntityAndTitleProjection.mainConstructor().parameter( 0 )
.projection( EntityProjectionBinder.create() );15.4.7. field: 返回来自匹配文档的字段值
field投影返回匹配文档中给定字段的值。
|
为了使用基于给定字段值的投影,你需要在映射中将该字段标记为 可投影。 这在 Elasticsearch 后端 中是可选的,在 Elasticsearch 后端中,默认情况下所有字段都是可投影的。 |
语法
默认情况下,field投影每个文档返回单个值,因此以下代码对于单值字段就足够了
List<Genre> hits = searchSession.search( Book.class )
.select( f -> f.field( "genre", Genre.class ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );| 如果您在多值字段上执行此操作,Hibernate Search 将在构建查询时抛出异常。要投影到多值字段,请参阅多值字段。 |
您可以省略“字段类型”参数,但您将获得类型为Object的投影
List<Object> hits = searchSession.search( Book.class )
.select( f -> f.field( "genre" ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );多值字段
要返回多个值,从而允许投影到多值字段,请使用.multi()。这将改变投影的返回类型为List<T>,其中T是单值投影将返回的内容。
List<List<String>> hits = searchSession.search( Book.class )
.select( f -> f.field( "authors.lastName", String.class ).multi() )
.where( f -> f.matchAll() )
.fetchHits( 20 );跳过转换
默认情况下,field投影返回的值具有与对应于目标字段的实体属性相同的类型。
例如,如果实体属性是枚举类型,相应的字段可能是类型为String;field投影返回的值将是枚举类型,无论如何。
这通常应该是您想要的,但是如果您需要绕过转换并将未转换的值返回给您(在上面的示例中为类型String),则可以按以下方式进行
List<String> hits = searchSession.search( Book.class )
.select( f -> f.field( "genre", String.class, ValueModel.INDEX ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );有关更多信息,请参阅投影值的类型。
@FieldProjection 在投影到自定义类型中
要在投影到带注释的自定义类型中实现field投影,您可以依赖于默认的推断投影:当构造函数参数上没有注释时,它将推断为对与构造函数参数名称相同的字段的字段投影(或对象投影,有关详细信息,请参阅这里)。
要强制进行字段投影,或者进一步自定义字段投影(例如,显式设置字段路径),请在构造函数参数上使用@FieldProjection注释
@ProjectionConstructor (1)
public record MyBookTitleAndAuthorNamesProjection(
@FieldProjection (2)
String title, (3)
@FieldProjection(path = "authors.lastName") (4)
List<String> authorLastNames (5)
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@FieldProjection注释应该接收字段值的参数。 |
| 3 | 对于单值投影,构造函数参数的类型必须可以从投影字段的类型赋值。 |
| 4 | 注释属性允许自定义。 这里我们使用了一个包含点的路径,我们不可能将其包含在 Java 构造函数参数的名称中。 |
| 5 | 对于多值投影,构造函数参数的类型必须可以从List<T>赋值,其中T是投影字段的类型或其超类型。有关更多信息,请参阅内部投影和类型。 |
List<MyBookTitleAndAuthorNamesProjection> hits = searchSession.search( Book.class )
.select( MyBookTitleAndAuthorNamesProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每次命中将是自定义投影类型的实例,填充有请求的字段。 |
注释公开了以下属性
对于编程映射,请使用FieldProjectionBinder.create()。
field投影进行编程映射TypeMappingStep myBookTitleAndAuthorNamesProjectionMapping =
mapping.type( MyBookTitleAndAuthorNamesProjection.class );
myBookTitleAndAuthorNamesProjectionMapping.mainConstructor()
.projectionConstructor();
myBookTitleAndAuthorNamesProjectionMapping.mainConstructor().parameter( 0 )
.projection( FieldProjectionBinder.create() );
myBookTitleAndAuthorNamesProjectionMapping.mainConstructor().parameter( 1 )
.projection( FieldProjectionBinder.create( "authors.lastName" ) );15.4.8. score: 返回匹配文档的分数
score投影返回匹配文档的分数。
语法
List<Float> hits = searchSession.search( Book.class )
.select( f -> f.score() )
.where( f -> f.match().field( "title" )
.matching( "robot dawn" ) )
.fetchHits( 20 );|
只有在同一个查询执行过程中计算出的两个分数才能可靠地进行比较。尝试比较来自两个单独查询执行的分数只会导致令人困惑的结果,特别是如果谓词不同或索引的内容已发生足够大的变化以显着改变某些术语的频率。 相关的是,将分数公开给最终用户通常不是一件容易的事。有关分数百分比错误的更多信息,请参阅这篇文章。 |
@ScoreProjection 在投影到自定义类型中
要在投影到带注释的自定义类型中实现score投影,请使用@ScoreProjection注释
@ProjectionConstructor (1)
public record MyBookScoreAndTitleProjection(
@ScoreProjection (2)
float score, (3)
String title (4)
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@ScoreProjection注释应该接收分数的参数。 |
| 3 | 构造函数参数的类型必须可以从float赋值。 |
| 4 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookScoreAndTitleProjection> hits = searchSession.search( Book.class )
.select( MyBookScoreAndTitleProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每次命中将是自定义投影类型的实例,填充有请求的分数和字段。 |
对于编程映射,请使用ScoreProjectionBinder.create()。
score投影进行编程映射TypeMappingStep myBookScoreAndTitleProjection =
mapping.type( MyBookScoreAndTitleProjection.class );
myBookScoreAndTitleProjection.mainConstructor()
.projectionConstructor();
myBookScoreAndTitleProjection.mainConstructor().parameter( 0 )
.projection( ScoreProjectionBinder.create() );15.4.9. distance: 返回到点的距离
distance投影返回给定点与匹配文档中给定字段的地理点值之间的距离。
|
为了使用基于给定字段值的投影,你需要在映射中将该字段标记为 可投影。 这在 Elasticsearch 后端 中是可选的,在 Elasticsearch 后端中,默认情况下所有字段都是可投影的。 |
语法
默认情况下,distance投影每个文档返回单个值,因此以下代码对于单值字段就足够了
GeoPoint center = GeoPoint.of( 47.506060, 2.473916 );
SearchResult<Double> result = searchSession.search( Author.class )
.select( f -> f.distance( "placeOfBirth", center ) )
.where( f -> f.matchAll() )
.fetch( 20 );| 如果您在多值字段上执行此操作,Hibernate Search 将在构建查询时抛出异常。要投影到多值字段,请参阅多值字段。 |
返回的距离默认以米为单位,但您可以选择不同的单位
GeoPoint center = GeoPoint.of( 47.506060, 2.473916 );
SearchResult<Double> result = searchSession.search( Author.class )
.select( f -> f.distance( "placeOfBirth", center )
.unit( DistanceUnit.KILOMETERS ) )
.where( f -> f.matchAll() )
.fetch( 20 );多值字段
要返回多个值,从而允许在多值字段上进行投影,请使用 .multi()。这将把投影的返回类型更改为 List<Double>。
GeoPoint center = GeoPoint.of( 47.506060, 2.473916 );
SearchResult<List<Double>> result = searchSession.search( Book.class )
.select( f -> f.distance( "authors.placeOfBirth", center ).multi() )
.where( f -> f.matchAll() )
.fetch( 20 );@DistanceProjection 在投影到自定义类型时
要在 投影到带注释的自定义类型 中实现 distance 投影,请在构造函数参数上使用 @DistanceProjection 注释
@ProjectionConstructor (1)
public record MyAuthorPlaceProjection(
@DistanceProjection( (2)
fromParam = "point-param", (3)
path = "placeOfBirth") (4)
Double distance ) { (5)
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 用 @DistanceProjection 注释应该接收距离值的参数。 |
| 3 | 指定将用于计算距离的 查询参数。 |
| 4 | 可选地,自定义路径,因为实体的 GeoPoint 属性很可能与投影中的距离属性具有不同的名称。 |
| 5 | 对于单值投影,构造函数参数的类型必须可以从 Double 赋值。对于多值投影,构造函数参数的类型必须可以从 |
List<MyAuthorPlaceProjection> hits = searchSession.search( Author.class )
.select( MyAuthorPlaceProjection.class )(1)
.where( f -> f.matchAll() )
.param( "point-param", GeoPoint.of( latitude, longitude ) ) (2)
.fetchHits( 20 ); (3)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 传递一个查询参数值,其名称与投影构造函数的 @DistanceProjection fromParam 中的 point-param 相同。 |
| 3 | 每次命中将是自定义投影类型的实例,填充有请求的字段。 |
注释公开了以下属性
对于 编程映射,请使用 DistanceProjectionBinder.create(..)。
distance 投影TypeMappingStep myAuthorPlaceProjection =
mapping.type( MyAuthorPlaceProjection.class );
myAuthorPlaceProjection.mainConstructor()
.projectionConstructor();
myAuthorPlaceProjection.mainConstructor().parameter( 0 )
.projection( DistanceProjectionBinder.create( "placeOfBirth", "point-param" ) );15.4.10. composite:组合投影
基本
composite 投影应用多个投影并组合其结果,作为 List<?> 或使用自定义转换器生成的单个对象。
为了保持类型安全,您可以提供自定义转换器。转换器可以是 Function、BiFunction 或 org.hibernate.search.util.common.function.TriFunction,具体取决于内部投影的数量。它将接收内部投影返回的值,并返回一个组合这些值的オブジェクト。
.composite().from(…).as(…) 从多个投影值创建的自定义对象List<MyPair<String, Genre>> hits = searchSession.search( Book.class )
.select( f -> f.composite() (1)
.from( f.field( "title", String.class ), (2)
f.field( "genre", Genre.class ) ) (3)
.as( MyPair::new ) )(4)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (5)| 1 | 调用 .composite()。 |
| 2 | 将第一个内部投影定义为对 title 字段的投影。 |
| 3 | 将第二个内部投影定义为对 genre 字段的投影。 |
| 4 | 将复合投影的结果定义为调用自定义对象 MyPair 的构造函数的结果。MyPair 的构造函数将针对每个匹配的文档调用,其中 title 字段的值作为其第一个参数,genre 字段的值作为其第二个参数。 |
| 5 | 每个命中都是 MyPair 的一个实例。因此,命中的列表将是 List<MyPair> 的一个实例。 |
组合 3 个以上内部投影
|
对于复杂的投影,请考虑 投影到自定义(带注释的)类型。 |
如果将 3 个以上投影作为参数传递给 from(…),则转换函数将必须将 List<?> 作为参数,并将使用 asList(…) 而不是 as(..,) 设置
.composite().from(…).asList(…) 从多个投影值创建的自定义对象List<MyTuple4<String, Genre, Integer, String>> hits = searchSession.search( Book.class )
.select( f -> f.composite() (1)
.from( f.field( "title", String.class ), (2)
f.field( "genre", Genre.class ), (3)
f.field( "pageCount", Integer.class ), (4)
f.field( "description", String.class ) ) (5)
.asList( list -> (6)
new MyTuple4<>( (String) list.get( 0 ), (Genre) list.get( 1 ),
(Integer) list.get( 2 ), (String) list.get( 3 ) ) ) )
.where( f -> f.matchAll() )
.fetchHits( 20 ); (7)| 1 | 调用 .composite()。 |
| 2 | 将第一个内部投影定义为对 title 字段的投影。 |
| 3 | 将第二个内部投影定义为对 genre 字段的投影。 |
| 4 | 将第三个内部投影定义为对 pageCount 字段的投影。 |
| 5 | 将第四个内部投影定义为对 description 字段的投影。 |
| 6 | 将对象的投影结果定义为调用 lambda 的结果。lambda 将获取列表中的元素(上面定义的投影的结果,按顺序),将它们强制转换为相应的类型,并将它们传递给自定义类 MyTuple4 的构造函数。 |
| 7 | 每个命中都是 MyTuple4 的一个实例。因此,命中的列表将是 List<MyTuple4> 的一个实例。 |
投影到 List<?> 或 Object[]
如果您不介意将内部投影的结果作为 List<?> 接收,则可以通过调用 asList() 来省略转换器
.composite().add(…).asList() 返回投影值的 ListList<List<?>> hits = searchSession.search( Book.class )
.select( f -> f.composite() (1)
.from( f.field( "title", String.class ), (2)
f.field( "genre", Genre.class ) ) (3)
.asList() ) (4)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (5)| 1 | 调用 .composite()。 |
| 2 | 将第一个内部投影定义为对 title 字段的投影。 |
| 3 | 将第二个内部投影定义为对 genre 字段的投影。 |
| 4 | 将投影的结果定义为列表,这意味着命中将是 List 实例,其中匹配文档的 title 字段的值位于索引 0 处,匹配文档的 genre 字段的值位于索引 1 处。 |
| 5 | 每个命中都是 List<?> 的一个实例:一个列表,其中包含内部投影的结果,按给定的顺序排列。因此,命中的列表将是 List<List<?>> 的一个实例。 |
类似地,要将内部投影的结果作为数组(Object[])获取,可以通过调用 asArray() 来省略转换器
.composite(…).add(…).asArray() 返回投影值的数组List<Object[]> hits = searchSession.search( Book.class )
.select( f -> f.composite() (1)
.from( f.field( "title", String.class ), (2)
f.field( "genre", Genre.class ) ) (3)
.asArray() ) (4)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (5)| 1 | 调用 .composite()。 |
| 2 | 将第一个内部投影定义为对 title 字段的投影。 |
| 3 | 将第二个内部投影定义为对 genre 字段的投影。 |
| 4 | 将投影的结果定义为数组,这意味着命中将是 Object[] 实例,其中匹配文档的 title 字段的值位于索引 0 处,匹配文档的 genre 字段的值位于索引 1 处。 |
| 5 | 每个命中都是 Object[] 的一个实例:一个对象数组,其中包含内部投影的结果,按给定的顺序排列。因此,命中的列表将是 List<Object[]> 的一个实例。 |
或者,要将结果作为 List<?> 获取,您可以使用 .composite(…) 的较短变体,它直接将投影作为参数
.composite(…) 返回投影值的 ListList<List<?>> hits = searchSession.search( Book.class )
.select( f -> f.composite( (1)
f.field( "title", String.class ), (2)
f.field( "genre", Genre.class ) (3)
) )
.where( f -> f.matchAll() )
.fetchHits( 20 ); (4)| 1 | 调用 .composite(…)。 |
| 2 | 将第一个要组合的投影定义为对 title 字段的投影。 |
| 3 | 将第二个要组合的投影定义为对 genre 字段的投影。 |
| 4 | 每个命中都是 List<?> 的一个实例:一个列表,其中包含内部投影的结果,按给定的顺序排列。因此,命中的列表将是 List<List<?>> 的一个实例。 |
投影到自定义(带注释的)类型
对于更复杂的复合投影,可以定义一个自定义(带注释的)记录或类,并让 Hibernate Search 从自定义类型的构造函数参数推断相应的内部投影。这类似于 通过 .select(…) 投影到自定义(带注释的)类型。
|
在注释自定义投影类型时,需要牢记以下几点约束
|
@ProjectionConstructor (1)
public record MyBookProjection(
@IdProjection Integer id, (2)
String title, (3)
List<MyBookProjection.Author> authors) { (4)
@ProjectionConstructor (5)
public record Author(String firstName, String lastName) {
}
}| 1 | 在记录类型上使用 `@ProjectionConstructor` 进行注释,可以在类型级别(如果只有一个构造函数)或构造函数级别(如果有多个构造函数,请参阅 多个构造函数)。 |
| 2 | 要在实体标识符上进行投影,请使用 @IdProjection 对相关构造函数参数进行注释。大多数投影都有一个相应的注释,可以在构造函数参数上使用。 |
| 3 | 要在值字段上进行投影,请添加一个以该字段命名的构造函数参数,其类型与该字段相同。有关如何定义构造函数参数的更多信息,请参阅 隐式内部投影推理。 或者,可以使用 |
| 4 | 要在对象字段上进行投影,请添加一个以该字段命名的构造函数参数,并使用其自己的自定义投影类型。多值投影 必须建模为 `List<…>` 或超类型。 或者,可以使用 |
| 5 | 对用于对象字段的任何自定义投影类型使用 `@ProjectionConstructor` 进行注释。 |
List<MyBookProjection> hits = searchSession.search( Book.class )
.select( f -> f.composite() (1)
.as( MyBookProjection.class ) )(2)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (3)| 1 | 调用 .composite()。 |
| 2 | 将投影的结果定义为自定义(带注释的)类型。Hibernate Search 将 从自定义类型的构造函数参数推断内部投影。 |
| 3 | 每个匹配项将是自定义投影类型的实例,并填充从索引检索到的数据。 |
|
自定义的非记录类也可以使用 `@ProjectionConstructor` 进行注释,如果您由于某种原因(例如您仍在使用 Java 13 或更低版本)而无法使用记录,这将很有用。 |
| 有关映射自定义投影类型的更多信息,请参见 将索引内容映射到自定义类型(投影构造函数)。 |
@CompositeProjection 在投影到自定义类型时
要在 投影到带注释的自定义类型 中实现 composite 投影,请在构造函数参数上使用 @CompositeProjection 注释
@ProjectionConstructor (1)
public record MyBookMiscInfoAndTitleProjection(
@CompositeProjection (2)
MiscInfo miscInfo, (3)
String title (4)
) {
@ProjectionConstructor (3)
public record MiscInfo(
Genre genre,
Integer pageCount
) {
}
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 用 @CompositeProjection 注释应该接收复合投影的参数。 |
| 3 | 构造函数参数的类型本身必须具有投影构造函数。有关详细信息,请参阅 内部投影和类型。 |
| 4 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookMiscInfoAndTitleProjection> hits = searchSession.search( Book.class )
.select( MyBookMiscInfoAndTitleProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每个命中都是自定义投影类型的实例,用请求的复合投影填充。 |
对于 编程映射,请使用 CompositeProjectionBinder.create()。
composite 投影TypeMappingStep myBookMiscInfoAndTitleProjection =
mapping.type( MyBookMiscInfoAndTitleProjection.class );
myBookMiscInfoAndTitleProjection.mainConstructor()
.projectionConstructor();
myBookMiscInfoAndTitleProjection.mainConstructor().parameter( 0 )
.projection( CompositeProjectionBinder.create() );
TypeMappingStep miscInfoProjection =
mapping.type( MyBookMiscInfoAndTitleProjection.MiscInfo.class );
miscInfoProjection.mainConstructor().projectionConstructor();已弃用的变体
|
本节中详细介绍的功能已 *弃用*:应该避免使用它们,而应使用非弃用的替代方案。 通常的 兼容性策略 适用,这意味着这些功能预计至少在 Hibernate Search 的下一个主要版本之前仍然可用。除此之外,它们可能会以与以前不兼容的方式更改,甚至被删除。 不建议使用已弃用的功能。 |
.composite(…) 的一些方法在 SearchProjectionFactory 上可用,这些方法接受函数和投影列表,但它们已弃用。
composite 的已弃用变体List<MyPair<String, Genre>> hits = searchSession.search( Book.class )
.select( f -> f.composite( (1)
MyPair::new, (2)
f.field( "title", String.class ), (3)
f.field( "genre", Genre.class ) (4)
) )
.where( f -> f.matchAll() )
.fetchHits( 20 ); (5)| 1 | 调用 .composite(…)。 |
| 2 | 将转换器定义为自定义对象 MyPair 的构造函数。 |
| 3 | 将第一个要组合的投影定义为对 title 字段的投影,这意味着 MyPair 的构造函数将针对每个匹配的文档调用,其中 title 字段的值作为其第一个参数。 |
| 4 | 将第二个要组合的投影定义为对 genre 字段的投影,这意味着 MyPair 的构造函数将针对每个匹配的文档调用,其中 genre 字段的值作为其第二个参数。 |
| 5 | 每个命中都是 MyPair 的一个实例。因此,命中的列表将是 List<MyPair> 的一个实例。 |
15.4.11. object:为对象字段中的每个对象返回一个值
object 投影针对给定对象字段中的每个对象生成一个投影值,该值是通过应用多个内部投影并组合其结果生成的,作为 List<?> 或使用自定义转换器生成的单个对象。
|
但是,存在两个关键区别
|
|
对于 Lucene 后端,对象投影有一些限制 这些限制不适用于 Elasticsearch 后端。 |
语法
为了保持类型安全,您可以提供自定义转换器。转换器可以是 Function、BiFunction 或 org.hibernate.search.util.common.function.TriFunction,具体取决于内部投影的数量。它将接收内部投影返回的值,并返回一个组合这些值的オブジェクト。
.object(…).from(…).as(…) 从对象字段创建的自定义对象List<List<MyAuthorName>> hits = searchSession.search( Book.class )
.select( f -> f.object( "authors" ) (1)
.from( f.field( "authors.firstName", String.class ), (2)
f.field( "authors.lastName", String.class ) ) (3)
.as( MyAuthorName::new ) (4)
.multi() ) (5)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (6)| 1 | 调用 .object( "authors" )。 |
| 2 | 将第一个内部投影定义为对 authors 的 firstName 字段的投影。 |
| 3 | 将第二个内部投影定义为对 authors 的 lastName 字段的投影。 |
| 4 | 将对象的投影结果定义为调用自定义对象 MyAuthorName 的构造函数的结果。MyAuthorName 的构造函数将针对 authors 对象字段中的每个对象调用,其中 authors.firstName 字段的值作为其第一个参数,authors.lastName 字段的值作为其第二个参数。 |
| 5 | 将投影定义为多值,这意味着它将生成 List<MyAuthorName> 类型的值:authors 对象字段中的每个对象一个 MyAuthorName。 |
| 6 | 每个命中都是 List<MyAuthorName> 的一个实例。因此,命中的列表将是 List<List<MyAuthorName>> 的一个实例。 |
组合 3 个以上内部投影
|
对于复杂的投影,请考虑投影到自定义(带注释)类型。 |
如果您传递超过 3 个投影作为参数,则转换函数必须接受一个List<?>作为参数,并将使用asList(…)而不是as(..,)设置。
.object(…).from(…).asList(…)从对象字段返回创建的自定义对象GeoPoint center = GeoPoint.of( 53.970000, 32.150000 );
List<List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>> hits = searchSession
.search( Book.class )
.select( f -> f.object( "authors" ) (1)
.from( f.field( "authors.firstName", String.class ), (2)
f.field( "authors.lastName", String.class ), (3)
f.field( "authors.birthDate", LocalDate.class ), (4)
f.distance( "authors.placeOfBirth", center ) (5)
.unit( DistanceUnit.KILOMETERS ) )
.asList( list -> (6)
new MyAuthorNameAndBirthDateAndPlaceOfBirthDistance(
(String) list.get( 0 ), (String) list.get( 1 ),
(LocalDate) list.get( 2 ), (Double) list.get( 3 ) ) )
.multi() ) (7)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (8)| 1 | 调用 .object( "authors" )。 |
| 2 | 将第一个内部投影定义为对 authors 的 firstName 字段的投影。 |
| 3 | 将第二个内部投影定义为对 authors 的 lastName 字段的投影。 |
| 4 | 将第三个内部投影定义为对authors的birthDate字段的投影。 |
| 5 | 将第四个内部投影定义为对placeOfBirth字段的距离投影,并提供中心和单位。 |
| 6 | 将对象投影的结果定义为调用 lambda 的结果。lambda 将获取列表中的元素(按顺序定义的投影结果),将其强制转换为类型,并将它们传递给自定义类MyAuthorNameAndBirthDateAndPlaceOfBirthDistance的构造函数。 |
| 7 | 将投影定义为多值,这意味着它将生成类型为List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>的值:每个authors对象字段中的对象对应一个MyAuthorNameAndBirthDateAndPlaceOfBirthDistance。而不是仅仅MyAuthorNameAndBirthDateAndPlaceOfBirthDistance。 |
| 8 | 每个命中将是List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>的一个实例。因此,命中列表将是List<List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>>的一个实例。 |
类似地,asArray(…)可以用来获取传递给Object[]参数而不是List<?>。
.object(…).from(…).asArray(…)从对象字段返回创建的自定义对象GeoPoint center = GeoPoint.of( 53.970000, 32.150000 );
List<List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>> hits = searchSession
.search( Book.class )
.select( f -> f.object( "authors" ) (1)
.from( f.field( "authors.firstName", String.class ), (2)
f.field( "authors.lastName", String.class ), (3)
f.field( "authors.birthDate", LocalDate.class ), (4)
f.distance( "authors.placeOfBirth", center ) (5)
.unit( DistanceUnit.KILOMETERS ) )
.asArray( array -> (6)
new MyAuthorNameAndBirthDateAndPlaceOfBirthDistance(
(String) array[0], (String) array[1],
(LocalDate) array[2], (Double) array[3] ) )
.multi() ) (7)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (8)| 1 | 调用 .object( "authors" )。 |
| 2 | 将第一个内部投影定义为对 authors 的 firstName 字段的投影。 |
| 3 | 将第二个内部投影定义为对 authors 的 lastName 字段的投影。 |
| 4 | 将第三个内部投影定义为对authors的birthDate字段的投影。 |
| 5 | 将第四个内部投影定义为对placeOfBirth字段的距离投影,并提供中心和单位。 |
| 6 | 将对象投影的结果定义为调用 lambda 的结果。lambda 将获取数组中的元素(按顺序定义的投影结果),将其强制转换为类型,并将它们传递给自定义类MyAuthorNameAndBirthDateAndPlaceOfBirthDistance的构造函数。 |
| 7 | 将投影定义为多值,这意味着它将生成类型为List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>的值:每个authors对象字段中的对象对应一个MyAuthorNameAndBirthDateAndPlaceOfBirthDistance。而不是仅仅MyAuthorNameAndBirthDateAndPlaceOfBirthDistance。 |
| 8 | 每个命中将是List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>的一个实例。因此,命中列表将是List<List<MyAuthorNameAndBirthDateAndPlaceOfBirthDistance>>的一个实例。 |
投影到List<?>或Object[]
如果您不介意将内部投影的结果作为 List<?> 接收,则可以通过调用 asList() 来省略转换器
.object(…).add(…).asList()返回List的投影值List<List<List<?>>> hits = searchSession.search( Book.class )
.select( f -> f.object( "authors" ) (1)
.from( f.field( "authors.firstName", String.class ), (2)
f.field( "authors.lastName", String.class ) ) (3)
.asList() (4)
.multi() ) (5)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (6)| 1 | 调用 .object( "authors" )。 |
| 2 | 将第一个内部投影定义为对 authors 的 firstName 字段的投影。 |
| 3 | 将第二个内部投影定义为对 authors 的 lastName 字段的投影。 |
| 4 | 将投影的结果定义为列表,这意味着命中将是List实例,索引0处为authors的firstName字段的值,索引1处为authors的lastName字段的值。 |
| 5 | 将投影定义为多值,这意味着它将生成类型为List<List<?>>的值:每个authors对象字段对应一个List<?>。 |
| 6 | 每个命中将是List<List<?>>的一个实例:一个列表,包含每个作者一个列表,其中依次包含内部投影的结果,按给定的顺序。因此,命中列表将是List<List<List<?>>>的一个实例。 |
类似地,要将内部投影的结果作为数组(Object[])获取,可以通过调用 asArray() 来省略转换器
.object(…).add(…).asArray()返回投影值的数组List<List<Object[]>> hits = searchSession.search( Book.class )
.select( f -> f.object( "authors" ) (1)
.from( f.field( "authors.firstName", String.class ), (2)
f.field( "authors.lastName", String.class ) ) (3)
.asArray() (4)
.multi() ) (5)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (6)| 1 | 调用 .object( "authors" )。 |
| 2 | 将第一个内部投影定义为对 authors 的 firstName 字段的投影。 |
| 3 | 将第二个内部投影定义为对 authors 的 lastName 字段的投影。 |
| 4 | 将投影的结果定义为数组,这意味着命中将是Object[]实例,索引0处为authors的firstName字段的值,索引1处为authors的lastName字段的值。 |
| 5 | 将投影定义为多值,这意味着它将生成类型为List<Object[]>的值:每个authors对象字段对应一个Object[]。 |
| 6 | 每个命中将是List<Object[]>的一个实例:一个列表,包含每个作者一个数组,其中依次包含内部投影的结果,按给定的顺序。因此,命中列表将是List<List<Object[]>>的一个实例。 |
投影到自定义(带注释)类型
对于更复杂的的Object投影,可以定义一个自定义的(带注释的)记录或类,并让Hibernate Search从自定义类型的构造函数参数推断出相应的内部投影。这类似于通过.select(…)投影到自定义(带注释)类型。
|
在注释自定义投影类型时,需要牢记以下几点约束
|
@ProjectionConstructor (1)
public record MyAuthorProjection(String firstName, String lastName) { (2)
}| 1 | 在记录类型上使用 `@ProjectionConstructor` 进行注释,可以在类型级别(如果只有一个构造函数)或构造函数级别(如果有多个构造函数,请参阅 多个构造函数)。 |
| 2 | 要在值字段上进行投影,请添加一个以该字段命名的构造函数参数,其类型与该字段相同。有关如何定义构造函数参数的更多信息,请参阅 隐式内部投影推理。 或者,可以使用 大多数投影都有一个相应的注释,可以在构造函数参数上使用。 |
List<List<MyAuthorProjection>> hits = searchSession.search( Book.class )
.select( f -> f.object( "authors" ) (1)
.as( MyAuthorProjection.class ) (2)
.multi() ) (3)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (4)| 1 | 调用 .object( "authors" )。 |
| 2 | 将投影的结果定义为自定义(带注释的)类型。Hibernate Search 将 从自定义类型的构造函数参数推断内部投影。 |
| 3 | 每个匹配项将是自定义投影类型的实例,并填充从索引检索到的数据。 |
|
自定义的非记录类也可以使用 `@ProjectionConstructor` 进行注释,如果您由于某种原因(例如您仍在使用 Java 13 或更低版本)而无法使用记录,这将很有用。 |
| 有关映射自定义投影类型的更多信息,请参见 将索引内容映射到自定义类型(投影构造函数)。 |
@ObjectProjection在投影到自定义类型中
要在投影到带注释的自定义类型中实现object投影,可以依赖于默认的推断投影:当构造函数参数上没有注释时,它将被推断为对与构造函数参数名称相同的字段的Object投影(或字段投影,有关详细信息请参阅此处)。
要强制进行对象投影,或进一步自定义对象投影(例如显式设置字段路径),请在构造函数参数上使用@ObjectProjection注释。
@ProjectionConstructor (1)
public record MyBookTitleAndAuthorsProjection(
@ObjectProjection (2)
List<MyAuthorProjection> authors, (3)
@ObjectProjection(path = "mainAuthor") (4)
MyAuthorProjection theMainAuthor, (5)
String title (6)
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@ObjectProjection注释应该接收对象的参数。 |
| 3 | 对于多值投影,构造函数参数的类型必须可从List<T>赋值,其中T是具有投影构造函数本身的类型。有关更多信息,请参阅内部投影和类型。 |
| 4 | 注释属性允许自定义。 这里我们使用与Java构造函数参数名称不同的路径。 |
| 5 | 对于单值投影,构造函数参数的类型必须具有投影构造函数本身。有关更多信息,请参阅内部投影和类型。 |
| 6 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookTitleAndAuthorsProjection> hits = searchSession.search( Book.class )
.select( MyBookTitleAndAuthorsProjection.class )(1)
.where( f -> f.matchAll() )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每个命中将是自定义投影类型的实例,包含请求的对象。 |
注释公开了以下属性
path-
如果未设置,则从构造函数参数名称推断。
如果构造函数参数名称未包含在 Java 字节码中,则字段路径推断将失败。
includePathsexcludePathsincludeDepth
对于程序化映射,请使用ObjectProjectionBinder.create()。
object投影进行程序化映射TypeMappingStep myBookTitleAndAuthorsProjection =
mapping.type( MyBookTitleAndAuthorsProjection.class );
myBookTitleAndAuthorsProjection.mainConstructor()
.projectionConstructor();
myBookTitleAndAuthorsProjection.mainConstructor().parameter( 0 )
.projection( ObjectProjectionBinder.create() );
myBookTitleAndAuthorsProjection.mainConstructor().parameter( 1 )
.projection( ObjectProjectionBinder.create( "mainAuthor" ) );@ObjectProjection过滤器,用于排除嵌套投影并打破@ObjectProjection循环
默认情况下,@ObjectProjection和推断对象投影将包括在投影类型的投影构造函数中遇到的所有投影,递归进行。
这对于更简单的用例来说效果很好,但可能会导致更复杂模型出现问题
-
如果投影类型的投影构造函数声明了许多嵌套投影,其中只有部分对“周围”类型真正有用,那么额外的投影将不必要地降低搜索性能。
-
如果有
@ObjectProjection的循环(例如,A包含类型为B的嵌套对象投影b,其中包含类型为A的嵌套投影a),那么根投影类型最终将拥有无限数量的字段(a.b.someField、a.b.a.b.someField、a.b.a.b.a.b.someField,…),Hibernate Search将检测到这一点,并抛出异常。
为了解决这些问题,可以对过滤器应用筛选条件,只包含真正有用的嵌套投影。在运行时,对排除字段的投影将将其值设置为null,或者对于多值投影,将值设置为空列表。
@ObjectProjection上的可用筛选属性为
includePaths-
要包含的嵌套索引字段的路径,即为这些字段实际从索引中检索到相应的嵌套投影。
提供的路径必须相对于投影对象字段,即它们不能包含其路径。
这优先于
includeDepth(见下文)。不能与同一个
@ObjectProjection中的excludePaths组合使用。 excludePaths-
索引嵌入元素中不应嵌入的索引字段的路径。
提供的路径必须相对于投影对象字段,即它们不能包含其路径。
这优先于
includeDepth(见下文)。不能与同一个
@ObjectProjection中的includePaths组合使用。 includeDepth-
默认情况下将包含所有字段的索引嵌入级别数。
includeDepth是默认情况下将包含其所有嵌套字段/对象投影并实际从索引中检索的Object投影级别数。在该深度及以下,对象投影将与其嵌套的(非对象)字段投影一起包含,即使这些字段没有通过
includePaths显式包含,除非这些字段通过excludePaths显式排除。-
includeDepth=0表示此对象投影的字段不包含,嵌套索引嵌入元素的任何字段也不包含,除非这些字段通过includePaths显式包含。 -
includeDepth=1表示此对象投影的字段包含,除非这些字段通过excludePaths显式排除,但不包含嵌套对象投影的字段(此@ObjectProjection中的@ObjectProjection),除非这些字段通过includePaths显式包含。 -
includeDepth=2表示此对象投影的字段和直接嵌套对象投影的字段(此@ObjectProjection中的@ObjectProjection)包含,除非这些字段通过excludePaths显式排除,但不包含更深嵌套对象投影的字段(此@ObjectProjection中的@ObjectProjection中的@ObjectProjection),除非这些字段通过includePaths显式包含。 -
以此类推。
默认值取决于
includePaths属性的值-
如果
includePaths为空,则includeDepth默认为无穷大(包含所有级别上的所有字段)。 -
如果
includePaths不为空,则includeDepth默认为0(仅包含显式包含的字段)。
-
|
在不同嵌套级别混合使用
includePaths 和 excludePaths一般来说,可以在不同级别的嵌套 |
以下是三个示例:一个利用 includePaths,一个利用 excludePaths,一个利用 includePaths 和 includeDepth。
所有三个示例都基于以下映射实体,它们依赖于@IndexedEmbedded以及它提供的非常相似的过滤器
@Entity
@Indexed
public class Human {
@Id
private Integer id;
@FullTextField(analyzer = "name", projectable = Projectable.YES)
private String name;
@FullTextField(analyzer = "name", projectable = Projectable.YES)
private String nickname;
@ManyToMany
@IndexedEmbedded(includeDepth = 5, structure = ObjectStructure.NESTED)
private List<Human> parents = new ArrayList<>();
@ManyToMany(mappedBy = "parents")
private List<Human> children = new ArrayList<>();
public Human() {
}
// Getters and setters
// ...
}includePaths筛选嵌套投影此投影将包含以下字段
-
name -
nickname -
parents.name:显式包含,因为parents上的includePaths包含name。 -
parents.nickname:显式包含,因为parents上的includePaths包含nickname。 -
parents.parents.name:显式包含,因为parents上的includePaths包含parents.name。
以下字段将被特别排除
-
parents.parents.nickname:不隐式包含,因为includeDepth未设置,默认值为0,并且不显式包含,因为parents上的includePaths不包含parents.nickname。 -
parents.parents.parents.name:不隐式包含,因为includeDepth未设置,默认值为0,并且不显式包含,因为parents上的includePaths不包含parents.parents.name。
@ProjectionConstructor
public record HumanProjection(
@FieldProjection
String name,
@FieldProjection
String nickname,
@ObjectProjection(includePaths = { "name", "nickname", "parents.name" })
List<HumanProjection> parents
) {
}excludePaths筛选嵌套投影此投影将包含与includePaths示例中相同的字段,但使用的是excludePaths。
此投影将包含以下字段
-
name -
nickname -
parents.name:因为parents上的includeDepth默认为无穷大,所以被隐式包含。 -
parents.nickname:因为parents上的includeDepth默认为无穷大,所以被隐式包含。 -
parents.parents.name:因为parents上的includeDepth默认为无穷大,所以被隐式包含。
以下字段将被特别排除
-
parents.parents.nickname:不包含,因为excludePaths显式排除parents.nickname。 -
parents.parents.parents/parents.parents.parents.<any-field>:不包含,因为excludePaths显式排除parents.parents,从而阻止任何进一步的遍历。
@ProjectionConstructor
public record HumanProjection(
@FieldProjection
String name,
@FieldProjection
String nickname,
@ObjectProjection(excludePaths = { "parents.nickname", "parents.parents" })
List<HumanProjection> parents
) {
}includePaths和includeDepth筛选嵌套投影此投影将包含以下字段
-
name -
surname -
parents.name:隐式包含在深度0,因为includeDepth > 0(因此parents.*隐式包含)。 -
parents.nickname:隐式包含在深度0,因为includeDepth > 0(因此parents.*隐式包含)。 -
parents.parents.name:隐式包含在深度1,因为includeDepth > 1(因此parents.parents.*隐式包含)。 -
parents.parents.nickname:隐式包含在深度1,因为includeDepth > 1(因此parents.parents.*隐式包含)。 -
parents.parents.parents.name:不隐式包含在深度2,因为includeDepth = 2(因此parents.parents.parents隐式包含,但子字段只能显式包含),但显式包含,因为parents上的includePaths包含parents.parents.name。
以下字段将被特别排除
-
parents.parents.parents.nickname:不隐式包含在深度2,因为includeDepth = 2(因此parents.parents.parents隐式包含,但子字段必须显式包含),并且不显式包含,因为parents上的includePaths不包含parents.parents.nickname。 -
parents.parents.parents.parents.name:不隐式包含在深度3,因为includeDepth = 2(因此parents.parents.parents隐式包含,但parents.parents.parents.parents和子字段只能显式包含),并且不显式包含,因为parents上的includePaths不包含parents.parents.parents.name。
@ProjectionConstructor
public record HumanProjection(
@FieldProjection
String name,
@FieldProjection
String nickname,
@ObjectProjection(includeDepth = 2, includePaths = { "parents.parents.name" })
List<HumanProjection> parents
) {
}15.4.12. constant:返回提供的常量
constant投影对每个文档都返回相同的值,该值是在定义投影时提供的。
这仅在某些边缘情况下有用,即希望在每个命中的表示中包含一些更广泛的上下文。在这种情况下,constant值很可能与composite投影或object投影一起使用。
语法
Instant searchRequestTimestamp = Instant.now();
List<MyPair<Integer, Instant>> hits = searchSession.search( Book.class )
.select( f -> f.composite()
.from( f.id( Integer.class ), f.constant( searchRequestTimestamp ) )
.as( MyPair::new ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );15.4.13. highlight:从匹配的文档中返回突出显示的字段值
highlight投影返回匹配文档的全文字段中的片段,这些片段导致了查询匹配。
|
为了使用给定字段的突出显示投影,您需要在映射中提供该字段支持的突出显示器列表。 可突出显示的默认值可能已在某些情况下启用突出显示支持。有关更多详细信息,请参阅 |
语法
默认情况下,highlight 投影会为每个突出显示的字段返回一个字符串值列表,无论该字段是单值还是多值字段,因为字段值中可能包含多个突出显示的词语,并且根据突出显示器配置,这可能导致多个包含突出显示词语的文本片段。
List<List<String>> hits = searchSession.search( Book.class )
.select( f -> f.highlight( "title" ) )
.where( f -> f.match().field( "title" ).matching( "detective" ) )
.fetchHits( 20 );例如,结果可能如下所示:
[
["The Automatic <em>Detective</em>"], (1)
["Dirk Gently's Holistic <em>Detective</em> Agency"], (2)
[
"The Paris <em>Detective</em>",
"<em>Detective</em> Luc Moncrief series"
], (3)
]| 1 | 第一个命中。 |
| 2 | 第二个命中。 |
| 3 | 包含多个突出显示片段的第三个命中。 |
在某些情况下,当我们知道只会返回一个突出显示片段时,强制突出显示投影生成单个String而不是List<String可能会有帮助。这只有在片段数量显式设置为1时才可能。
List<String> hits = searchSession.search( Book.class )
.select( f -> f.highlight( "title" ).single() ) (1)
.where( f -> f.match().field( "title" ).matching( "detective" ) )
.highlighter( f -> f.unified()
.numberOfFragments( 1 ) ) (2)
.fetchHits( 20 );| 1 | 通过调用.single()强制使用单值突出显示投影。 |
| 2 | 强制片段数量为1,以便突出显示器最多返回一个突出显示的片段。 |
多值字段
多值字段的每个值都会被突出显示。请参阅如何配置突出显示器以调整返回结果的行为和结构。
List<List<String>> hits = searchSession.search( Book.class )
.select( f -> f.highlight( "flattenedAuthors.lastName" ) )
.where( f -> f.match().field( "flattenedAuthors.lastName" ).matching( "martinez" ) )
.fetchHits( 20 );突出显示选项
可以通过突出显示器的选项对其进行微调,以更改突出显示的输出。
List<List<String>> hits = searchSession.search( Book.class )
.select( f -> f.highlight( "title" ) ) (1)
.where( f -> f.match().field( "title" ).matching( "detective" ) )
.highlighter( f -> f.unified().tag( "<b>", "</b>" ) ) (2)
.fetchHits( 20 );| 1 | 像往常一样构建突出显示查询。 |
| 2 | 配置默认突出显示器。更改突出显示标签选项。 |
此外,如果突出显示多个字段,并且它们需要不同的突出显示器选项,则可以使用命名突出显示器来覆盖默认突出显示器。
List<List<?>> hits = searchSession.search( Book.class )
.select( f -> f.composite().from(
f.highlight( "title" ),
f.highlight( "description" ).highlighter( "description-highlighter" ) (1)
).asList() )
.where( f -> f.match().field( "title" ).matching( "detective" ) )
.highlighter( f -> f.unified().tag( "<b>", "</b>" ) ) (2)
.highlighter(
"description-highlighter",
f -> f.unified().tag( "<span>", "</span>" )
) (3)
.fetchHits( 20 );| 1 | 指定要应用于description字段突出显示投影的命名突出显示器的名称。 |
| 2 | 配置默认突出显示器。 |
| 3 | 配置命名突出显示器。 |
有关突出显示器配置的更多信息,请参阅突出显示 DSL。
投影到自定义类型中的@HighlightProjection
要在投影到带注释的自定义类型中实现highlight投影,请在构造函数参数上使用@HighlightProjection注释
@ProjectionConstructor (1)
public record MyBookTitleAndHighlightedDescriptionProjection(
@HighlightProjection (2)
List<String> description, (3)
String title (4)
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@HighlightProjection注释应接收突出显示值的参数。 |
| 3 | 在这种情况下,构造函数参数的类型必须可从List<String>赋值,因为我们期望返回多个突出显示的片段。 |
| 4 | 当然,你也可以声明其他具有不同投影的参数;在本例中,对 title 字段进行了 推断投影。 |
List<MyBookTitleAndHighlightedDescriptionProjection> hits = searchSession.search( Book.class )
.select( MyBookTitleAndHighlightedDescriptionProjection.class )(1)
.where( f -> f.match().field( "description" ).matching( "self-aware" ) )
.fetchHits( 20 ); (2)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 每个命中将是自定义投影类型的实例,使用请求的突出显示内容和字段填充。 |
@ProjectionConstructor (1)
public record MyBookHighlightedTitleProjection(
@HighlightProjection (2)
String title, (3)
String description
) {
}| 1 | 使用 @ProjectionConstructor 注解记录类型。 |
| 2 | 使用@HighlightProjection注释应接收突出显示值的参数。 |
| 3 | 在这种情况下,构造函数参数的类型必须可从String赋值,因为我们计划返回单个突出显示的片段。请注意,只有调用.numberOfFragments(1)的突出显示器才能用于单值突出显示投影。 |
List<MyBookHighlightedTitleProjection> hits = searchSession.search( Book.class )
.select( MyBookHighlightedTitleProjection.class )(1)
.where( f -> f.match().field( "title" ).matching( "robot" ) )
.highlighter( f -> f.unified().numberOfFragments( 1 ) ) (2)
.fetchHits( 20 ); (3)| 1 | 将自定义投影类型传递给 `。select(…)`。 |
| 2 | 配置突出显示器以返回单个突出显示的片段。 |
| 3 | 每个命中将是自定义投影类型的实例,使用请求的突出显示内容和字段填充。 |
注释公开了以下属性
path-
突出显示字段的路径。
如果未设置,则从构造函数参数名称推断。
如果构造函数参数名称未包含在 Java 字节码中,则字段路径推断将失败。
突出显示器-
查询中配置的突出显示器名称;用于对每个突出显示投影应用不同的选项。
如果未设置,则投影将使用查询中配置的默认突出显示器。
对于编程映射,请使用HighlightProjectionBinder.create()。
highlight投影TypeMappingStep myBookIdAndHighlightedTitleProjection =
mapping.type( MyBookTitleAndHighlightedDescriptionProjection.class );
myBookIdAndHighlightedTitleProjection.mainConstructor()
.projectionConstructor();
myBookIdAndHighlightedTitleProjection.mainConstructor().parameter( 0 )
.projection( HighlightProjectionBinder.create() );突出显示限制
目前,Hibernate Search 对突出显示投影可以包含的位置有限制,尝试在这些情况下应用突出显示投影会导致抛出异常,特别是
-
此类投影不能是对象投影的一部分。
示例 360. 在.object(..)投影中非法使用.highlight(..)投影List<List<?>> hits = searchSession.search( Book.class ) .select( f -> f.object( "authors" ) .from( f.highlight( "authors.firstName" ), f.highlight( "authors.lastName" ) ).asList() ) .where( f -> f.match().field( "authors.firstName" ).matching( "Art*" ) ) .fetchHits( 20 );这样做将导致异常。
-
具有嵌套结构的对象的字段在任何情况下都不能突出显示。
示例 361. 在.object(..)投影中非法使用.highlight(..)投影List<?> hits = searchSession.search( Book.class ) .select( f -> f.highlight( "authors.firstName" ) ) .where( f -> f.match().field( "authors.firstName" ).matching( "Art*" ) ) .fetchHits( 20 );假设
authors映射为嵌套结构,例如@IndexedEmbedded(structure = ObjectStructure.NESTED) private List<Author> authors = new ArrayList<>();尝试应用此类投影将导致抛出异常。
这些限制应由HSEARCH-4841解决。
15.4.14. withParameters:使用查询参数创建投影
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
withParameters投影允许使用查询参数构建投影。
这种类型的投影需要一个接受查询参数并返回投影的函数。该函数将在查询构建时被调用。
语法
withParameters投影的返回类型取决于.withParameters(..)中配置的投影类型
GeoPoint center = GeoPoint.of( 47.506060, 2.473916 );
SearchResult<Double> result = searchSession.search( Author.class )
.select( f -> f.withParameters( params -> f (1)
.distance( "placeOfBirth", params.get( "center", GeoPoint.class ) ) ) ) (2)
.where( f -> f.matchAll() )
.param( "center", center ) (3)
.fetch( 20 );| 1 | 开始创建.withParameters()投影。 |
| 2 | 在构建投影时访问GeoPoint类型的查询参数center。 |
| 3 | 在查询级别设置投影所需的参数。 |
15.4.15. 后端特定扩展
通过在构建查询时调用.extension(…),可以访问后端特定的投影。
|
顾名思义,后端特定投影不可从一种后端技术移植到另一种后端技术。 |
Lucene:document
.document()投影将匹配的文档作为本机 Lucene Document返回。
|
此功能意味着应用程序代码直接依赖 Lucene API。 即使是针对错误修复(微型)版本的 Hibernate Search 升级也可能需要升级 Lucene,这可能会导致 Lucene 的 API 发生重大更改。 如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
Lucene:documentTree
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
.documentTree()投影将匹配的文档作为包含本机 Lucene Document和相应嵌套树节点的树返回。
|
此功能意味着应用程序代码直接依赖 Lucene API。 即使是针对错误修复(微型)版本的 Hibernate Search 升级也可能需要升级 Lucene,这可能会导致 Lucene 的 API 发生重大更改。 如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
语法
DocumentTree返回List<DocumentTree> hits = searchSession.search( Book.class )
.extension( LuceneExtension.get() )
.select( f -> f.documentTree() )
.where( f -> f.matchAll() )
.fetchHits( 20 );|
此树中返回的文档具有与 |
Lucene:explanation
.explanation()投影将匹配的解释作为本机 Lucene Explanation返回。
|
无论使用哪种 API,解释在性能方面都相当昂贵:仅将其用于调试目的。 |
|
此功能意味着应用程序代码直接依赖 Lucene API。 即使是针对错误修复(微型)版本的 Hibernate Search 升级也可能需要升级 Lucene,这可能会导致 Lucene 的 API 发生重大更改。 如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
Elasticsearch:source
.source()投影将文档的 JSON 作为JsonObject返回,就像它在 Elasticsearch 中索引时一样。
|
此功能要求直接在应用程序代码中操作 JSON。 此 JSON 的语法可能会发生更改
如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
Elasticsearch:explanation
.explanation()投影将匹配的解释作为JsonObject返回。
|
无论使用哪种 API,解释在性能方面都相当昂贵:仅将其用于调试目的。 |
|
此功能要求直接在应用程序代码中操作 JSON。 此 JSON 的语法可能会发生更改
如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
Elasticsearch:jsonHit
.jsonHit()投影将 Elasticsearch 为命中返回的完全 JSON 作为JsonObject返回。
|
当自定义请求的 JSON以请求每个命中中的附加数据时,这尤其有用。 |
|
此功能要求直接在应用程序代码中操作 JSON。 此 JSON 的语法可能会发生更改
如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
15.5. 突出显示 DSL
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
15.5.1. 基础
高亮显示是一种投影,它从匹配文档的全文字段中返回片段,这些片段导致了查询匹配。导致匹配的特定术语将用一对开始和结束标签“突出显示”。它可以帮助用户在结果页面上快速识别他们正在搜索的信息。
高亮投影仅适用于全文字段,这些字段具有允许它的属性配置。
@Entity(name = Book.NAME)
@Indexed
public class Book {
public static final String NAME = "Book";
@Id
private Integer id;
@FullTextField(analyzer = "english") (1)
private String author;
@FullTextField(analyzer = "english",
highlightable = { Highlightable.PLAIN, Highlightable.UNIFIED }) (2)
private String title;
@FullTextField(analyzer = "english",
highlightable = Highlightable.ANY) (3)
@Column(length = 10000)
private String description;
@FullTextField(analyzer = "english",
projectable = Projectable.YES,
termVector = TermVector.WITH_POSITIONS_OFFSETS) (4)
@Column(length = 10000)
@ElementCollection
private List<String> text;
@GenericField (5)
@Column(length = 10000)
@ElementCollection
private List<String> keywords;
}| 1 | 一个常规的全文字段。如果使用Elasticsearch 后端,此类字段可以允许高亮投影。有关任何详细信息,请参阅默认可高亮的定义。 |
| 2 | 一个明确允许将普通和统一高亮器应用于它的全文字段。 |
| 3 | 一个明确允许将任何高亮器类型应用于它的全文字段。有关更多详细信息,请参阅ANY 可高亮的定义。 |
| 4 | 一个隐式允许将任何高亮器类型应用于它的全文字段。允许投影并将术语向量存储策略设置为WITH_POSITIONS_OFFSETS意味着可以使用任何高亮器类型使用Lucene或Elasticsearch 后端创建高亮投影。 |
| 5 | 一个通用文本字段 - 此类字段不允许高亮投影。 |
SearchSession searchSession = /* ... */ (1)
List<List<String>> result = searchSession.search( Book.class ) (2)
.select( f -> f.highlight( "title" ) ) (3)
.where( f -> f.match().field( "title" ).matching( "mystery" ) ) (4)
.fetchHits( 20 ); (5)| 1 | 检索 SearchSession. |
| 2 | 像往常一样开始构建查询。 |
| 3 | 请注意,查询的预期结果是对“title”字段的高亮显示。如果该字段不是全文字段且启用了高亮显示,或者该字段不存在,则会抛出异常。 |
| 4 | where 子句中的谓词将用于确定要包含在结果中的文档以及突出显示“title”字段中的文本。 请注意,要获得高亮投影的非空列表,我们应用这种投影的字段应该是一个谓词的一部分。如果我们想要突出显示的字段中没有匹配项,无论是由于文档由于其他谓词条件而被添加到结果中,还是由于突出显示的字段根本不是谓词的一部分,默认情况下将返回一个空列表。有关如何调整此设置的更多详细信息,请参阅无匹配大小配置选项。 |
| 5 | 获取结果,其中将包含突出显示的片段。 |
请注意,应用高亮投影的结果始终是String列表。
例如,结果可能如下所示:
[
["The Boscombe Valley <em>Mystery</em>"], (1)
[
"A Caribbean <em>Mystery</em>",
"Miss Marple: A Caribbean <em>Mystery</em> by Agatha Christie"
], (2)
["A <em>Mystery</em> of <em>Mysteries</em>: The Death and Life of Edgar Allan Poe"] (3)
]| 1 | 第一个命中。 |
| 2 | 第二个命中,包含多个突出显示的片段。 |
| 3 | 第三个命中。 |
高亮投影,就像字段投影一样,也可以与其他投影类型以及其他高亮投影结合使用。
List<List<?>> result = searchSession.search( Book.class ) (1)
.select( f -> f.composite().from(
f.id(), (2)
f.field( "title", String.class ), (3)
f.highlight( "description" ) (4)
).asList() )
.where( f -> f.match().fields( "title", "description" ).matching( "scandal" ) ) (5)
.fetchHits( 20 ); (6)可以配置高亮器行为。请参阅各种可用的配置选项。高亮器定义在查询的 where 子句之后提供。
List<List<?>> result = searchSession.search( Book.class )
.select( f -> f.composite().from(
f.highlight( "title" ),
f.highlight( "description" )
).asList() )
.where( f -> f.match().fields( "title", "description" ).matching( "scandal" ) ) (1)
.highlighter( f -> f.plain().noMatchSize( 100 ) ) (2)
.fetchHits( 20 ); (3)| 1 | 指定一个谓词,该谓词将在title和description字段中查找匹配项。 |
| 2 | 指定默认高亮器的详细信息。将无匹配大小设置为正值,让高亮器知道我们希望即使在一个特定字段中没有要高亮的内容,也要获取一些文本。 |
| 3 | 获取结果。 |
15.5.2. 高亮器类型
在配置高亮器之前,您需要选择它的类型。选择高亮器类型是高亮器定义的第一步。
searchSession.search( Book.class )
.select( f -> f.highlight( "title" ) )
.where( f -> f.match().fields( "title", "description" ).matching( "scandal" ) )
.highlighter( f -> f.plain() /* ... */ ) (1)
.fetchHits( 20 );| 1 | 开始定义普通高亮器。 |
searchSession.search( Book.class )
.select( f -> f.highlight( "title" ) )
.where( f -> f.match().fields( "title", "description" ).matching( "scandal" ) )
.highlighter( f -> f.unified() /* ... */ ) (1)
.fetchHits( 20 );| 1 | 开始定义统一高亮器。 |
searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "title", "description" ).matching( "scandal" ) )
.highlighter( f -> f.fastVector() /* ... */ ) (1)
.fetchHits( 20 );| 1 | 开始定义快速向量高亮器。 |
在选择高亮器类型时,有三种选项可供选择。
- 普通
-
普通高亮器对于针对少量文档上的单个字段的简单查询非常有用。此高亮器使用标准 Lucene 高亮器。它读取突出显示字段的字符串值,然后从中创建一个小型的内存索引,并应用查询逻辑来执行高亮显示。
- 统一
-
统一高亮器是默认使用的,它不一定依赖于重新分析文本,因为它可以从 postings 或术语向量中获取偏移量。
此高亮器使用断句器(默认情况下将文本分成句子)将文本分成后面要评分的段落。它更好地支持更复杂的查询。由于它可以使用预建数据,因此与普通高亮器相比,它在大量文档的情况下表现更好。
15.5.3. 命名高亮器
有时我们可能希望将不同的高亮器应用于不同的字段。我们已经看到可以配置高亮器。该示例中的高亮器称为默认高亮器。搜索查询还允许配置命名高亮器。命名高亮器具有与默认高亮器相同的配置功能。它会覆盖由默认高亮器设置的选项(如果已配置)。如果为查询配置了默认高亮器,则在同一查询上配置的每个命名高亮器必须与默认高亮器具有相同的类型。仅当未配置默认高亮器时,才允许在同一查询中混合各种高亮器类型。
当高亮投影将命名高亮器传递给作为高亮投影定义的一部分链接的可选highlighter(..)调用时,该特定高亮器将应用于字段投影。命名高亮器可以在查询中重复使用,即,同一个命名高亮器的名称可以传递给多个高亮投影。
List<List<?>> result = searchSession.search( Book.class )
.select( f -> f.composite().from(
f.highlight( "title" ), (1)
f.highlight( "description" ).highlighter( "customized-plain-highlighter" ) (2)
).asList() )
.where( f -> f.match().fields( "title", "description" ).matching( "scandal" ) )
.highlighter( f -> f.plain().tag( "<b>", "</b>" ) ) (3)
.highlighter( "customized-plain-highlighter", f -> f.plain().noMatchSize( 100 ) ) (4)
.fetchHits( 20 ); (5)| 1 | 在“title”字段上添加高亮投影。此投影使用默认高亮器。 |
| 2 | 在“description”字段上添加高亮投影并指定命名高亮器的名称。 |
| 3 | 指定默认高亮器的详细信息。 |
| 4 | 指定命名高亮器的详细信息。请注意,名称与传递给“description”高亮投影配置的名称匹配。 |
| 5 | 获取结果。 |
|
命名高亮器的名称不能为 |
15.5.4. 标签
默认情况下,突出显示的文本用一对<em>/</em>标签包装。可以提供自定义的标签对来更改此行为。通常,标签是一对 HTML 标签,但它们可以是一对任意字符序列。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "title" ) )
.where( f -> f.match().fields( "title" ).matching( "scandal" ) )
.highlighter( f -> f.unified().tag( "<strong>", "</strong>" ) ) (1)
.fetchHits( 20 );| 1 | 传递一对将用于突出显示文本的开/闭标签。 |
快速向量高亮器可以处理多个标签,它还有一些额外的接受标签集合的方法。
result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "scandal" ) )
.highlighter( f -> f.fastVector()
.tags( (1)
Arrays.asList( "<em class=\"class1\">", "<em class=\"class2\">" ),
"</em>"
) )
.fetchHits( 20 );
result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "scandal" ) )
.highlighter( f -> f.fastVector()
.tags( (2)
Arrays.asList( "<em>", "<strong>" ),
Arrays.asList( "</em>", "</strong>" )
) )
.fetchHits( 20 );| 1 | 传递一组将用于突出显示文本的打开标签和单个关闭标签。当配置仅在打开标签的属性中不同的标签模式时,这很有帮助。 |
| 2 | 传递一对包含将用于突出显示文本的开/闭标签的集合。 |
此外,快速向量高亮器可以选择启用标签模式并将其设置为HighlighterTagSchema.STYLED以使用预定义的标签集。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "scandal" ) )
.highlighter( f -> f.fastVector()
.tagSchema( HighlighterTagSchema.STYLED ) (1)
)
.fetchHits( 20 );| 1 | 传递一个将用于突出显示文本的带样式的标签模式。 |
使用带样式的标签模式只是定义标签的快捷方式,如
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "scandal" ) )
.highlighter( f -> f.fastVector()
.tags( Arrays.asList(
"<em class=\"hlt1\">",
"<em class=\"hlt2\">",
"<em class=\"hlt3\">",
"<em class=\"hlt4\">",
"<em class=\"hlt5\">",
"<em class=\"hlt6\">",
"<em class=\"hlt7\">",
"<em class=\"hlt8\">",
"<em class=\"hlt9\">",
"<em class=\"hlt10\">"
), "</em>" ) (1)
)
.fetchHits( 20 );| 1 | 传递与应用带样式的模式时使用的相同标签集合。 |
|
在同一个高亮器定义中调用不同的标签配置方法 ( |
15.5.5. 编码器
在高亮显示存储 HTML 的字段时,可以对突出显示的片段应用编码。将 HTML 编码器应用于高亮器将对文本进行编码以将其包含到 HTML 文档中:它将替换 HTML 元字符(如<)及其实体等效项(如<);但是它不会转义高亮标签。默认情况下,将使用HighlighterEncoder.DEFAULT编码器,该编码器会将文本保持原样。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "title" ) )
.where( f -> f.match().fields( "title" ).matching( "scandal" ) )
.highlighter( f -> f.unified().encoder( HighlighterEncoder.HTML ) ) (1)
.fetchHits( 20 );| 1 | 配置 HTML 编码器。 |
15.5.6. 无匹配大小
在更复杂的查询或对多个字段执行高亮显示的情况下,可能会导致查询匹配了文档,但特定高亮显示字段没有为该匹配做出贡献。这将导致该特定文档和该字段的高亮显示为空列表。无匹配大小选项允许您即使字段没有为文档匹配做出贡献,也没有要高亮显示的内容,也可以仍然获得一些返回的文本。
此属性设置的数字定义了从字段开头开始包含的字符数。根据高亮器类型,返回的文本量可能与配置的值不完全匹配,因为高亮器通常会尝试不在单词/句子的中间断开文本,具体取决于它们的配置。默认情况下,此选项设置为0,并且只有在有要高亮显示的内容时才会返回文本。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.bool()
.must( f.match().fields( "title" ).matching( "scandal" ) ) (1)
.should( f.match().fields( "description" ).matching( "scandal" ) ) (2)
)
.highlighter( f -> f.fastVector().noMatchSize( 100 ) ) (3)
.fetchHits( 20 );| 1 | 我们在标题中寻找匹配项。 |
| 2 | 如果在一个词也出现在描述中,我们希望它被突出显示。 |
| 3 | 将无匹配大小设置为100,即使我们搜索的词没有匹配到,也要获得至少100个描述的第一个字符。 |
|
来自 Lucene 后端 的统一高亮器对该选项的支持有限。它无法限制返回文本的数量,并且更像是一个布尔标志来启用/禁用该功能。如果此类型的高亮器没有设置该选项或将其设置为 |
15.5.7. 片段大小和片段数量
片段大小设置包含在每个高亮片段中的文本量,默认值为 100 个字符。
|
这不是一个“硬”限制,因为高亮器通常会尝试不在单词中间打断片段。此外,边界扫描 等其他功能也可能导致片段之前和之后的更多文本被包含在内。 |
片段数量配置设置结果高亮列表中包含的字符串的最大数量。默认情况下,片段数量限制为 5。
这些选项的组合在高亮大型文本字段时可能会有所帮助。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "king" )
)
.highlighter( f -> f.fastVector()
.fragmentSize( 50 ) (1)
.numberOfFragments( 2 ) (2)
)
.fetchHits( 20 );| 1 | 配置片段大小。 |
| 2 | 配置要返回的片段的最大数量。 |
|
这些选项由 Elasticsearch 后端上的所有高亮器类型支持。至于 Lucene 后端,所有高亮器类型也都支持片段数量,而只有普通和快速矢量高亮器支持片段大小。 |
15.5.8. 顺序
默认情况下,高亮片段按文本中出现的顺序返回。通过启用按分数排序选项,最相关的片段将返回到列表的顶部。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.bool() (1)
.should( f.match().fields( "description" ).matching( "king" ) )
.should( f.match().fields( "description" ).matching( "souvenir" ).boost( 10.0f ) )
)
.highlighter( f -> f.fastVector().orderByScore( true ) ) (2)
.fetchHits( 20 );| 1 | 一个查询,它将提升其中一个搜索词的匹配度。 |
| 2 | 配置按分数排序以启用。 |
15.5.9. 分割器
默认情况下,普通高亮器将文本分解成相同大小的片段,但会尝试避免分解要高亮的短语。这是 HighlighterFragmenter.SPAN 分割器的行为。或者,分割器可以设置为 HighlighterFragmenter.SIMPLE,它只是将文本分解成相同大小的片段。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "souvenir" ) )
.highlighter( f -> f.plain().fragmenter( HighlighterFragmenter.SIMPLE ) ) (1)
.fetchHits( 20 );| 1 | 配置简单分割器。 |
|
此选项仅由普通高亮器支持。 |
15.5.10. 边界扫描器
统一和快速矢量高亮器使用边界扫描器来创建高亮片段:它们尝试通过扫描片段之前和之后的文本以查找单词/句子边界来扩展高亮片段。
可以提供一个可选的区域设置参数来指定如何搜索句子和单词边界。句子边界扫描器是统一高亮器的默认选项。
有两种方法可以将边界扫描器配置提供给高亮器。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "king" ) )
.highlighter( f -> f.fastVector()
.boundaryScanner() (1)
.word() (2)
.locale( Locale.ENGLISH ) (3)
.end() (4)
/* ... */ (5)
)
.fetchHits( 20 );| 1 | 开始边界扫描器的定义。 |
| 2 | 选择一个边界扫描器类型,在本例中为单词扫描器。 |
| 3 | 设置可选的区域设置。 |
| 4 | 结束边界扫描器的定义。 |
| 5 | 设置任何其他选项。 |
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "king" ) )
.highlighter( f -> f.fastVector()
.boundaryScanner(
bs -> bs.word() (1)
)
/* ... */ (2)
)
.fetchHits( 20 );| 1 | 传递一个 lambda 配置器来设置边界扫描器。 |
| 2 | 设置任何其他选项 |
或者,快速矢量高亮器可以使用字符边界扫描器,它依赖于其他两个配置,即边界字符和边界最大扫描。当使用字符边界扫描器后,使用高亮文本居中形成高亮片段后,高亮器会检查当前创建的片段左右两侧配置的边界字符的第一个出现位置。此查找仅针对由边界最大扫描选项配置的最大字符数进行。如果找不到边界字符,除了基于为高亮器设置的片段大小选项的已高亮短语及其周围文本之外,不会包含任何其他文本。
边界字符的默认列表包括 .,!? \t\n。默认边界最大扫描等于 20 个字符。
字符边界扫描器是快速矢量高亮器的默认选项。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "scene" ) )
.highlighter( f -> f.fastVector()
.boundaryScanner() (1)
.chars() (2)
.boundaryChars( "\n" ) (3)
.boundaryMaxScan( 1000 ) (4)
.end() (5)
/* ... */ (6)
)
.fetchHits( 20 );假设我们有一个包含多个用换行符 (\n) 分隔的段落的文本,我们希望获得包含高亮短语的整个段落。为此,边界字符将设置为 \n,并且最大扫描选项将基于段落中的字符数量。
| 1 | 开始边界扫描器的定义。 |
| 2 | 选择一个边界扫描器类型,即字符扫描器。 |
| 3 | 设置一个包含边界字符的字符串。重载方法可以接受一个 String 或一个 Character 数组。 |
| 4 | 设置最大扫描选项。 |
| 5 | 结束边界扫描器的定义。 |
| 6 | 设置任何其他选项。 |
|
此选项由统一和快速矢量高亮器类型支持。 |
15.5.11. 短语限制
短语限制允许指定文档中用于高亮的匹配短语的最大数量。高亮器将遍历文本,一旦达到高亮短语的最大数量,它就会停止,使任何进一步的出现不突出显示。
|
此限制不同于 片段的最大数量
|
默认情况下,此短语限制等于 256。
如果字段包含许多匹配项并且总体上有很多文本,但我们对突出显示每个出现次数不感兴趣,则此选项可能会有所帮助。
List<List<String>> result = searchSession.search( Book.class )
.select( f -> f.highlight( "description" ) )
.where( f -> f.match().fields( "description" ).matching( "bank" ) )
.highlighter( f -> f.fastVector()
.phraseLimit( 1 ) (1)
)
.fetchHits( 20 );| 1 | 配置短语限制。 |
|
此选项仅由快速矢量高亮器类型支持。 |
15.6. 聚合 DSL
15.6.1. 基础
有时,您不仅需要直接列出查询命中项:您还需要对命中项进行分组和聚合。
例如,您访问的几乎任何电子商务网站都会有一些“分面”,这是一种简单的聚合形式。在在线书店的“图书搜索”网页中,除了匹配图书的列表之外,您还会找到“分面”,即各种类别中匹配文档的数量。这些类别可以直接从索引数据中获取,例如书籍的类型(科幻、犯罪小说等),也可以从索引数据中稍微推导出来,例如价格范围(“低于 5 美元”、“低于 10 美元”等)。
聚合允许这样做(以及根据后端实现更多功能):它们允许查询返回“聚合”命中项。
SearchSession searchSession = /* ... */ (1)
AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" ); (2)
SearchResult<Book> result = searchSession.search( Book.class ) (3)
.where( f -> f.match().field( "title" ) (4)
.matching( "robot" ) )
.aggregation( countsByGenreKey, f -> f.terms() (5)
.field( "genre", Genre.class ) )
.fetch( 20 ); (6)
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey ); (7)| 1 | 检索 SearchSession. |
| 2 | 定义一个键,该键将唯一标识聚合。确保为其提供正确的类型(参见 <6>)。 |
| 3 | 像往常一样开始构建查询。 |
| 4 | 定义一个谓词:聚合将仅考虑匹配此谓词的文档。 |
| 5 | 请求对 genre 字段进行聚合,每个类型都有一个单独的计数:科幻、犯罪小说等。如果该字段不存在或无法聚合,则会抛出异常。 |
| 6 | 获取结果。 |
| 7 | 从结果中检索聚合作为 Map,以类型为 Long 的类型为键和命中计数为值。 |
或者,如果您不想使用 lambda
SearchSession searchSession = /* ... */
SearchScope<Book> scope = searchSession.scope( Book.class );
AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( scope )
.where( scope.predicate().match().field( "title" )
.matching( "robot" )
.toPredicate() )
.aggregation( countsByGenreKey, scope.aggregation().terms()
.field( "genre", Genre.class )
.toAggregation() )
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey );|
分面通常涉及“向下钻取”的概念,即选择分面并将命中项限制为仅匹配该分面的那些命中项的能力。 Hibernate Search 5 以前提供了一个专门的 API 来启用这种“向下钻取”,但在 Hibernate Search 6 中,您只需使用适当的 谓词 创建一个新的查询即可。 |
聚合 DSL 提供了更多聚合类型,以及每种聚合类型的多个选项。要了解有关 terms 聚合的更多信息以及所有其他类型的聚合,请参阅以下部分。
15.6.2. terms:按字段的值分组
terms 聚合返回给定字段的每个项值的文档计数。
|
|
AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", Genre.class ) ) (1)
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey ); (2)| 1 | 定义应考虑其值的字段的路径和类型。 |
| 2 | 结果是从字段值到文档计数的映射。 |
跳过转换
默认情况下,terms 聚合返回的值与对应于目标字段的实体属性具有相同的类型。
例如,如果实体属性是枚举类型,相应的字段可能为 String 类型;terms 聚合返回的值将始终是枚举类型。
这通常应该是您想要的,但是如果您需要绕过转换并将未转换的值返回给您(在上面的示例中为类型String),则可以按以下方式进行
AggregationKey<Map<String, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", String.class, ValueModel.INDEX ) )
.fetch( 20 );
Map<String, Long> countsByGenre = result.aggregation( countsByGenreKey );有关更多信息,请参阅投影值的类型。
maxTermCount:限制返回条目的数量
默认情况下,Hibernate Search 将最多返回 100 个条目。您可以通过调用 .maxTermCount(…) 来自定义限制
terms 聚合中返回条目的最大数量AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", Genre.class )
.maxTermCount( 1 ) )
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey );minDocumentCount:要求每个项至少有 N 个匹配文档
默认情况下,Hibernate search 仅在文档计数至少为 1 时返回条目。
您可以通过调用 .minDocumentCount(…) 将阈值设置为任意值。
这在返回索引中存在的所有项时特别有用,即使没有包含该项的文档与查询匹配。为此,只需调用 .minDocumentCount(0) 即可
terms 聚合中包含来自未匹配文档的值AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", Genre.class )
.minDocumentCount( 0 ) )
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey );这也可以用来省略文档计数过低而无关紧要的条目
terms 聚合中排除最稀有的项AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", Genre.class )
.minDocumentCount( 2 ) )
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey );条目顺序
默认情况下,条目按文档计数的降序返回,即具有最多匹配文档的项先出现。
提供了几种其他顺序。
|
使用 Lucene 后端,由于当前实现的限制,使用除默认顺序(按降序计数)之外的任何顺序都可能导致结果不正确。有关更多信息,请参阅 HSEARCH-3666。 |
您可以按升序项值对条目进行排序
terms 聚合中的条目进行排序AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", Genre.class )
.orderByTermAscending() )
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey );您可以按降序对条目进行排序
terms 聚合中的条目进行排序AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", Genre.class )
.orderByTermDescending() )
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey );最后,您可以按升序文档计数对条目进行排序
terms 聚合中的条目进行排序AggregationKey<Map<Genre, Long>> countsByGenreKey = AggregationKey.of( "countsByGenre" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByGenreKey, f -> f.terms()
.field( "genre", Genre.class )
.orderByCountAscending() )
.fetch( 20 );
Map<Genre, Long> countsByGenre = result.aggregation( countsByGenreKey );|
在按升序计数对 |
其他选项
-
对于嵌套对象中的字段,默认情况下会考虑所有嵌套对象,但可以使用
.filter(…)显式控制。
15.6.3. range:按字段值的范围分组
range 聚合返回给定字段的给定值范围的文档计数。
|
|
AggregationKey<Map<Range<Double>, Long>> countsByPriceKey = AggregationKey.of( "countsByPrice" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByPriceKey, f -> f.range()
.field( "price", Double.class ) (1)
.range( 0.0, 10.0 ) (2)
.range( 10.0, 20.0 )
.range( 20.0, null ) (3)
)
.fetch( 20 );
Map<Range<Double>, Long> countsByPrice = result.aggregation( countsByPriceKey );| 1 | 定义应考虑其值的字段的路径和类型。 |
| 2 | 定义将命中次数分组的范围。范围可以直接作为下限(包括)和上限(不包括)传递。其他语法存在于定义不同的边界包含(请参见下面的其他示例)。 |
| 3 | null 表示“到无穷大”。 |
传递 Range 参数
除了为每个范围传递两个参数(下限和上限)之外,您还可以传递一个类型为 Range 的参数。
Range 对象AggregationKey<Map<Range<Double>, Long>> countsByPriceKey = AggregationKey.of( "countsByPrice" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByPriceKey, f -> f.range()
.field( "price", Double.class )
.range( Range.canonical( 0.0, 10.0 ) ) (1)
.range( Range.between( 10.0, RangeBoundInclusion.INCLUDED,
20.0, RangeBoundInclusion.EXCLUDED ) ) (2)
.range( Range.atLeast( 20.0 ) ) (3)
)
.fetch( 20 );
Map<Range<Double>, Long> countsByPrice = result.aggregation( countsByPriceKey );| 1 | 使用 Range.of(Object, Object),下限包含在内,上限不包括在内。 |
| 2 | Range.of(Object, RangeBoundInclusion, Object, RangeBoundInclusion) 更加详细,但允许显式设置边界包含。 |
| 3 | Range 还提供多种静态方法来为各种用例创建范围(“至少”,“大于”,“至多”等)。 |
|
使用 Elasticsearch 后端,由于 Elasticsearch 本身的限制,所有范围都必须将其下限包含在内(或 如果您需要排除下限,或包含上限,请用下一个值替换该边界。例如,对于整数, |
也可以传递 Range 对象的集合,这在动态定义范围时特别有用(例如,在 Web 界面中)。
Range 对象的集合List<Range<Double>> ranges =
/* ... */;
AggregationKey<Map<Range<Double>, Long>> countsByPriceKey = AggregationKey.of( "countsByPrice" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByPriceKey, f -> f.range()
.field( "price", Double.class )
.ranges( ranges )
)
.fetch( 20 );
Map<Range<Double>, Long> countsByPrice = result.aggregation( countsByPriceKey );跳过转换
默认情况下,range 聚合接受的范围边界必须与对应于目标字段的实体属性具有相同的类型。
例如,如果实体属性的类型为 java.util.Date,相应的字段可能是 java.time.Instant 类型;terms 聚合返回的值必须为 java.util.Date 类型,无论如何。
这通常是您想要的,但是如果您需要绕过转换并让未转换的值返回给您(在上面的示例中为 java.time.Instant 类型),您可以通过这种方式进行。
AggregationKey<Map<Range<Instant>, Long>> countsByPriceKey = AggregationKey.of( "countsByPrice" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByPriceKey, f -> f.range()
// Assuming "releaseDate" is of type "java.util.Date" or "java.sql.Date"
.field( "releaseDate", Instant.class, ValueModel.INDEX )
.range( null,
LocalDate.of( 1970, 1, 1 )
.atStartOfDay().toInstant( ZoneOffset.UTC ) )
.range( LocalDate.of( 1970, 1, 1 )
.atStartOfDay().toInstant( ZoneOffset.UTC ),
LocalDate.of( 2000, 1, 1 )
.atStartOfDay().toInstant( ZoneOffset.UTC ) )
.range( LocalDate.of( 2000, 1, 1 )
.atStartOfDay().toInstant( ZoneOffset.UTC ),
null )
)
.fetch( 20 );
Map<Range<Instant>, Long> countsByPrice = result.aggregation( countsByPriceKey );有关更多信息,请参见 传递给 DSL 的参数类型。
其他选项
-
对于嵌套对象中的字段,默认情况下会考虑所有嵌套对象,但可以使用
.filter(…)显式控制。
15.6.4. withParameters:使用查询参数创建聚合
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
withParameters 聚合允许使用 查询参数 来构建聚合。
这种类型的聚合需要一个接受查询参数并返回聚合的函数。该函数将在构建查询时被调用。
AggregationKey<Map<Range<Double>, Long>> countsByPriceKey = AggregationKey.of( "countsByPrice" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByPriceKey, f -> f.withParameters( params -> f.range() (1)
.field( "price", Double.class )
.range( params.get( "bound0", Double.class ), params.get( "bound1", Double.class ) ) (2)
.range( params.get( "bound1", Double.class ), params.get( "bound2", Double.class ) )
.range( params.get( "bound2", Double.class ), params.get( "bound3", Double.class ) )
) )
.param( "bound0", 0.0 ) (3)
.param( "bound1", 10.0 )
.param( "bound2", 20.0 )
.param( "bound3", null )
.fetch( 20 );
Map<Range<Double>, Long> countsByPrice = result.aggregation( countsByPriceKey );| 1 | 开始创建 .withParameters() 聚合。 |
| 2 | 在构建聚合时访问类型为 Double 的查询参数,定义范围边界。 |
| 3 | 在查询级别设置聚合所需的参数。 |
15.6.5. 后端特定扩展
通过在构建查询时调用 .extension(…),可以访问后端特定的聚合。
|
顾名思义,后端特定的聚合不能从一个后端技术移植到另一个后端技术。 |
Elasticsearch:fromJson
.fromJson(…) 将表示 Elasticsearch 聚合的 JSON 转换为 Hibernate Search 聚合。
|
此功能要求直接在应用程序代码中操作 JSON。 此 JSON 的语法可能会发生更改
如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
JsonObjectJsonObject jsonObject =
/* ... */;
AggregationKey<JsonObject> countsByPriceHistogramKey = AggregationKey.of( "countsByPriceHistogram" );
SearchResult<Book> result = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() )
.where( f -> f.matchAll() )
.aggregation( countsByPriceHistogramKey, f -> f.fromJson( jsonObject ) )
.fetch( 20 );
JsonObject countsByPriceHistogram = result.aggregation( countsByPriceHistogramKey ); (1)| 1 | 聚合结果是一个 JsonObject。 |
AggregationKey<JsonObject> countsByPriceHistogramKey = AggregationKey.of( "countsByPriceHistogram" );
SearchResult<Book> result = searchSession.search( Book.class )
.extension( ElasticsearchExtension.get() )
.where( f -> f.matchAll() )
.aggregation( countsByPriceHistogramKey, f -> f.fromJson( "{"
+ " \"histogram\": {"
+ " \"field\": \"price\","
+ " \"interval\": 10"
+ " }"
+ "}" ) )
.fetch( 20 );
JsonObject countsByPriceHistogram = result.aggregation( countsByPriceHistogramKey ); (1)| 1 | 聚合结果是一个 JsonObject。 |
15.6.6. 多种聚合类型共有的选项
过滤嵌套对象中的字段
当聚合字段位于 嵌套对象 中时,默认情况下会考虑所有嵌套对象进行聚合,并且文档将在每个嵌套对象中找到的值计数一次。
可以使用 filter(…) 方法之一过滤将被视为聚合值的嵌套文档。
下面是 范围聚合 的示例:聚合的结果是每个价格范围的书籍数量,其中只考虑了“平装本”版本的书籍价格;例如,电子书版本的书籍价格会被忽略。
AggregationKey<Map<Range<Double>, Long>> countsByPriceKey = AggregationKey.of( "countsByPrice" );
SearchResult<Book> result = searchSession.search( Book.class )
.where( f -> f.matchAll() )
.aggregation( countsByPriceKey, f -> f.range()
.field( "editions.price", Double.class )
.range( 0.0, 10.0 )
.range( 10.0, 20.0 )
.range( 20.0, null )
.filter( pf -> pf.match().field( "editions.label" ).matching( "paperback" ) )
)
.fetch( 20 );
Map<Range<Double>, Long> countsByPrice = result.aggregation( countsByPriceKey );15.7. 字段类型和兼容性
15.7.1. 传递给 DSL 的参数类型
一些谓词,例如 match 谓词或 range 谓词,在某些时候需要 Object 类型的参数(matching(Object)、atLeast(Object) 等)。类似地,在定义缺失值的排序行为时(missing().use(Object)),可以在排序 DSL 中传递 Object 类型的参数。
这些方法实际上并不接受 **任何** 对象,并且在传递类型错误的参数时会抛出异常。
通常,此参数的预期类型应该是相当明显的:例如,如果您通过映射 Integer 属性创建了一个字段,那么在构建谓词时会期望一个 Integer 值;如果您映射了 java.time.LocalDate,那么会期望一个 java.time.LocalDate,依此类推。
如果您开始定义和使用自定义桥接,事情会变得更加复杂。然后,您将拥有类型为 A 的属性映射到类型为 B 的索引字段。您应该向 DSL 传递什么?为了回答这个问题,我们需要了解 DSL 转换器。
DSL 转换器是 Hibernate Search 的一项功能,它允许 DSL 接受与索引属性类型匹配的参数,而不是底层索引字段的类型。
每个自定义桥接都有可能为其填充的索引字段定义一个 DSL 转换器。当它这样做时,每次在谓词 DSL 中提及该字段时,Hibernate Search 将使用该 DSL 转换器将传递给 DSL 的值转换为后端理解的值。
例如,让我们想象一个 AuthenticationEvent 实体,它具有类型为 AuthenticationOutcome 的 outcome 属性。此 AuthenticationOutcome 类型是一个枚举。我们索引 AuthenticationEvent 实体及其 outcome 属性,以便允许用户通过其结果查找事件。
枚举的默认桥接将 Enum.name() 的结果放入 String 字段中。但是,此默认桥接在后台也定义了 DSL 转换器。因此,任何对 DSL 的调用都将预期传递一个 AuthenticationOutcome 实例
List<AuthenticationEvent> result = searchSession.search( AuthenticationEvent.class )
.where( f -> f.match().field( "outcome" )
.matching( AuthenticationOutcome.INVALID_PASSWORD ) )
.fetchHits( 20 );这很方便,特别适用于要求用户在选项列表中选择结果的情况。但是,如果我们希望用户输入一些单词,即如果我们希望在 outcome 字段上进行全文搜索,该怎么办?然后,我们将没有 AuthenticationOutcome 实例传递给 DSL,只有一个 String……
在这种情况下,我们将首先需要为每个枚举分配一些文本。这可以通过定义一个自定义 ValueBridge<AuthenticationOutcome, String> 并将其应用于 outcome 属性来实现,以便索引结果的文本描述,而不是默认的 Enum#name()。
然后,我们需要告诉 Hibernate Search,传递给 DSL 的值不应传递给 DSL 转换器,而应假定它直接匹配索引字段的类型(在本例中为 String)。为此,可以简单地使用接受 ValueModel 参数的 matching 方法的变体,并传递 ValueModel.INDEX
List<AuthenticationEvent> result = searchSession.search( AuthenticationEvent.class )
.where( f -> f.match().field( "outcome" )
.matching( "Invalid password", ValueModel.INDEX ) )
.fetchHits( 20 );所有应用 DSL 转换器的方法都提供了一个接受 ValueModel 参数的变体:matching、between、atLeast、atMost、greaterThan、lessThan、range 等。
在某些情况下,将字符串值传递给这些 DSL 步骤可能会有所帮助。ValueModel.STRING 可用于解决此问题。默认情况下,字符串格式应与 具有内置值桥接的属性类型 中定义的解析逻辑兼容,或者查看如何 使用桥接进行自定义。
STRING DSL 转换器处理字符串参数List<AuthenticationEvent> result = searchSession.search( AuthenticationEvent.class )
.where( f -> f.match().field( "time" )
.matching( "2002-02-20T20:02:22", ValueModel.STRING ) )
.fetchHits( 20 );还可以使用搜索后端使用的“原始”类型,方法是将 ValueModel.RAW 传递给 DSL 步骤。
原始类型是后端和实现特定的。谨慎使用 ValueModel.RAW,并注意格式或类型本身将来可能会发生变化。 |
目前,Elasticsearch 后端 使用原始类型的 String 表示,而 Lucene 后端 使用各种类型,具体取决于如何将特定字段存储在索引中。检查 LuceneFieldCodec 的相应实现以识别类型。
RAW DSL 转换器处理原始参数Object rawDateTimeValue = // ... (1)
List<AuthenticationEvent> result = searchSession.search( AuthenticationEvent.class )
.where( f -> f.match().field( "time" )
.matching( rawDateTimeValue, ValueModel.RAW ) )
.fetchHits( 20 );| 1 | 请记住,原始值是后端特定的。 |
15.7.2. 投影值的类型
通常,投影返回的值类型应该是相当明显的:例如,如果您通过映射 Integer 属性创建了一个字段,那么在投影时将返回 Integer 值;如果您映射了 java.time.LocalDate,那么将返回 java.time.LocalDate,依此类推。
如果您开始定义和使用自定义桥接,事情会变得更加复杂。然后,您将拥有类型为 A 的属性映射到类型为 B 的索引字段。投影将返回什么?为了回答这个问题,我们需要了解投影转换器。
投影转换器是 Hibernate Search 的一项功能,它允许投影返回与索引属性类型匹配的值,而不是底层索引字段的类型。
每个自定义桥接器都有可能为它填充的索引字段定义一个投影转换器。当它这样做时,每次该字段被投影时,Hibernate Search 将使用该投影转换器来转换索引返回的投影值。
例如,让我们想象一个包含一个类型为 OrderStatus 的 status 属性的 Order 实体。此 OrderStatus 类型是一个枚举。我们索引 Order 实体及其 status 属性。
枚举的默认桥接器将 Enum.name() 的结果放入 String 字段中。但是,此默认桥接器也定义了一个投影转换器。因此,对 status 字段的任何投影都将返回一个 OrderStatus 实例。
List<OrderStatus> result = searchSession.search( Order.class )
.select( f -> f.field( "status", OrderStatus.class ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );这可能通常是你想要的。但在某些情况下,你可能想要禁用此转换并返回索引值(即 Enum.name() 的值)。
在这种情况下,我们需要告诉 Hibernate Search 后端返回的值不应传递给投影转换器。为此,可以简单地使用接受 ValueModel 参数的 field 方法的变体,并传递 ValueModel.INDEX。
List<String> result = searchSession.search( Order.class )
.select( f -> f.field( "status", String.class, ValueModel.INDEX ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );还可以通过将 ValueModel.RAW 传递给投影 DSL 步骤来请求搜索后端操作的“原始”类型。
原始类型是后端和实现特定的。谨慎使用 ValueModel.RAW,并注意格式或类型本身将来可能会发生变化。 |
目前,Elasticsearch 后端 使用原始类型的 String 表示,而 Lucene 后端 使用各种类型,具体取决于如何将特定字段存储在索引中。检查 LuceneFieldCodec 的相应实现以识别类型。
RAW 投影转换器处理原始投影Class<String> rawProjectionType = // ... (1)
List<?> result = searchSession.search( Order.class )
.select( f -> f.field( "status", rawProjectionType, ValueModel.RAW ) )
.where( f -> f.matchAll() )
.fetchHits( 20 );| 1 | 请记住,原始值是后端特定的。 |
15.7.3. 针对多个字段
有时谓词/排序/投影会针对 **多个** 字段,这些字段可能具有冲突的定义。
-
当在谓词 DSL 中的
fields方法中传递多个字段名称时(每个字段都有自己的定义); -
或者当搜索查询 针对多个索引 时(每个索引都有自己对每个字段的定义)。
在这种情况下,目标字段的定义应兼容。例如,在同一个 match 谓词中针对一个 Integer 字段和一个 java.time.LocalDate 字段将不起作用,因为你将无法传递一个既是 Integer 又是 java.time.LocalDate 的非空参数给 matching(Object) 方法。
如果你正在寻找一个简单的经验法则,那就是:如果索引属性的类型不同,或者映射方式不同,那么相应的字段可能不兼容。
但是,如果你对细节感兴趣,Hibernate Search 会比这更灵活。
在字段兼容性方面,有三个不同的约束。
-
字段必须以兼容的方式“编码”。这意味着后端必须对这两个字段使用相同的表示,例如它们都是
Integer,或者它们都是具有相同小数位数的BigDecimal,或者它们都是具有相同日期格式的LocalDate等。 -
字段必须具有兼容的 DSL 转换器(用于谓词和排序)或投影转换器(用于投影)。
-
对于全文谓词,字段必须具有兼容的分析器。
以下部分描述了所有可能的不兼容性以及如何解决它们。
不兼容的编解码器
在一个针对多个索引的搜索查询中,如果一个字段在每个索引中的编码方式不同,则你无法对该字段应用谓词、排序或投影。
编码不仅仅与字段类型有关,例如 LocalDate 或 BigDecimal。某些编解码器是参数化的,两个具有不同参数的编解码器通常被认为是不兼容的。参数示例包括时间类型的格式或 小数位数 用于 BigDecimal 和 BigInteger。 |
在这种情况下,你唯一的选择是更改你的映射以避免冲突。
-
在一个索引中重命名字段
-
或者在一个索引中更改字段类型
-
或者,如果问题仅仅是不同的编解码器参数(日期格式、小数位数等),则将一个索引中这些参数的值与另一个索引中的值对齐。
如果你选择在一个索引中重命名字段,你仍然可以在单个查询中对这两个字段应用类似的谓词:你需要为每个字段创建一个谓词,并使用 布尔连接 将它们组合起来。
不兼容的 DSL 转换器
不兼容的 DSL 转换器只在需要将参数传递给 DSL 中的某些方法时才成为问题:matching(Object)/between(Object)/atLeast(Object)/greaterThan(Object)/等在谓词 DSL 中,missing().use(Object) 在排序 DSL 中,range(Object, Object) 在聚合 DSL 中,…
如果两个以兼容方式编码的字段(例如,都作为 String),但具有不同的 DSL 转换器(例如,第一个从 String 转换为 String,但第二个从 Integer 转换为 String),你仍然可以使用这些方法,但需要禁用 DSL 转换器,如 传递给 DSL 的参数类型 中所述:你只需要将“索引”值传递给 DSL(使用相同的示例,一个 String)。
不兼容的投影转换器
如果在一个针对多个索引的搜索查询中,一个字段在每个索引中的编码方式都兼容(例如,都作为 String),但具有不同的投影转换器(例如,第一个从 String 转换为 String,但第二个从 String 转换为 Integer),你仍然可以投影到该字段上,但需要禁用投影转换器,如 投影值的类型 中所述:投影将返回“索引”,未转换的值(使用相同的示例,一个 String)。
不兼容的分析器
不兼容的分析器仅在使用全文谓词时才成为问题:对文本字段匹配谓词、短语谓词、简单查询字符串谓词等。
如果两个以兼容方式编码的字段(例如,都作为 String),但具有不同的分析器,你仍然可以使用这些谓词,但需要显式配置谓词,要么使用 .analyzer(analyzerName) 将搜索分析器设置为选择的分析器,要么使用 .skipAnalysis() 完全跳过分析。
有关如何创建谓词以及可用选项的更多信息,请参阅 谓词 DSL。
15.8. 字段路径
15.8.1. 绝对字段路径
默认情况下,传递给 Search DSL 的字段路径被解释为绝对路径,即相对于索引根目录。
路径的组件由点 (.) 分隔。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match().field( "title" ) (1)
.matching( "robot" ) )
.fetchHits( 20 );| 1 | 在索引根目录中声明的字段可以通过其名称简单引用。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.match().field( "writers.firstName" ) (1)
.matching( "isaac" ) )
.fetchHits( 20 );| 1 | 在对象字段中声明的字段(例如,由 @IndexedEmbedded 创建)必须通过其绝对路径引用:对象字段的绝对路径,后跟一个点,后跟目标字段的名称。 |
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.nested( "writers" )
.add( f.match().field( "writers.firstName" ) (1)
.matching( "isaac" ) )
.add( f.match().field( "writers.lastName" )
.matching( "asimov" ) )
)
.fetchHits( 20 );| 1 | 即使在 nested 谓词中,内部谓词中引用的字段也必须通过其绝对路径引用。 |
唯一的例外是注册在对象字段上的 命名谓词:用于构建这些谓词的工厂 **默认情况下** 将字段路径解释为相对于该对象字段。
15.8.2. 相对字段路径
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
在某些情况下,人们可能希望传递相对路径。当调用可重用方法时,这可能很有用,这些方法可以对具有相同结构(相同子字段)的不同对象字段应用相同的谓词。通过在工厂上调用 withRoot(String) 方法,可以创建一个新的工厂,该工厂将路径解释为相对于作为参数传递给方法的对象字段。
List<Book> hits = searchSession.search( Book.class )
.where( f -> f.or()
.add( f.nested( "writers" )
.add( matchFirstAndLastName( (1)
f.withRoot( "writers" ), (2)
"bob", "kane" ) ) )
.add( f.nested( "artists" )
.add( matchFirstAndLastName( (3)
f.withRoot( "artists" ), (4)
"bill", "finger" ) ) ) )
.fetchHits( 20 );| 1 | 调用可重用方法对书籍作者的姓名应用谓词。 |
| 2 | 将根目录将为对象字段 writers 的工厂传递给该方法。 |
| 3 | 调用可重用方法对书籍艺术家的姓名应用谓词。 |
| 4 | 将根目录将为对象字段 artists 的工厂传递给该方法。 |
private SearchPredicate matchFirstAndLastName(SearchPredicateFactory f,
String firstName, String lastName) {
return f.and(
f.match().field( "firstName" ) (1)
.matching( firstName ),
f.match().field( "lastName" )
.matching( lastName )
)
.toPredicate();
}| 1 | 在操作使用 withRoot 创建的工厂时,路径被解释为相对路径。在这里,firstName 将被理解为 writers.firstName 或 artists.firstName,具体取决于传递给此方法的工厂。 |
|
在构建本机构造(例如 Lucene 查询)时,即使工厂接受相对路径,你也需要处理绝对路径。 要将相对路径转换为绝对路径,请使用工厂的 |
16. 显式后端/索引操作
16.1. 将配置的分析器/规范器应用于字符串
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
Hibernate Search 提供了一个 API,它将分析器/规范器应用于给定的字符串。这对于测试这些分析器/规范器的运行方式可能很有用。
SearchMapping mapping = /* ... */ (1)
IndexManager indexManager = mapping.indexManager( "Book" ); (2)
List<? extends AnalysisToken> tokens = indexManager.analyze( (3)
"my-analyzer", (4)
"The quick brown fox jumps right over the little lazy dog" (5)
);
for ( AnalysisToken token : tokens ) { (6)
String term = token.term();
int startOffset = token.startOffset();
int endOffset = token.endOffset();
// ...
}| 1 | 检索 SearchMapping. |
| 2 | 检索 IndexManager。 |
| 3 | 执行分析。 |
| 4 | 传递 配置的分析器 的名称。 |
| 5 | 传递应执行分析的文本。 |
| 6 | 检查分析生成的标记。 |
SearchMapping mapping = /* ... */ (1)
IndexManager indexManager = mapping.indexManager( "Book" ); (2)
AnalysisToken normalizedToken = indexManager.normalize( (3)
"my-normalizer", (4)
"The quick brown fox jumps right over the little lazy dog" (5)
);
String term = normalizedToken.term(); (6)
// ...| 1 | 检索 SearchMapping. |
| 2 | 检索 IndexManager。 |
| 3 | 执行规范化。 |
| 4 | 传递 配置的规范器 的名称。 |
| 5 | 传递应应用规范器的文本。 |
| 6 | 检查规范器生成的标记。 |
|
还存在执行分析/规范化的异步版本方法: |
16.2. 显式更改整个索引
一些索引操作不是关于特定实体/文档,而是关于大量文档,可能包括所有文档。这包括例如清除索引以删除其所有内容。
这些操作通过 SearchWorkspace 接口访问,并立即执行(**在** SearchSession、Hibernate ORM 会话或事务的上下文 **之外**)。
SearchWorkspace 可以从 SearchMapping 中检索,并且可以针对一个、多个或所有索引。
SearchMapping 中检索 SearchWorkspaceSearchMapping searchMapping = /* ... */ (1)
SearchWorkspace allEntitiesWorkspace = searchMapping.scope( Object.class ).workspace(); (2)
SearchWorkspace bookWorkspace = searchMapping.scope( Book.class ).workspace(); (3)
SearchWorkspace bookAndAuthorWorkspace = searchMapping.scope( Arrays.asList( Book.class, Author.class ) )
.workspace(); (4)| 1 | 检索 SearchMapping. |
| 2 | 获取一个针对所有索引的工作区。 |
| 3 | 获取一个针对映射到 Book 实体类型的索引的工作区。 |
| 4 | 获取一个针对映射到 Book 和 Author 实体类型的索引的工作区。 |
或者,为了方便起见,SearchWorkspace 可以从 SearchSession 中检索。
SearchSession 中检索 SearchWorkspaceSearchMapping searchMapping = /* ... */ (1)
SearchWorkspace allEntitiesWorkspace = searchMapping.scope( Object.class ).workspace(); (2)
SearchWorkspace bookWorkspace = searchMapping.scope( Book.class ).workspace(); (3)
SearchWorkspace bookAndAuthorWorkspace = searchMapping.scope( Arrays.asList( Book.class, Author.class ) )
.workspace(); (4)| 1 | 检索 SearchSession. |
| 2 | 获取一个针对所有索引的工作区。 |
| 3 | 获取一个针对映射到 Book 实体类型的索引的工作区。 |
| 4 | 获取一个针对映射到 Book 和 Author 实体类型的索引的工作区。 |
SearchWorkspace 公开各种可以应用于索引或一组索引的大规模操作。这些操作将在请求时立即触发,无需等待 SearchSession 关闭或 Hibernate ORM 事务提交。
此接口提供以下方法
purge()-
从此工作区所针对的索引中删除所有文档。
如果启用了多租户,则只会删除当前租户的文档:即此工作区所来源的会话的租户。
purgeAsync()-
purge()的异步版本,返回一个CompletionStage。 purge(Set<String> routingKeys)-
从此工作区所针对的索引中删除使用给定路由键之一进行索引的文档。
如果启用了多租户,则只会删除当前租户的文档:即此工作区所来源的会话的租户。
purgeAsync(Set<String> routingKeys)-
purge(Set<String>)的异步版本,返回一个CompletionStage。 flush()-
将尚未提交的索引更改刷新到磁盘。对于具有事务日志的后端(Elasticsearch),还将应用尚未应用的事务日志中的操作。
这通常没有用,因为 Hibernate Search 会自动提交更改。有关更多信息,请参见 提交和刷新。
flushAsync()-
flush()的异步版本,返回一个CompletionStage。 refresh()-
刷新索引,以便所有到目前为止执行的更改都将在搜索查询中可见。
这通常没有用,因为索引会自动刷新。有关更多信息,请参见 提交和刷新。
refreshAsync()-
refresh()的异步版本,返回一个CompletionStage。 mergeSegments()-
将此工作区所针对的每个索引合并为单个段。此操作并不总是能提高性能:请参见 合并段和性能。
mergeSegmentsAsync()-
mergeSegments()的异步版本,返回一个CompletionStage。此操作并不总是能提高性能:请参见 合并段和性能。
|
合并段和性能
此操作会将所有索引数据重新分组到单个、巨大的段(一个文件)中。这可能会在最初提高搜索速度,但是随着文档被删除,这个巨大的段将开始充满“空洞”,这些空洞在搜索期间必须作为特殊情况进行处理,从而降低性能。 Elasticsearch/Lucene 会在某个时间点重建段来解决这个问题,但只有在达到一定比例的已删除文档时才会重建。如果所有文档都在单个、巨大的段中,则不太可能达到此比例,索引性能将持续下降很长时间。 但是,在两种情况下,合并段可能会有所帮助
|
以下示例使用 SearchWorkspace 来清除多个索引。
SearchWorkspace 清除索引SearchSession searchSession = /* ... */ (1)
SearchWorkspace workspace = searchSession.workspace( Book.class, Author.class ); (2)
workspace.purge(); (3)| 1 | 检索 SearchSession. |
| 2 | 获取一个针对映射到 Book 和 Author 实体类型的索引的工作区。 |
| 3 | 触发清除。此方法是同步的,只有在清除完成后才会返回,但也有一个异步方法 purgeAsync。 |
16.3. Lucene 特定的显式后端/索引操作
16.3.1. 通过 Lucene 特定的 Backend 检索分析器和规范器
可以在 Lucene 后端检索 在 Hibernate Search 中定义的 Lucene 分析器和规范器。
SearchMapping mapping = /* ... */ (1)
Backend backend = mapping.backend(); (2)
LuceneBackend luceneBackend = backend.unwrap( LuceneBackend.class ); (3)
Optional<? extends Analyzer> analyzer = luceneBackend.analyzer( "english" ); (4)
Optional<? extends Analyzer> normalizer = luceneBackend.normalizer( "isbn" ); (5)| 1 | 检索 SearchMapping. |
| 2 | 检索 Backend。 |
| 3 | 将后端缩小到 LuceneBackend 类型。 |
| 4 | 按名称获取分析器。该方法返回一个 Optional,如果分析器不存在,则该方法为空。分析器必须 在 Hibernate Search 中定义,否则它将不存在。 |
| 5 | 按名称获取规范器。该方法返回一个 Optional,如果规范器不存在,则该方法为空。规范器必须 在 Hibernate Search 中定义,否则它将不存在。 |
或者,您也可以检索整个索引的(复合)分析器。这些分析器对每个字段的行为有所不同,委托给映射中为每个字段配置的分析器。
SearchMapping mapping = /* ... */ (1)
IndexManager indexManager = mapping.indexManager( "Book" ); (2)
LuceneIndexManager luceneIndexManager = indexManager.unwrap( LuceneIndexManager.class ); (3)
Analyzer indexingAnalyzer = luceneIndexManager.indexingAnalyzer(); (4)
Analyzer searchAnalyzer = luceneIndexManager.searchAnalyzer(); (5)| 1 | 检索 SearchMapping. |
| 2 | 检索 IndexManager。 |
| 3 | 将索引管理器缩小到 LuceneIndexManager 类型。 |
| 4 | 获取索引分析器。这是在索引文档时使用的分析器。它会忽略 搜索分析器。 |
| 5 | 获取搜索分析器。这是通过 Search DSL 构建搜索查询时使用的分析器。与索引分析器相反,它会考虑 搜索分析器。 |
16.3.2. 检索 Lucene 的索引大小
可以从 LuceneIndexManager 中检索 Lucene 索引的大小。
SearchMapping mapping = /* ... */ (1)
IndexManager indexManager = mapping.indexManager( "Book" ); (2)
LuceneIndexManager luceneIndexManager = indexManager.unwrap( LuceneIndexManager.class ); (3)
long size = luceneIndexManager.computeSizeInBytes(); (4)
luceneIndexManager.computeSizeInBytesAsync() (5)
.thenAccept( sizeInBytes -> {
// ...
} );| 1 | 检索 SearchMapping. |
| 2 | 检索 IndexManager。 |
| 3 | 将索引管理器缩小到 LuceneIndexManager 类型。 |
| 4 | 计算索引大小并获取结果。 |
| 5 | 该方法也有一个异步版本。 |
16.3.3. 检索 Lucene IndexReader
可以从 LuceneIndexScope 中检索低级 IndexReader。
SearchMapping mapping = /* ... */ (1)
LuceneIndexScope indexScope = mapping
.scope( Book.class ).extension( LuceneExtension.get() ); (2)
try ( IndexReader indexReader = indexScope.openIndexReader() ) { (3)
// work with the low-level index reader:
numDocs = indexReader.numDocs();
}| 1 | 检索 SearchMapping. |
| 2 | 检索使用 LuceneExtension 扩展搜索范围的 LuceneIndexScope。 |
| 3 | 打开一个 IndexReader 实例。可以选择使用 openIndexReader(Set<String>) 方法提供路由键以仅针对索引的某些分片。使用完 IndexReader 后必须关闭。 |
|
即使启用了多租户,返回的阅读器也会公开 所有 租户的文档。 |
16.4. Elasticsearch 特定的显式后端/索引操作
16.4.1. 检索 REST 客户端
在编写具有高级要求的复杂应用程序时,可能有时需要直接向 Elasticsearch 集群发送请求,特别是如果 Hibernate Search 不开箱即用地支持这种请求。
为此,您可以检索 Elasticsearch 后端,然后访问 Hibernate Search 在内部使用的 Elasticsearch 客户端。请参见下面的示例。
SearchMapping mapping = /* ... */ (1)
Backend backend = mapping.backend(); (2)
ElasticsearchBackend elasticsearchBackend = backend.unwrap( ElasticsearchBackend.class ); (3)
RestClient client = elasticsearchBackend.client( RestClient.class ); (4)| 1 | 检索 SearchMapping. |
| 2 | 检索 Backend。 |
| 3 | 将后端缩小到 ElasticsearchBackend 类型。 |
| 4 | 获取客户端,将客户端的预期类型作为参数传递。 |
|
客户端本身不是 Hibernate Search API 的一部分,而是 官方 Elasticsearch REST 客户端 API 的一部分。 Hibernate Search 可能会在将来切换到具有不同 Java 类型的其他客户端,恕不另行通知。如果发生这种情况,上面的代码段将引发异常。 |
17. Lucene 后端
17.1. 基本配置
Lucene 后端的所有配置属性都是可选的,但默认值可能不适合所有人。特别是,您可能需要 设置索引在文件系统中的位置。
其他配置属性在本文档的相关部分中提到。您可以在 Lucene 后端配置属性附录 中找到可用属性的完整参考。
17.2. 索引存储 (Directory)
Lucene 中负责索引存储的组件是 org.apache.lucene.store.Directory。目录的实现决定了索引的存储位置:在文件系统上、在 JVM 的堆中等等。
默认情况下,Lucene 后端会将索引存储在文件系统上,位于 JVM 的工作目录中。
可以按如下方式配置目录类型
# To configure the defaults for all indexes:
hibernate.search.backend.directory.type = local-filesystem
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.directory.type = local-filesystem以下目录类型可用
17.2.1. 本地文件系统存储
local-filesystem 目录类型会将每个索引存储在已配置的文件系统目录的子目录中。
|
本地文件系统目录确实被设计为 本地 于一台服务器和一个应用程序。 特别是,它们不应在多个 Hibernate Search 实例之间共享。即使网络共享允许共享索引的原始内容,从多个 Hibernate Search 使用相同的索引文件也会需要更多内容:非独占锁定、从一个节点到另一个节点的写入请求路由等等。这些附加功能在 如果您需要在多个 Hibernate Search 实例之间共享索引,那么 Elasticsearch 后端将是更好的选择。有关更多信息,请参见 架构。 |
索引位置
每个索引都分配了根目录下的一个子目录。
默认情况下,根目录是 JVM 的工作目录。可以按如下方式进行配置
# To configure the defaults for all indexes:
hibernate.search.backend.directory.root = /path/to/my/root
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.directory.root = /path/to/my/root文件系统访问策略
访问文件系统的默认策略是根据操作系统和架构自动确定的。它应该在大多数情况下都能正常工作。
对于需要不同文件系统访问策略的情况,Hibernate Search 公开了一个配置属性
# To configure the defaults for all indexes:
hibernate.search.backend.directory.filesystem_access.strategy = auto
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.directory.filesystem_access.strategy = auto允许的值是
-
auto:让 Lucene 根据操作系统和架构选择最合适的实现。这是该属性的默认值。 -
mmap:使用mmap进行读取,使用FSDirectory.FSIndexOutput进行写入。参见org.apache.lucene.store.MMapDirectory。 -
nio:使用java.nio.channels.FileChannel的定位读取进行并发读取,使用FSDirectory.FSIndexOutput进行写入。参见org.apache.lucene.store.NIOFSDirectory。
|
在更改此设置之前,请务必参考这些 |
其他配置选项
local-filesystem目录还允许配置锁定策略。
17.2.2. 本地堆存储
local-heap目录类型将索引存储在本地 JVM 的堆中。
因此,包含在local-heap目录中的索引在**JVM 关闭时会丢失**。
此目录类型仅用于**测试配置**,这些配置具有**小型索引**和**低并发性**,在这种情况下,它可能会稍微提高性能。在需要更大索引和/或高并发性的设置中,基于文件系统的目录将获得更好的性能。
local-heap目录除了锁定策略之外,不提供任何特定选项。
17.2.3. 锁定策略
为了写入索引,Lucene 需要获取一个锁以确保没有其他应用程序实例同时写入同一个索引。每个目录类型都带有一个默认的锁定策略,该策略在大多数情况下应该足够好用。
对于那些(非常)罕见的情况下需要不同锁定策略的情况,Hibernate Search 公开了一个配置属性
# To configure the defaults for all indexes:
hibernate.search.backend.directory.locking.strategy = native-filesystem
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.directory.locking.strategy = native-filesystem以下策略可用
-
simple-filesystem:通过创建标记文件并在写入操作之前检查该文件来锁定索引。此实现非常简单,基于 Java 的 File API。如果应用程序因某种原因突然结束,标记文件将保留在文件系统上,需要手动删除。此策略仅适用于基于文件系统的目录。
参见
org.apache.lucene.store.SimpleFSLockFactory。 -
native-filesystem:与simple-filesystem类似,通过创建标记文件来锁定索引,但使用本机 OS 文件锁而不是 Java 的 File API,因此如果应用程序突然结束,锁将被清除。这是
local-filesystem目录类型的默认策略。此实现已知在 NFS 上存在问题:应避免在网络共享上使用它。
此策略仅适用于基于文件系统的目录。
参见
org.apache.lucene.store.NativeFSLockFactory。 -
single-instance:使用 JVM 堆中保存的 Java 对象来锁定。由于锁只能被同一个 JVM 访问,因此此策略仅在已知只有一个应用程序将尝试访问索引时才能正常工作。这是
local-heap目录类型的默认策略。参见
org.apache.lucene.store.SingleInstanceLockFactory。 -
none:不使用任何锁。来自另一个应用程序的并发写入将导致索引损坏。仔细测试您的应用程序,并确保您知道这意味着什么。参见
org.apache.lucene.store.NoLockFactory。
17.3. 分片
17.3.1. 基础
|
有关分片的初步介绍,包括它在 Hibernate Search 中的工作原理及其局限性,请参见 分片和路由。 |
在 Lucene 后端中,分片默认情况下是禁用的,但可以通过选择分片策略来启用。有多种策略可用
hash-
# To configure the defaults for all indexes: hibernate.search.backend.sharding.strategy = hash hibernate.search.backend.sharding.number_of_shards = 2 # To configure a specific index: hibernate.search.backend.indexes.<index-name>.sharding.strategy = hash hibernate.search.backend.indexes.<index-name>.sharding.number_of_shards = 2hash策略要求通过number_of_shards属性设置分片数量。此策略将设置显式配置的分片数量,从 0 到选择的数量减一(例如,对于 2 个分片,将有分片 "0" 和分片 "1")。
路由时,路由键将被哈希以将其分配给一个分片。如果路由键为 null,则将改用文档 ID。
此策略适合在映射中没有配置显式路由键的情况下,或者路由键具有大量需要减少到更小数量的可能值(例如 "所有整数")的情况下。
explicit-
# To configure the defaults for all indexes: hibernate.search.backend.sharding.strategy = explicit hibernate.search.backend.sharding.shard_identifiers = fr,en,de # To configure a specific index: hibernate.search.backend.indexes.<index-name>.sharding.strategy = explicit hibernate.search.backend.indexes.<index-name>.sharding.shard_identifiers = fr,en,deexplicit策略要求通过shard_identifiers属性设置分片标识符列表。标识符必须作为包含多个分片标识符(用逗号分隔)的字符串或包含分片标识符的Collection<String>提供。分片标识符可以是任何字符串。此策略将为每个配置的分片标识符设置一个分片。
路由时,将验证路由键以确保它与分片标识符完全匹配。如果匹配,则文档将被路由到该分片。如果不匹配,则将抛出异常。路由键不能为 null,并且文档 ID 将被忽略。
此策略适合在映射中配置了显式路由键的情况下,并且该路由键在应用程序启动之前具有有限数量的已知可能值。
17.3.2. 每个分片的配置
在某些情况下,特别是在使用explicit分片策略时,可能需要以略微不同的方式配置一些分片。例如,其中一个分片可能包含海量但很少访问的数据,这些数据应该存储在不同的驱动器上。
这可以通过为特定分片添加配置属性来实现
# Default configuration for all shards an index:
hibernate.search.backend.indexes.<index-name>.directory.root = /path/to/fast/drive/
# Configuration for a specific shard:
hibernate.search.backend.indexes.<index-name>.shards.<shard-identifier>.directory.root = /path/to/large/drive/有效的分片标识符取决于分片策略
17.4. 索引格式兼容性
虽然 Hibernate Search 努力提供向后兼容的 API,使其易于将您的应用程序移植到更新的版本,但它仍然委托给 Apache Lucene 来处理索引写入和搜索。这会创建一个对 Lucene 索引格式的依赖。Lucene 开发人员当然试图保持稳定的索引格式,但有时无法避免格式的更改。在这种情况下,您要么必须重新索引所有数据,要么使用索引升级工具。有时,Lucene 也可以读取旧格式,因此您不需要采取任何特定操作(除了备份索引)。
虽然索引格式不兼容是一个罕见的事件,但 Lucene 的 Analyzer 实现可能比索引格式不兼容更频繁地改变其行为。这会导致某些文档不再匹配,即使它们以前匹配过。
为了避免这种分析器不兼容,Hibernate Search 允许配置分析器和其他 Lucene 类应该使其行为符合哪个版本的 Lucene。
此配置属性是在后端级别设置的
hibernate.search.backend.lucene_version = LUCENE_8_1_1根据您使用的 Lucene 的具体版本,您可能会有不同的选项可用:参见lucene-core.jar中包含的org.apache.lucene.util.Version以获取允许值的列表。
当未设置此选项时,Hibernate Search 将指示 Lucene 使用最新版本,这通常是新项目的最佳选择。尽管如此,建议在配置中明确定义您使用的版本,这样当您碰巧升级时,Lucene 分析器的行为就不会改变。然后,您可以选择在以后更新此值,例如,当您有机会从头开始重建索引时。
|
在使用 Hibernate Search API 时,该设置将始终生效,但如果您也通过绕过 Hibernate Search 使用 Lucene(例如,在您自己实例化 Analyzer 时),请确保使用相同的值。 |
|
有关可以升级到哪些版本的 Hibernate Search 以及如何与给定版本的 Lucene API 保持向后兼容的信息,请参阅兼容性策略。 |
17.5. 架构
Lucene 实际上没有一个集中式架构的概念来指定每个字段的数据类型和功能,但 Hibernate Search 在内存中维护了这样一个架构,以便记住可以对每个字段应用哪些谓词/投影/排序。
在大多数情况下,架构是从通过 Hibernate Search 的映射 API 配置的映射推断出来的,这些 API 是通用的,与 Lucene 无关。
本节介绍了特定于 Lucene 后端的方面。
17.5.1. 字段类型
可用的字段类型
|
某些类型不受 Lucene 后端直接支持,但无论如何都能正常工作,因为它们被映射器 "桥接" 了。例如,实体模型中的 |
|
不在此列表中的字段类型仍然可以使用,但需要做更多工作
|
| 字段类型 | 限制 |
|---|---|
java.lang.String |
- |
java.lang.Byte |
- |
java.lang.Short |
- |
java.lang.Integer |
- |
java.lang.Long |
- |
java.lang.Double |
- |
java.lang.Float |
- |
java.lang.Boolean |
- |
java.math.BigDecimal |
- |
java.math.BigInteger |
- |
java.time.Instant |
|
java.time.LocalDate |
|
java.time.LocalTime |
|
java.time.LocalDateTime |
|
java.time.ZonedDateTime |
|
java.time.OffsetDateTime |
|
java.time.OffsetTime |
|
java.time.Year |
|
java.time.YearMonth |
|
java.time.MonthDay |
- |
org.hibernate.search.<wbr>engine.<wbr>spatial.<wbr>GeoPoint |
|
日期/时间字段的范围和分辨率
日期/时间类型不支持
超出范围的值将导致索引失败。 时间类型的精度也较低。
索引时将丢失毫秒级精度之外的精度。 |
GeoPoint 字段的范围和精度
这实际上意味着索引的点在最坏情况下可能会偏离大约 13 厘米 (5.2 英寸)。 |
索引字段类型 DSL 扩展
并非所有 Lucene 字段类型在 Hibernate Search 中都有内置支持。但是,仍然可以通过利用“native”字段类型来使用不受支持的字段类型。使用此字段类型,可以直接创建 Lucene IndexableField 实例,从而访问 Lucene 提供的所有功能。
以下是如何使用 Lucene“native”类型的示例。
public class PageRankValueBinder implements ValueBinder { (1)
@Override
public void bind(ValueBindingContext<?> context) {
context.bridge(
Float.class,
new PageRankValueBridge(),
context.typeFactory() (2)
.extension( LuceneExtension.get() ) (3)
.asNative( (4)
Float.class, (5)
(absoluteFieldPath, value, collector) -> { (6)
collector.accept( new FeatureField( absoluteFieldPath, "pageRank", value ) );
collector.accept( new StoredField( absoluteFieldPath, value ) );
},
field -> (Float) field.numericValue() (7)
)
);
}
private static class PageRankValueBridge implements ValueBridge<Float, Float> {
@Override
public Float toIndexedValue(Float value, ValueBridgeToIndexedValueContext context) {
return value; (8)
}
@Override
public Float fromIndexedValue(Float value, ValueBridgeFromIndexedValueContext context) {
return value; (8)
}
}
}| 1 | 定义一个 自定义绑定器 及其桥接。 “native”类型只能从绑定器中使用,不能直接与注释映射一起使用。这里我们定义了一个 值绑定器,但 类型绑定器 或 属性绑定器 也可以使用。 |
| 2 | 获取上下文的类型工厂。 |
| 3 | 将 Lucene 扩展应用于类型工厂。 |
| 4 | 调用 asNative 开始定义本地类型。 |
| 5 | 定义字段值类型。 |
| 6 | 定义 LuceneFieldContributor。在索引时将调用贡献者,以向文档添加必要的字段。所有字段都必须以传递给贡献者的 absoluteFieldPath 命名。 |
| 7 | 如果需要投影,则可以选择定义 LuceneFieldValueExtractor。在投影时将调用提取器,以从 **单个** 存储字段中提取投影的值。 |
| 8 | 值桥接器可以在将值传递给 Hibernate Search 之前应用预处理转换,Hibernate Search 将将其传递给 LuceneFieldContributor。 |
@Entity
@Indexed
public class WebPage {
@Id
private Integer id;
@NonStandardField( (1)
valueBinder = @ValueBinderRef(type = PageRankValueBinder.class) (2)
)
private Float pageRank;
// Getters and setters
// ...
}| 1 | 将属性映射到索引字段。请注意,使用非标准字段类型 (如 Lucene 的“native”类型) 的值桥接器必须使用 @NonStandardField 注释进行映射:其他注释 (如 @GenericField) 将失败。 |
| 2 | 指示 Hibernate Search 使用我们自定义的值绑定器。 |
17.5.2. 多租户
多租户支持并且根据当前会话中定义的租户 ID 透明地处理。
-
文档将使用适当的值进行索引,以便以后进行过滤;
-
查询将适当地过滤结果。
如果在映射器中启用了多租户,则后端会自动启用多租户,例如,如果 在 Hibernate ORM 中选择了多租户策略,或者如果 在独立 POJO 映射器中显式配置了多租户。
但是,可以手动启用多租户。
多租户策略是在后端级别设置的。
hibernate.search.backend.multi_tenancy.strategy = none有关可用策略的详细信息,请参见以下小节。
17.6. 分析
17.6.1. 基本知识
分析 是分析器执行的文本处理,包括索引时 (文档处理) 和搜索时 (查询处理)。
Lucene 后端带有一些 默认分析器,但分析也可以显式配置。
要在 Lucene 后端中配置分析,您需要
-
定义一个实现
org.hibernate.search.backend.lucene.analysis.LuceneAnalysisConfigurer接口的类。 -
通过将配置属性
hibernate.search.backend.analysis.configurer设置为指向实现的 bean 引用 来配置后端,例如class:com.mycompany.MyAnalysisConfigurer。
| 您可以传递多个以逗号分隔的 bean 引用。请参阅 配置属性的类型。 |
17.6.2. 内置分析器
内置分析器开箱即用,无需显式配置。如有必要,可以通过定义具有相同名称的自定义分析器来覆盖它们。
Lucene 后端提供了一系列内置分析器;它们的名称在 org.hibernate.search.engine.backend.analysis.AnalyzerNames 中列为常量。
default-
默认情况下,
@FullTextField使用的分析器。默认实现:
org.apache.lucene.analysis.standard.StandardAnalyzer。默认行为:首先,使用标准分词器进行分词,该分词器遵循 Unicode 文本分段算法中的词语分隔规则,如 Unicode 标准附件 #29 中所述。然后,将每个词语转换为小写。
standard-
默认实现:
org.apache.lucene.analysis.standard.StandardAnalyzer。默认行为:首先,使用标准分词器进行分词,该分词器遵循 Unicode 文本分段算法中的词语分隔规则,如 Unicode 标准附件 #29 中所述。然后,将每个词语转换为小写。
simple-
默认实现:
org.apache.lucene.analysis.core.SimpleAnalyzer。默认行为:首先,在非字母字符处分割文本。然后,将每个词语转换为小写。
whitespace-
默认实现:
org.apache.lucene.analysis.core.WhitespaceAnalyzer。默认行为:在空格字符处分割文本。不要更改词语。
stop-
默认实现:
org.apache.lucene.analysis.core.StopAnalyzer。默认行为:首先,在非字母字符处分割文本。然后,将每个词语转换为小写。最后,删除英语停用词。
keyword-
默认实现:
org.apache.lucene.analysis.core.KeywordAnalyzer。默认行为:不要以任何方式更改文本。
使用此分析器,全文字段的行为类似于关键字字段,但功能更少:例如,没有术语聚合。
建议改用
@KeywordField。
17.6.4. 自定义分析器和规范器
按名称引用组件
传递给配置器的上下文公开了用于定义分析器和规范器的 DSL。
package org.hibernate.search.documentation.analysis;
import org.hibernate.search.backend.lucene.analysis.LuceneAnalysisConfigurationContext;
import org.hibernate.search.backend.lucene.analysis.LuceneAnalysisConfigurer;
public class MyLuceneAnalysisConfigurer implements LuceneAnalysisConfigurer {
@Override
public void configure(LuceneAnalysisConfigurationContext context) {
context.analyzer( "english" ).custom() (1)
.tokenizer( "standard" ) (2)
.charFilter( "htmlStrip" ) (3)
.tokenFilter( "lowercase" ) (4)
.tokenFilter( "snowballPorter" ) (4)
.param( "language", "English" ) (5)
.tokenFilter( "asciiFolding" );
context.normalizer( "lowercase" ).custom() (6)
.tokenFilter( "lowercase" )
.tokenFilter( "asciiFolding" );
context.analyzer( "french" ).custom() (7)
.tokenizer( "standard" )
.charFilter( "htmlStrip" )
.tokenFilter( "lowercase" )
.tokenFilter( "snowballPorter" )
.param( "language", "French" )
.tokenFilter( "asciiFolding" );
}
}| 1 | 定义一个名为“english”的自定义分析器,因为它将用于分析英语文本,例如书籍标题。 |
| 2 | 将分词器设置为标准分词器:按名称引用组件。 |
| 3 | 设置字符过滤器。字符过滤器按照给定的顺序应用,在分词器之前应用。 |
| 4 | 设置词语过滤器。词语过滤器按照给定的顺序应用,在分词器之后应用。 |
| 5 | 设置最后一个添加的字符过滤器/分词器/词语过滤器的参数值。 |
| 6 | 规范器的定义方式类似,唯一的区别是它们不能使用分词器。 |
| 7 | 可以在同一个配置器中定义多个分析器/规范器。 |
(1)
hibernate.search.backend.analysis.configurer = class:org.hibernate.search.documentation.analysis.MyLuceneAnalysisConfigurer| 1 | 使用 Hibernate Search 配置属性将配置器分配给后端。 |
要了解哪些字符过滤器、分词器和词语过滤器可用,可以调用传递给分析配置器的上下文中的 context.availableTokenizers()、context.availableTokenizers() 和 context.availableTokenFilters();这将返回所有有效名称的集合。
要详细了解这些字符过滤器、分词器和词语过滤器的行为,请浏览 Lucene Javadoc,特别是查看 常见分析组件 的各个包,或者阅读 Solr Wiki 上的相应部分 (您不需要 Solr 即可使用这些分析器,只是 Lucene 自身没有文档页面)。
|
在 Lucene Javadoc 中,每个工厂类的描述都包含“SPI 名称”后跟一个字符串常量。这是在定义分析器时应传递以使用该工厂的名称。 |
按工厂类引用组件
除了名称之外,您还可以传递 Lucene 工厂类来引用特定的分词器、字符过滤器或词语过滤器实现。这些类扩展了 org.apache.lucene.analysis.TokenizerFactory、org.apache.lucene.analysis.TokenFilterFactory 或 org.apache.lucene.analysis.CharFilterFactory。
这避免了代码中的字符串常量,但需要直接对 Lucene 进行编译时依赖。
context.analyzer( "english" ).custom()
.tokenizer( StandardTokenizerFactory.class )
.charFilter( HTMLStripCharFilterFactory.class )
.tokenFilter( LowerCaseFilterFactory.class )
.tokenFilter( SnowballPorterFilterFactory.class )
.param( "language", "English" )
.tokenFilter( ASCIIFoldingFilterFactory.class );
context.normalizer( "lowercase" ).custom()
.tokenFilter( LowerCaseFilterFactory.class )
.tokenFilter( ASCIIFoldingFilterFactory.class );要了解哪些字符过滤器、分词器和词语过滤器可用,请浏览 Lucene Javadoc,特别是查看 常见分析组件 的各个包,或者阅读 Solr Wiki 上的相应部分 (您不需要 Solr 即可使用这些分析器,只是 Lucene 自身没有文档页面)。
17.6.5. 覆盖默认分析器
在没有显式指定分析器的情况下使用 @FullTextField 时的默认分析器名为 default。
package org.hibernate.search.documentation.analysis;
import org.hibernate.search.backend.lucene.analysis.LuceneAnalysisConfigurationContext;
import org.hibernate.search.backend.lucene.analysis.LuceneAnalysisConfigurer;
import org.hibernate.search.engine.backend.analysis.AnalyzerNames;
public class DefaultOverridingLuceneAnalysisConfigurer implements LuceneAnalysisConfigurer {
@Override
public void configure(LuceneAnalysisConfigurationContext context) {
context.analyzer( AnalyzerNames.DEFAULT ) (1)
.custom() (2)
.tokenizer( "standard" )
.tokenFilter( "lowercase" )
.tokenFilter( "snowballPorter" )
.param( "language", "French" )
.tokenFilter( "asciiFolding" );
}
}| 1 | 开始定义一个名为 default 的自定义分析器。这里我们依赖 org.hibernate.search.engine.backend.analysis.AnalyzerNames 中的常量来使用正确的名称,但硬编码 "default" 也可以正常工作。 |
| 2 | 继续 像对任何其他自定义分析器一样 定义分析器。 |
(1)
hibernate.search.backend.analysis.configurer = class:org.hibernate.search.documentation.analysis.DefaultOverridingLuceneAnalysisConfigurer| 1 | 使用 Hibernate Search 配置属性将配置器分配给后端。 |
17.6.6. 相似度
在搜索时,会根据索引时间记录的统计信息,使用特定公式为文档分配分数。这些统计信息和公式由称为相似度的单个组件定义,该组件实现了 Lucene 的 `org.apache.lucene.search.similarities.Similarity` 接口。
默认情况下,Hibernate Search 使用 `BM25Similarity` 及其默认参数(`k1 = 1.2`,`b = 0.75`)。这在大多数情况下应该提供令人满意的评分。
如果您有更高级的需求,可以在您的分析配置器中设置自定义 `Similarity`,如下所示。
|
请记住还要从您的配置属性中引用分析配置器,如 自定义分析器和规范器 中所述。 |
public class CustomSimilarityLuceneAnalysisConfigurer implements LuceneAnalysisConfigurer {
@Override
public void configure(LuceneAnalysisConfigurationContext context) {
context.similarity( new ClassicSimilarity() ); (1)
context.analyzer( "english" ).custom() (2)
.tokenizer( "standard" )
.tokenFilter( "lowercase" )
.tokenFilter( "asciiFolding" );
}
}| 1 | 将相似度设置为 `ClassicSimilarity`。 |
| 2 | 像往常一样定义分析器和规范器。 |
|
有关 `Similarity`、其各种实现以及每种实现的优缺点的更多信息,请参阅 `Similarity` 的 javadoc 和 Lucene 的源代码。 您还可以在网上找到有用的资源,例如 Elasticsearch 的文档。 |
17.7. 线程
Lucene 后端依赖于内部线程池来执行对索引的写入操作。
默认情况下,池包含与启动时 JVM 可用的处理器数量完全相同的线程。可以使用配置属性更改此设置
hibernate.search.backend.thread_pool.size = 4|
此数字是 *每个后端*,而不是 *每个索引*。添加更多索引不会添加更多线程。 |
|
在此线程池中发生的运算包括阻塞 I/O,因此将大小提高到 JVM 可用的处理器核心数以上可能是合理的,并且可能会提高性能。 |
17.8. 索引队列
在 Hibernate Search 对索引执行的所有写入操作中,预计会有很多“索引”操作来创建/更新/删除特定文档。我们通常希望在这些请求涉及相同文档时保留它们的相对顺序。
为此,Hibernate Search 将这些操作推送到内部队列中,并以批处理方式应用它们。每个索引维护 10 个队列,每个队列最多可容纳 1000 个元素。队列独立运行(并行),但每个队列一个接一个地应用一个操作,因此在任何给定时间,每个索引最多可以应用 10 批索引请求。
|
相对于相同文档 ID 的索引操作始终被推送到同一个队列。 |
可以自定义队列以减少资源消耗,或者相反,以提高吞吐量。这可以通过以下配置属性来完成
# To configure the defaults for all indexes:
hibernate.search.backend.indexing.queue_count = 10
hibernate.search.backend.indexing.queue_size = 1000
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.indexing.queue_count = 10
hibernate.search.backend.indexes.<index-name>.indexing.queue_size = 1000|
当队列已满时,任何尝试请求索引的操作都会阻塞,直到请求可以放入队列中。 为了获得合理的性能水平,请确保将队列的大小设置为足够大的数字,以便这种阻塞仅在应用程序承受非常高的负载时才会发生。 |
|
当 分片 启用时,每个分片将被分配自己的队列集。 如果您使用 基于文档 ID(而不是基于提供的路由键)的 `hash` 分片策略,请确保将队列的数量设置为与分片数量没有公因数的数字;否则,一些队列的使用率可能远远低于其他队列。 例如,如果您将分片的数量设置为 8,将队列的数量设置为 4,则最终落在分片 #0 中的文档将始终最终落在该分片的队列 #0 中。这是因为将路由到分片和将路由到队列都对文档 ID 的哈希值执行模运算,并且 `<some hash> % 8 == 0`(路由到分片 #0)意味着 `<some hash> % 4 == 0`(路由到分片 #0 的队列 #0)。同样,只有当您依赖文档 ID 而不是提供的路由键进行分片时,这才是正确的。 |
17.9. 写入和读取
17.9.1. 提交
|
有关在 Hibernate Search 中写入和读取索引的初步介绍,特别是包括 *提交* 和 *刷新* 的概念,请参见 提交和刷新。 |
在 Lucene 术语中,*提交* 是将索引写入器中缓冲的更改推送到索引本身,因此崩溃或断电不会导致数据丢失。
一些操作至关重要,并且始终在被认为已完成之前提交。对于由 监听器触发的索引 触发的更改(除非 配置为其他方式),以及对于大规模操作(例如 清除)来说,情况就是这样。当遇到此类操作时,将立即执行提交,保证操作只有在所有更改安全地存储在磁盘上之后才被认为已完成。
但是,其他操作,例如由 批量索引器 贡献的更改,或者当 索引 使用 `async` 同步策略 时,预计不会立即提交。
从性能方面来看,提交可能是一个昂贵的操作,这就是为什么 Hibernate Search 尽量不经常提交的原因。默认情况下,当将不需要立即提交的更改应用于索引时,Hibernate Search 会将提交延迟一秒。如果在那一秒钟内应用了其他更改,它们将包含在同一个提交中。这在写入密集型场景(例如 批量索引)中显著减少了提交量,从而导致更好的性能。
可以通过设置提交间隔(以毫秒为单位)来控制 Hibernate Search 提交的频率。
# To configure the defaults for all indexes:
hibernate.search.backend.io.commit_interval = 1000
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.io.commit_interval = 1000此属性的默认值为 `1000`。
|
将提交间隔设置为 0 将强制 Hibernate Search 在每批更改之后提交,这可能会导致吞吐量大幅降低,尤其是对于 显式或监听器触发的索引,但对于 批量索引 更是如此。 |
|
请记住,单个写入操作可能会强制提交,这可能会抵消设置较高提交间隔带来的潜在性能提升。 默认情况下,提交间隔可能只提高 批量索引器 的吞吐量。如果您希望 显式或由监听器触发的 更改也从中受益,则需要选择非默认的 同步策略,这样就不需要在每次更改后都提交。 |
17.9.2. 刷新
|
有关在 Hibernate Search 中写入和读取索引的初步介绍,特别是包括 *提交* 和 *刷新* 的概念,请参见 提交和刷新。 |
在 Lucene 术语中,*刷新* 是打开一个新的索引读取器,以便接下来的搜索查询将考虑对索引的最新更改。
从性能方面来看,刷新可能是一个昂贵的操作,这就是为什么 Hibernate Search 尽量不经常刷新。索引读取器在每次搜索查询时都会刷新,但前提是在上次刷新后发生了写入操作。
在写入密集型场景中,在每次写入后刷新仍然太频繁,可以通过以毫秒为单位设置刷新间隔来降低刷新频率,从而提高读取吞吐量。当设置为大于 0 的值时,索引读取器将不再在每次搜索查询时刷新:如果在搜索查询开始时,刷新发生在 X 毫秒之前,那么即使索引读取器可能已过期,也不会刷新。
可以这样设置刷新间隔
# To configure the defaults for all indexes:
hibernate.search.backend.io.refresh_interval = 0
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.io.refresh_interval = 0此属性的默认值为 `0`。
17.9.3. `IndexWriter` 设置
Lucene 的 `IndexWriter`(Hibernate Search 用来写入索引)公开了几个可以调整以更好地适应您的应用程序并最终获得更好性能的设置。
Hibernate Search 通过以 `io.writer.` 为前缀的配置属性(在索引级别)公开这些设置。
以下是所有索引写入器设置的列表。它们都可以在配置属性中以类似的方式设置;例如,`io.writer.ram_buffer_size` 可以这样设置
# To configure the defaults for all indexes:
hibernate.search.backend.io.writer.ram_buffer_size = 32
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.io.writer.ram_buffer_size = 32| 属性 | 描述 |
|---|---|
|
可以在内存中缓冲的最大文档数,在它们被刷新到 Directory 之前。 较大的值意味着更快的索引速度,但内存使用量更多。 当与 `ram_buffer_size` 一起使用时,会根据先发生的事件进行刷新。 |
|
在将添加的文档和删除操作刷新到 Directory 之前,可以用于缓冲它们的内存量。 较大的值意味着更快的索引速度,但内存使用量更多。 通常,为了获得更快的索引性能,最好使用此设置而不是 `max_buffered_docs`。 当与 `max_buffered_docs` 一起使用时,会根据先发生的事件进行刷新。 |
启用有关 Lucene 内部组件的低级别跟踪信息;`true` 或 `false`。 日志将以 `TRACE` 级别追加到 这可能会导致性能大幅下降,即使日志记录器忽略了 TRACE 级别,因此这应该只用于故障排除目的。 默认情况下禁用。 |
|
有关设置及其默认值的更多信息,请参阅 Lucene 的文档,特别是 `IndexWriterConfig` 的 javadoc 和源代码。 |
17.9.4. 合并设置
Lucene 索引不是存储在一个单一的连续文件中。相反,每次刷新索引都会生成一个包含添加到索引中的所有文档的小文件。该文件被称为“段”。在具有太多段的索引上进行搜索可能更慢,因此 Lucene 会定期合并小的段以创建更少的、更大的段。
Lucene 的合并行为由 `MergePolicy` 控制。Hibernate Search 使用 `LogByteSizeMergePolicy`,它公开了几个可以调整以更好地适应您的应用程序并最终获得更好性能的设置。
以下是所有合并设置的列表。它们都可以在配置属性中以类似的方式设置;例如,`io.merge.factor` 可以这样设置
# To configure the defaults for all indexes:
hibernate.search.backend.io.merge.factor = 10
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.io.merge.factor = 10| 属性 | 描述 |
|---|---|
|
段可以具有的最大文档数,在合并之前。具有超过此数量文档的段将不会被合并。 较小的值在经常更改的索引上表现更好,较大的值在索引不经常更改时提供更好的搜索性能。 |
|
一次合并的段数。 当使用较小的值时,合并操作会更频繁,因此会消耗更多资源,但平均而言,段的总数会更少,从而提高读取性能。因此,较大的值( 该值不能低于 |
|
背景合并的段的最小目标大小(以 MB 为单位)。 小于此大小的段将被更积极地合并。 将此值设置得太大会导致昂贵的合并操作,即使这些操作不太频繁。 |
|
背景合并的段的最大大小(以 MB 为单位)。 大于此大小的段永远不会在背景中合并。 将此值设置为较低的值有助于减少内存需求,并避免一些合并操作,但会以牺牲最佳搜索速度为代价。 当 强制合并索引时,此值将被忽略,而是使用 |
|
强制合并的段的最大大小(以 MB 为单位)。 这相当于 强制合并 的 |
|
是否应考虑索引中已删除的文档数量; 启用后,Lucene 将认为包含 100 个文档(其中 50 个已删除)的段实际上包含 50 个文档。禁用后,Lucene 将认为这样的段包含 100 个文档。 将 |
|
有关这些设置及其默认值的更多信息,请参阅 Lucene 文档,特别是 |
|
选项 首先,请注意合并段是指将其与另一个现有段合并在一起,形成一个更大的段。 其次,合并选项不会影响索引写入器最初创建的段的大小(在它们被合并之前)。此大小可以通过设置 因此,例如,为了确保没有文件的大小超过 15MB,可以使用以下设置 |
17.10. 搜索
使用 Lucene 后端进行搜索依赖于 与任何其他后端相同的 API。
本节详细介绍了与搜索相关的 Lucene 特定配置。
17.10.1. 低级命中缓存
|
此功能意味着应用程序代码直接依赖 Lucene API。 即使是针对错误修复(微型)版本的 Hibernate Search 升级也可能需要升级 Lucene,这可能会导致 Lucene 的 API 发生重大更改。 如果发生这种情况,您需要更改应用程序代码以处理这些更改。 |
Lucene 支持缓存低级命中,即在给定索引段中缓存与给定 org.apache.lucene.search.Query 匹配的文档列表。
此缓存在读密集型场景中很有用,在这种场景中,同一个查询经常在同一个索引上执行,并且索引很少写入。
| 这与 Hibernate ORM 缓存不同,Hibernate ORM 缓存缓存实体的内容或**数据库**查询的结果。Hibernate ORM 缓存也可以在 Hibernate Search 中使用,但通过不同的 API:请参见 缓存查找策略。 |
要在 Lucene 后端中配置缓存,您需要
-
定义一个实现
org.hibernate.search.backend.lucene.cache.QueryCachingConfigurer接口的类。 -
通过将配置属性
hibernate.search.backend.query.caching.configurer设置为指向实现的 bean 引用(例如class:com.mycompany.MyQueryCachingConfigurer)来配置后端以使用该实现。
| 您可以传递多个以逗号分隔的 bean 引用。请参阅 配置属性的类型。 |
Hibernate Search 将在启动时调用此实现的 configure 方法,配置器将能够利用 DSL 来定义 org.apache.lucene.search.QueryCache 和 org.apache.lucene.search.QueryCachingPolicy。
18. Elasticsearch 后端
18.1. 兼容性
18.1.1. 概述
Hibernate Search 的 Elasticsearch 后端与多个 Elasticsearch 发行版兼容
|
有关 Hibernate Search 的哪些版本与给定版本的 Elasticsearch/OpenSearch 兼容的信息,请参阅 兼容性矩阵。 有关可以预期 Hibernate Search 的哪些未来版本将保持与当前兼容的 Elasticsearch/OpenSearch 版本兼容的信息,请参阅 兼容性策略。 |
在可能的情况下,集群上运行的发行版和版本将在启动时自动检测到,Hibernate Search 将根据此信息进行调整。
使用 Amazon OpenSearch Serverless 或当您的集群在启动时不可用时,您将需要显式地配置 Hibernate Search 应该预期的版本:有关详细信息,请参见 版本兼容性。
目标版本对 Hibernate Search 用户来说基本上是透明的,但 Hibernate Search 的行为根据 Elasticsearch 发行版和版本的不同而有所不同,这可能会影响您。以下部分详细介绍了这些差异。
18.1.2. Elasticsearch
Hibernate Search 的 Elasticsearch 后端与运行版本 7.10+ 或 8.x 的 Elasticsearch 集群兼容,并定期针对版本 7.10、7.17 或 8.15 进行测试。
目前使用 Elasticsearch 不需要特定配置,也不意味着特定限制。
18.1.3. OpenSearch
Hibernate Search 的 Elasticsearch 后端与运行版本 1.3 或 2.x 的 OpenSearch 集群兼容,并定期针对版本 1.3 或 2.16 进行测试。
18.1.4. Amazon OpenSearch Service
Hibernate Search 的 Elasticsearch 后端与 Amazon OpenSearch Service 兼容,并定期针对主要版本进行测试。
使用 Amazon OpenSearch Service 需要 专有身份验证,这需要额外的配置。
使用 Amazon OpenSearch Service 意味着一个限制:在运行 Elasticsearch(而不是 OpenSearch)且仅在版本 7.1 或更早版本中,关闭索引是不可能的,因此 自动模式更新(不建议在生产环境中使用)在尝试更新分析器定义时会失败。
18.1.5. Amazon OpenSearch Serverless(孵化阶段)
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
Amazon OpenSearch Serverless 的兼容性已实现,并且处于孵化阶段;请随时在 HSEARCH-4867 上提供反馈。
但是,请注意
-
Hibernate Search 目前没有针对 Amazon OpenSearch Serverless 进行测试;请参见 HSEARCH-4919。
-
连接到 Amazon OpenSearch Serverless 集群需要 专有身份验证,这需要额外的配置。
-
必须通过 将
hibernate.search.backend.version设置为amazon-opensearch-serverless来显式启用与 Amazon OpenSearch Serverless 的兼容性。
此外,Amazon OpenSearch Serverless 有其自身特定的限制
-
启动时检测发行版/版本 是不可能的,因此它默认情况下处于禁用状态,并且无法显式启用。
-
模式管理的最小索引状态要求 是不可能的,因此它默认情况下处于禁用状态,并且无法显式启用。
-
如果您尝试在启动时进行清除(默认设置),则 大规模索引器 将失败,因为 Amazon OpenSearch Serverless 不支持它。请使用
.dropAndCreateSchemaOnStart(…)来代替在启动时删除索引。请参见 HSEARCH-4930。 -
大规模索引器 默认情况下将跳过刷新、刷新和合并段操作,尝试显式启用它们会导致失败,因为 Amazon OpenSearch Serverless 不支持它们。
-
目前不支持 Jakarta Batch 集成。请参见 HSEARCH-4929、HSEARCH-4930。
18.2. 基本配置
Elasticsearch 后端的所有配置属性都是可选的,但默认值可能不适合所有人。特别是,您的生产 Elasticsearch 集群可能无法在 https://:9200 上访问,因此您需要通过 配置客户端 来设置集群的地址。
配置属性在本手册的相关部分中提及。您可以在 Elasticsearch 后端配置属性附录 中找到可用属性的完整参考。
18.3. Elasticsearch 集群的配置
大多数情况下,Hibernate Search 不需要对 Elasticsearch 集群进行任何手动配置,除了索引映射(模式)以外,可以自动生成。
唯一的例外是 分片,需要显式启用。
18.4. 客户端配置
Elasticsearch 后端通过 REST 客户端与 Elasticsearch 集群通信。以下是影响此客户端的选项。
18.4.1. 目标主机
以下属性配置将索引请求和搜索查询发送到的 Elasticsearch 主机(或主机)。
hibernate.search.backend.hosts = localhost:9200此属性的默认值为 localhost:9200。
此属性可以设置为表示主机和端口的字符串,例如 localhost 或 es.mycompany.com:4400,或包含多个此类主机和端口字符串(用逗号分隔)的字符串,或包含此类主机和端口字符串的 Collection<String>。
您可以使用此配置属性更改用于与主机通信的协议。
hibernate.search.backend.protocol = http此属性的默认值为 http。
此属性可以设置为 http 或 https。
或者,可以使用单个属性定义协议和主机,作为一个或多个 URI。
hibernate.search.backend.uris = https://:9200此属性可以设置为表示 URI 的字符串,例如 https:// 或 https://es.mycompany.com:4400,或包含多个此类 URI 字符串(用逗号分隔)的字符串,或包含此类 URI 字符串的 Collection<String>。
|
使用此属性有一些限制。
|
18.4.2. 路径前缀
默认情况下,预期 REST API 可用于根路径 (/)。例如,针对所有索引的搜索查询将发送到路径 /_search。这是标准 Elasticsearch 设置所需的设置。
如果您的设置是非标准的,例如由于应用程序和 Elasticsearch 集群之间存在非透明代理,您可以使用类似于此的配置。
hibernate.search.backend.path_prefix = my/path使用上述配置,针对所有索引的搜索查询将发送到路径 /my/path/_search 而不是 /_search。对于发送到 Elasticsearch 的所有请求,路径将以类似的方式添加前缀。
18.4.3. 节点发现
使用自动发现时,Elasticsearch 客户端将定期探测集群中的新节点,并将这些节点添加到主机列表中(请参阅 客户端配置 中的 hosts)。
以下属性控制自动发现。
hibernate.search.backend.discovery.enabled = false
hibernate.search.backend.discovery.refresh_interval = 10-
discovery.enabled定义是否启用此功能。期望一个布尔值。此属性的默认值为false。 -
discovery.refresh_interval定义两次执行自动发现之间的间隔。期望一个正整数(以秒为单位)。此属性的默认值为10。
18.4.4. HTTP 身份验证
HTTP 身份验证默认情况下处于禁用状态,但可以通过设置以下配置属性来启用。
hibernate.search.backend.username = ironman
hibernate.search.backend.password = j@rv1s这些属性的默认值为一个空字符串。
连接到 Elasticsearch 服务器时发送的用户名和密码。
|
如果您使用 HTTP 而不是 HTTPS(如上所述),您的密码将在网络上以明文形式传输。 |
18.4.5. Amazon Web Services 上的身份验证
Hibernate Search Elasticsearch 后端在配置后,在大多数设置中都能正常工作。但是,如果您需要使用 Amazon OpenSearch Service 或 Amazon OpenSearch Serverless,您会发现它们需要一种专有的身份验证方法:请求签名。
虽然请求签名默认情况下不受支持,但您可以使用其他依赖项和一些配置来启用它。
您需要添加此依赖项。
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-backend-elasticsearch-aws</artifactId>
<version>7.2.0.Final</version>
</dependency>在您的类路径中添加该依赖项后,您仍然需要对其进行配置。
以下配置是强制性的。
hibernate.search.backend.aws.signing.enabled = true
hibernate.search.backend.aws.region = us-east-1-
aws.signing.enabled定义是否启用请求签名。期望一个布尔值。默认为false。 -
aws.region定义 AWS 区域。期望一个字符串值。此属性没有默认值,必须提供该属性才能使 AWS 身份验证正常工作。
默认情况下,Hibernate Search 将依赖于 AWS SDK 中的默认凭据提供程序。此提供程序将在多个位置(Java 系统属性、环境变量、AWS 特定配置等)查找凭据。有关默认凭据提供程序工作方式的更多信息,请参阅 其官方文档。
或者,您可以使用以下选项设置静态凭据。
hibernate.search.backend.aws.credentials.type = static
hibernate.search.backend.aws.credentials.access_key_id = AKIDEXAMPLE
hibernate.search.backend.aws.credentials.secret_access_key = wJalrXUtnFEMI/K7MDENG+bPxRfiCYEXAMPLEKEY18.4.6. 连接调整
- 超时
-
# hibernate.search.backend.request_timeout = 30000 hibernate.search.backend.connection_timeout = 1000 hibernate.search.backend.read_timeout = 30000-
request_timeout定义执行请求时的超时时间。这包括建立连接、发送请求和读取响应所需的时间。此属性没有默认定义。 -
connection_timeout定义建立连接时的超时时间。此属性的默认值为1000。 -
read_timeout定义读取响应时的超时时间。此属性的默认值为30000。这些属性期望一个正 整数(以毫秒为单位),例如
3000。
-
- 连接池
-
hibernate.search.backend.max_connections = 20 hibernate.search.backend.max_connections_per_route = 10-
max_connections定义与 Elasticsearch 集群同时建立的最大连接数,所有主机加在一起。此属性的默认值为20。 -
max_connections_per_route定义与 Elasticsearch 集群每个主机的同时建立的最大连接数。此属性的默认值为10。
这些属性期望一个正 整数,例如
20。 -
- 保持活动
-
hibernate.search.backend.max_keep_alive = 10000-
max_keep_alive定义与 Elasticsearch 集群的连接可以保持空闲的时间长度。期望一个正 长整型(以毫秒为单位),例如
60000。如果来自 Elasticsearch 集群的响应包含
Keep-Alive标头,则有效的最大空闲时间将是两者中较低的一个:Keep-Alive标头中的持续时间或此属性的值(如果已设置)。如果未设置此属性,则只考虑
Keep-Alive标头,如果不存在,则空闲连接将永远保持活动状态。
-
18.4.7. 自定义 HTTP 客户端配置
可以使用 org.apache.http.impl.nio.client.HttpAsyncClientBuilder 的实例直接配置 HTTP 客户端。
使用此 API,您可以添加拦截器、更改保持活动状态、最大连接数、SSL 密钥/信任存储设置以及许多其他客户端配置。
直接配置 HTTP 客户端需要两个步骤。
-
定义一个实现
org.hibernate.search.backend.elasticsearch.client.ElasticsearchHttpClientConfigurer接口的类。 -
通过将配置属性
hibernate.search.backend.client.configurer设置为指向实现的 Bean 引用(例如class:org.hibernate.search.documentation.backend.elasticsearch.client.HttpClientConfigurer)来配置 Hibernate Search 以使用该实现。
ElasticsearchHttpClientConfigurerpublic class HttpClientConfigurer implements ElasticsearchHttpClientConfigurer { (1)
@Override
public void configure(ElasticsearchHttpClientConfigurationContext context) { (2)
HttpAsyncClientBuilder clientBuilder = context.clientBuilder(); (3)
clientBuilder.setMaxConnPerRoute( 7 ); (4)
clientBuilder.addInterceptorFirst( (HttpResponseInterceptor) (request, httpContext) -> {
long contentLength = request.getEntity().getContentLength();
// doing some stuff with contentLength
} );
}
}| 1 | 该类必须实现 ElasticsearchHttpClientConfigurer 接口。 |
| 2 | configure 方法提供对 ElasticsearchHttpClientConfigurationContext 的访问。 |
| 3 | 从上下文中,可以获取 HttpAsyncClientBuilder。 |
| 4 | 最后,您可以使用构建器使用自定义设置配置客户端。 |
(1)
hibernate.search.backend.client.configurer = class:org.hibernate.search.documentation.backend.elasticsearch.client.HttpClientConfigurer| 1 | 指定 HTTP 客户端配置器。 |
|
自定义 http 客户端配置器定义的任何设置将覆盖 Hibernate Search 定义的任何其他设置。 |
18.5. 版本兼容性
18.5.1. Hibernate Search 假设的版本
Elasticsearch/OpenSearch 的不同发行版和版本公开了略微不同的 API。因此,Hibernate Search 需要了解它正在与之通信的发行版和版本,以便生成正确的 HTTP 请求。
默认情况下,Hibernate Search 将在启动时查询 Elasticsearch/OpenSearch 集群以检索此信息,并将推断要采用的正确行为。
您可以强制 Hibernate Search 预期 Elasticsearch/OpenSearch 的特定版本,方法是将属性 hibernate.search.backend.version 设置为遵循格式 x.y.z-qualifier 或 <distribution>:x.y.z-qualifier 或仅 <distribution> 的版本字符串,其中
-
<distribution>为elastic、opensearch或amazon-opensearch-serverless。可选,默认为elastic。 -
x、y和z是整数。x是必需的,y和z是可选的。 -
qualifier是一个单词字符(字母数字或_)的字符串。可选。
例如,8、8.0、8.9、opensearch:2.9、amazon-opensearch-service 都是有效的版本字符串。
|
Amazon OpenSearch Serverless 是一种特殊情况,因为它不使用版本号。 使用该平台时,您**必须**设置版本,并且必须将其设置为仅 |
Hibernate Search 仍将查询 Elasticsearch/OpenSearch 集群以检测集群的实际发行版和版本(不支持的地方除外,即 Amazon OpenSearch Serverless),以检查配置的发行版和版本是否与实际版本匹配。
18.5.2. 禁用启动时的版本检查
如有必要,您可以禁用启动时对 Elasticsearch/OpenSearch 集群的调用,并手动提供信息。
为此,将属性 hibernate.search.backend.version_check.enabled 设置为 false。
您还需要将属性 hibernate.search.backend.version 设置为 上一节 中解释的版本字符串。
在这种情况下,主版本号和次版本号(在上述格式中分别为x和y)都是必需的,但如果distribution是默认值(elasticsearch),则可以省略,其他所有组件(micro、qualifier)都是可选的。例如,8.0、8.9、opensearch:2.9 在这种情况下都是有效的版本字符串,但8不够精确。
18.7. 分片
|
有关分片的初步介绍,包括它在 Hibernate Search 中的工作原理及其局限性,请参见 分片和路由。 |
Elasticsearch 默认情况下会禁用分片。要启用它,在您的集群中设置属性index.number_of_shards。
18.8. 模式管理
Elasticsearch 索引需要在使用它们进行索引和搜索之前创建;有关如何在 Hibernate Search 中创建索引及其模式的更多信息,请参阅 管理索引模式。
特别是对于 Elasticsearch,可以通过以下选项进行一些微调
# To configure the defaults for all indexes:
hibernate.search.backend.schema_management.minimal_required_status = green
hibernate.search.backend.schema_management.minimal_required_status_wait_timeout = 10000
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.schema_management.minimal_required_status = green
hibernate.search.backend.indexes.<index-name>.schema_management.minimal_required_status_wait_timeout = 10000-
minimal_required_status定义创建完成之前索引所需的最小状态。此属性的默认值为yellow,除了Amazon OpenSearch Serverless,因为该平台不支持索引状态检查,所以会跳过索引状态检查。 -
minimal_required_status_wait_timeout定义等待此状态的最大时间(以毫秒为单位的整数)。此属性的默认值为10000。
这些属性仅在创建或验证索引作为模式管理的一部分时有效。
18.9. 索引布局
Hibernate Search 使用别名 索引。这意味着 Hibernate Search 中具有给定名称的索引不会直接映射到 Elasticsearch 中具有相同名称的索引。
索引布局是 Hibernate Search 索引名称如何映射到 Elasticsearch 索引的方式,控制该布局的策略是在后端级别设置的
hibernate.search.backend.layout.strategy = simple此属性的默认值为simple。
有关可用策略的详细信息,请参见以下小节。
18.9.1. simple:默认的,面向未来的策略
对于 Hibernate Search 中名称为myIndex的索引
-
如果 Hibernate Search 自动创建索引,它将索引命名为
myindex-000001,并将自动创建写入和读取别名。 -
写入操作(索引、清除等)将针对别名
myindex-write。 -
读取操作(搜索、解释等)将针对别名
myindex-read。
|
与直接定位索引相比,使用别名具有显着优势:它使在实时应用程序上进行完全重新索引成为可能,而不会出现停机时间,这在监听器触发的索引 被禁用(完全禁用 或部分禁用)且您需要定期进行完全重新索引(例如,每天一次)时特别有用。 使用别名,您只需将读取别名(由搜索查询使用)定向到索引的旧副本,而写入别名(由文档写入使用)将被重定向到索引的新副本。如果没有别名(特别是使用 这种“零停机时间”重新索引与“蓝绿”部署 有一些相似之处,目前尚不能由 Hibernate Search 本身提供。但是,您可以通过直接向 Elasticsearch 的 REST API 发出命令来在您的应用程序中实现它。基本操作顺序如下
注意,这仅在 Hibernate Search 映射没有更改时才有效;具有更改模式的零停机时间升级将更为复杂。您将在HSEARCH-2861 和HSEARCH-3499 中找到有关此主题的讨论。 |
18.9.2. no-alias:一种没有索引别名的策略
此策略主要在遗留集群上很有用。
对于 Hibernate Search 中名称为myIndex的索引
-
如果 Hibernate Search 自动创建索引,它将索引命名为
myindex,并且不会创建任何别名。 -
写入操作(索引、清除等)将直接通过其名称
myindex针对索引。 -
读取操作(搜索、解释等)将直接通过其名称
myindex针对索引。
18.9.3. 自定义策略
如果内置的布局策略不符合您的要求,您可以通过两个简单的步骤定义自定义布局
-
定义一个实现接口
org.hibernate.search.backend.elasticsearch.index.layout.IndexLayoutStrategy的类。 -
通过将配置属性
hibernate.search.backend.layout.strategy设置为指向实现的bean 引用(例如class:com.mycompany.MyLayoutStrategy)来配置后端使用该实现。
例如,下面的实现将导致对名为myIndex 的索引使用以下布局
-
写入操作(索引、清除等)将针对别名
myindex-write。 -
读取操作(搜索、解释等)将针对别名
myindex(没有后缀)。 -
如果 Hibernate Search 自动创建索引 在 2017 年 11 月 6 日下午 7:19:00 恰好创建,它将索引命名为
myindex-20171106-191900-000000000。
import java.time.Clock;
import java.time.Instant;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.Locale;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.hibernate.search.backend.elasticsearch.index.layout.IndexLayoutStrategy;
public class CustomLayoutStrategy implements IndexLayoutStrategy {
private static final DateTimeFormatter INDEX_SUFFIX_FORMATTER =
DateTimeFormatter.ofPattern( "uuuuMMdd-HHmmss-SSSSSSSSS", Locale.ROOT )
.withZone( ZoneOffset.UTC );
private static final Pattern UNIQUE_KEY_PATTERN =
Pattern.compile( "(.*)-\\d+-\\d+-\\d+" );
@Override
public String createInitialElasticsearchIndexName(String hibernateSearchIndexName) {
// Clock is Clock.systemUTC() in production, may be overridden in tests
Clock clock = MyApplicationClock.get();
return hibernateSearchIndexName + "-"
+ INDEX_SUFFIX_FORMATTER.format( Instant.now( clock ) );
}
@Override
public String createWriteAlias(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "-write";
}
@Override
public String createReadAlias(String hibernateSearchIndexName) {
return hibernateSearchIndexName;
}
@Override
public String extractUniqueKeyFromHibernateSearchIndexName(
String hibernateSearchIndexName) {
return hibernateSearchIndexName;
}
@Override
public String extractUniqueKeyFromElasticsearchIndexName(
String elasticsearchIndexName) {
Matcher matcher = UNIQUE_KEY_PATTERN.matcher( elasticsearchIndexName );
if ( !matcher.matches() ) {
throw new IllegalArgumentException(
"Unrecognized index name: " + elasticsearchIndexName
);
}
return matcher.group( 1 );
}
}18.9.4. 检索索引或别名名称
可以从元模型 中检索用于读取和写入的索引或别名名称。
SearchMapping mapping = /* ... */ (1)
IndexManager indexManager = mapping.indexManager( "Book" ); (2)
ElasticsearchIndexManager esIndexManager = indexManager.unwrap( ElasticsearchIndexManager.class ); (3)
ElasticsearchIndexDescriptor descriptor = esIndexManager.descriptor();(4)
String readName = descriptor.readName();(5)
String writeName = descriptor.writeName();(5)| 1 | 检索 SearchMapping. |
| 2 | 检索 IndexManager。 |
| 3 | 将索引管理器缩小到ElasticsearchIndexManager 类型。 |
| 4 | 获取索引描述符。 |
| 5 | 获取索引(或别名)的读取和写入名称。 |
18.10. 模式(“映射”)
Elasticsearch 所谓的“映射” 是分配给每个索引的模式,它指定每个“属性”(在 Hibernate Search 中称为“索引字段”)的数据类型和功能。
在大多数情况下,Elasticsearch 映射是从通过 Hibernate Search 的映射 API 配置的映射 推断出来的,这些 API 是通用的,与 Elasticsearch 无关。
本节将解释与 Elasticsearch 后端相关的方面。
|
Hibernate Search 可以配置为在通过模式管理 创建索引时将映射推送到 Elasticsearch。 |
18.10.1. 字段类型
可用的字段类型
|
某些类型不受 Elasticsearch 后端直接支持,但由于它们被映射器“桥接”,因此仍然可以使用。例如,您的实体模型中的 |
|
不在此列表中的字段类型仍然可以通过更多工作来使用
|
| 字段类型 | 数据类型 在 Elasticsearch 中 | 限制 |
|---|---|---|
|
如果定义了分析器,则为 |
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
- |
|
日期/时间字段的范围和分辨率
Elasticsearch
超出范围的值将导致索引失败。 分辨率也较低
索引时将丢失毫秒级精度之外的精度。 |
索引字段类型 DSL 扩展
并非所有 Elasticsearch 字段类型在 Hibernate Search 中都具有内置支持。但是,通过利用“本机”字段类型,仍然可以使用不受支持的字段类型。使用此字段类型,可以将 Elasticsearch“映射”直接定义为 JSON,从而可以访问 Elasticsearch 可以提供的任何内容。
以下是如何使用 Elasticearch“本机”类型的示例。
public class IpAddressValueBinder implements ValueBinder { (1)
@Override
public void bind(ValueBindingContext<?> context) {
context.bridge(
String.class,
new IpAddressValueBridge(),
context.typeFactory() (2)
.extension( ElasticsearchExtension.get() ) (3)
.asNative() (4)
.mapping( "{\"type\": \"ip\"}" ) (5)
);
}
private static class IpAddressValueBridge implements ValueBridge<String, JsonElement> {
@Override
public JsonElement toIndexedValue(String value,
ValueBridgeToIndexedValueContext context) {
return value == null ? null : new JsonPrimitive( value ); (6)
}
@Override
public String fromIndexedValue(JsonElement value,
ValueBridgeFromIndexedValueContext context) {
return value == null ? null : value.getAsString(); (7)
}
}
}| 1 | 定义一个 自定义绑定器 及其桥接。 “native”类型只能从绑定器中使用,不能直接与注释映射一起使用。这里我们定义了一个 值绑定器,但 类型绑定器 或 属性绑定器 也可以使用。 |
| 2 | 获取上下文的类型工厂。 |
| 3 | 将 Elasticsearch 扩展应用于类型工厂。 |
| 4 | 调用 asNative 开始定义本地类型。 |
| 5 | 将 Elasticsearch 映射作为 JSON 传递。 |
| 6 | 本机字段的值在 Hibernate Search 中表示为JsonElement。JsonElement 是来自Gson 库的类型。不要忘记在将它们传递到后端之前正确地格式化它们。这里,我们从String 创建一个JsonPrimitive(JsonElement 的子类型),因为我们只需要一个 JSON 字符串,但完全有可能处理更复杂的对象,甚至可以使用 Gson 直接从 POJO 转换为 JSON。 |
| 7 | 为了获得更友好的投影,您还可以实现此方法以从JsonElement 转换为映射类型(此处为String)。 |
@Entity
@Indexed
public class CompanyServer {
@Id
@GeneratedValue
private Integer id;
@NonStandardField( (1)
valueBinder = @ValueBinderRef(type = IpAddressValueBinder.class) (2)
)
private String ipAddress;
// Getters and setters
// ...
}| 1 | 将属性映射到索引字段。注意,使用非标准类型(例如 Elasticsearch 的“本机”类型)的值桥接器必须使用@NonStandardField 注释进行映射:其他注释(例如@GenericField)将失败。 |
| 2 | 指示 Hibernate Search 使用我们自定义的值绑定器。 |
18.10.2. 实体类型名称映射
当 Hibernate Search 执行针对多个实体类型(因此针对多个索引)的搜索查询时,它需要确定每个搜索命中结果的实体类型,以便将其映射回实体。
有多种策略可以处理这种“实体类型名称解析”,每种策略都有优缺点。
策略是在后端级别设置的
hibernate.search.backend.mapping.type_name.strategy = discriminator此属性的默认值为discriminator。
有关可用策略的详细信息,请参见以下小节。
18.10.3. 动态映射
默认情况下,Hibernate Search将Elasticsearch索引映射中的dynamic属性设置为strict。这意味着尝试索引映射中不存在的字段的文档会导致索引失败。
如果Hibernate Search是唯一的客户端,则不会出现问题,因为Hibernate Search通常仅针对声明的模式字段进行操作。对于需要更改此设置的其他情况,可以使用以下索引级属性更改值。
# To configure the defaults for all indexes:
hibernate.search.backend.dynamic_mapping = strict
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.dynamic_mapping = strict此属性的默认值为strict。
我们说Hibernate Search通常针对声明的模式字段进行操作。更确切地说,如果未定义任何使用字段模板的动态字段,它始终这样做。当定义字段模板时,dynamic将强制设置为true,以允许动态字段。在这种情况下,dynamic_mapping属性的值将被忽略。
18.10.4. 多租户
多租户支持并且根据当前会话中定义的租户 ID 透明地处理。
-
文档将使用适当的值进行索引,以便以后进行过滤;
-
查询将适当地过滤结果。
如果在映射器中启用了多租户,则后端会自动启用多租户,例如,如果 在 Hibernate ORM 中选择了多租户策略,或者如果 在独立 POJO 映射器中显式配置了多租户。
但是,可以手动启用多租户。
多租户策略是在后端级别设置的。
hibernate.search.backend.multi_tenancy.strategy = none有关可用策略的详细信息,请参见以下小节。
18.10.5. 自定义索引映射
基本原理
Hibernate Search可以创建和验证索引,但默认情况下创建的索引只包含索引和搜索所需的最少内容:映射和分析设置。如果需要自定义一些映射参数,可以向Hibernate Search提供自定义映射:它将在创建索引时包含自定义映射。
|
自定义 Elasticsearch 映射与 Hibernate Search 映射的一致性不会以任何方式进行检查。您有责任确保您的映射中的任何覆盖都可以正常工作,例如您没有将索引字段的类型从 无效的自定义映射可能不会在启动时触发任何异常,但会在以后索引或查询时触发。在最坏的情况下,它可能不会触发任何异常,但只会导致搜索结果不正确。请务必谨慎操作。 |
# To configure the defaults for all indexes:
hibernate.search.backend.schema_management.mapping_file = custom/index-mapping.json
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.schema_management.mapping_file = custom/index-mapping.jsoncustom/index-mapping.json 文件的可能内容{
"properties":{
"userField":{
"type":"keyword",
"index":true,
"norms":true,
"doc_values":true
},
"userObject":{
"dynamic":"true",
"type":"object"
}
},
"_source": {
"enabled": false
}
}|
仅在自定义映射文件中定义,而 Hibernate Search 未映射的属性将对 Hibernate Search 不可见。 |
该文件不需要包含完整的映射:Hibernate Search 会自动将给定映射中缺少的属性(索引字段)注入其中。
给定映射与 Hibernate Search 生成的映射之间的冲突将按如下方式处理
-
dynamic_templates/_routing/dynamic映射参数将来自给定映射,如果存在,则回退到 Hibernate Search 生成的值。 -
除了映射根部的
properties之外的任何其他映射参数都将来自给定映射;Hibernate Search 生成的参数将被忽略。 -
properties将被合并,使用给定映射和 Hibernate Search 生成的映射中定义的属性。 -
如果属性在两边都被定义,它将被递归合并,按照步骤 1-4。
在上面的示例中,生成的合并映射可能如下所示
custom/index-mapping.json的内容与 Hibernate Search 映射合并后,可能的最终映射{
"_source":{
"enabled":false
},
"dynamic":"strict",
"properties":{
"_entity_type":{ (1)
"type":"keyword",
"index":false
},
"title":{ (2)
"type":"text",
"analyzer":"english"
},
"userField":{
"type":"keyword",
"norms":true
},
"userObject":{
"type":"object",
"dynamic":"true"
}
}
}| 1 | 此属性始终由 Hibernate Search 添加,用于内部实现目的。 |
| 2 | 这是 Hibernate Search 生成的属性,因为已索引实体具有一个用@FullTextField注释的String name属性。 |
禁用_source
使用此功能可以禁用_source字段。例如,您可以传递一个custom/index-mapping.json文件,如下所示
custom/index-mapping.json 文件的可能内容,用于禁用_source字段{
"_source": {
"enabled": false
}
}|
禁用 一些投影依赖于 |
18.11. 分析
18.11.1. 基本原理
分析 是分析器执行的文本处理,包括索引时 (文档处理) 和搜索时 (查询处理)。
所有内置的 Elasticsearch 分析器都可以透明地使用,无需在 Hibernate Search 中进行任何配置:只需在 Hibernate Search 预期分析器名称的任何位置使用其名称即可。但是,也可以显式地配置分析。
|
Elasticsearch 分析配置不会在启动时立即应用:需要将其推送到 Elasticsearch 集群。 Hibernate Search 仅在通过模式管理指示的情况下才将配置推送到集群。 |
要在 Elasticsearch 后端配置分析,您需要
-
定义一个实现
org.hibernate.search.backend.elasticsearch.analysis.ElasticsearchAnalysisConfigurer接口的类。 -
通过将配置属性
hibernate.search.backend.analysis.configurer设置为指向实现的 bean 引用 来配置后端,例如class:com.mycompany.MyAnalysisConfigurer。
| 您可以传递多个以逗号分隔的 bean 引用。请参阅 配置属性的类型。 |
Hibernate Search 将在启动时调用此实现的configure方法,配置器将能够利用 DSL 定义分析器和规范器。
|
可以为每个索引分配不同的分析配置器 如果为某个索引分配了特定的配置器,则默认配置器将被忽略:只有特定配置器中的定义才会被考虑。 |
18.11.2. 内置分析器
内置分析器开箱即用,无需显式配置。如有必要,可以通过定义具有相同名称的自定义分析器来覆盖它们。
Elasticsearch 后端附带了几个内置分析器。确切的列表取决于 Elasticsearch 的版本,可以在此处找到。
无论 Elasticsearch 版本如何,其名称在org.hibernate.search.engine.backend.analysis.AnalyzerNames中作为常量列出的分析器始终可用
default-
默认情况下,
@FullTextField使用的分析器。默认情况下,这只是
standard的别名。 standard-
默认行为:首先,使用标准分词器进行分词,该分词器遵循 Unicode 文本分段算法中的词语分隔规则,如 Unicode 标准附件 #29 中所述。然后,将每个词语转换为小写。
simple-
默认行为:首先,在非字母字符处分割文本。然后,将每个词语转换为小写。
whitespace-
默认行为:在空格字符处分割文本。不要更改词语。
stop-
默认行为:首先,在非字母字符处分割文本。然后,将每个词语转换为小写。最后,删除英语停用词。
keyword-
默认行为:不要以任何方式更改文本。
使用此分析器,全文字段的行为类似于关键字字段,但功能更少:例如,没有术语聚合。
建议改用
@KeywordField。
18.11.4. 自定义分析器和规范器
传递给配置器的上下文公开了用于定义分析器和规范器的 DSL。
package org.hibernate.search.documentation.analysis;
import org.hibernate.search.backend.elasticsearch.analysis.ElasticsearchAnalysisConfigurationContext;
import org.hibernate.search.backend.elasticsearch.analysis.ElasticsearchAnalysisConfigurer;
public class MyElasticsearchAnalysisConfigurer implements ElasticsearchAnalysisConfigurer {
@Override
public void configure(ElasticsearchAnalysisConfigurationContext context) {
context.analyzer( "english" ).custom() (1)
.tokenizer( "standard" ) (2)
.charFilters( "html_strip" ) (3)
.tokenFilters( "lowercase", "snowball_english", "asciifolding" ); (4)
context.tokenFilter( "snowball_english" ) (5)
.type( "snowball" )
.param( "language", "English" ); (6)
context.normalizer( "lowercase" ).custom() (7)
.tokenFilters( "lowercase", "asciifolding" );
context.analyzer( "french" ).custom() (8)
.tokenizer( "standard" )
.tokenFilters( "lowercase", "snowball_french", "asciifolding" );
context.tokenFilter( "snowball_french" )
.type( "snowball" )
.param( "language", "French" );
}
}| 1 | 定义一个名为“english”的自定义分析器,因为它将用于分析英语文本,例如书籍标题。 |
| 2 | 将分词器设置为标准分词器。 |
| 3 | 设置字符过滤器。字符过滤器按照给定的顺序应用,在分词器之前应用。 |
| 4 | 设置词语过滤器。词语过滤器按照给定的顺序应用,在分词器之后应用。 |
| 5 | 请注意,对于 Elasticsearch,任何带参数的字符过滤器、分词器或词元过滤器都必须单独定义并分配一个名称。 |
| 6 | 设置正在定义的字符过滤器/分词器/词元过滤器的参数的值。 |
| 7 | 规范器的定义方式类似,唯一的区别是它们不能使用分词器。 |
| 8 | 可以在同一个配置器中定义多个分析器/规范器。 |
(1)
hibernate.search.backend.analysis.configurer = class:org.hibernate.search.documentation.analysis.MyElasticsearchAnalysisConfigurer| 1 | 使用 Hibernate Search 配置属性将配置器分配给后端。 |
也可以为带参数的内置分析器分配一个名称
context.analyzer( "english_stopwords" ).type( "standard" ) (1)
.param( "stopwords", "_english_" ); (2)| 1 | 使用给定名称和类型定义一个分析器。 |
| 2 | 设置正在定义的分析器的参数的值。 |
要了解哪些分析器、字符过滤器、分词器和词元过滤器可用,请参考文档
18.11.5. 覆盖默认分析器
在没有显式指定分析器的情况下使用 @FullTextField 时的默认分析器名为 default。
package org.hibernate.search.documentation.analysis;
import org.hibernate.search.backend.elasticsearch.analysis.ElasticsearchAnalysisConfigurationContext;
import org.hibernate.search.backend.elasticsearch.analysis.ElasticsearchAnalysisConfigurer;
public class MyElasticsearchAnalysisConfigurer implements ElasticsearchAnalysisConfigurer {
@Override
public void configure(ElasticsearchAnalysisConfigurationContext context) {
context.analyzer( "english" ).custom() (1)
.tokenizer( "standard" ) (2)
.charFilters( "html_strip" ) (3)
.tokenFilters( "lowercase", "snowball_english", "asciifolding" ); (4)
context.tokenFilter( "snowball_english" ) (5)
.type( "snowball" )
.param( "language", "English" ); (6)
context.normalizer( "lowercase" ).custom() (7)
.tokenFilters( "lowercase", "asciifolding" );
context.analyzer( "french" ).custom() (8)
.tokenizer( "standard" )
.tokenFilters( "lowercase", "snowball_french", "asciifolding" );
context.tokenFilter( "snowball_french" )
.type( "snowball" )
.param( "language", "French" );
}
}| 1 | 开始定义一个名为 default 的自定义分析器。这里我们依赖 org.hibernate.search.engine.backend.analysis.AnalyzerNames 中的常量来使用正确的名称,但硬编码 "default" 也可以正常工作。 |
| 2 | 继续定义分析器,就像我们对任何其他自定义分析器所做的那样。 |
(1)
hibernate.search.backend.analysis.configurer = class:org.hibernate.search.documentation.analysis.DefaultOverridingElasticsearchAnalysisConfigurer| 1 | 使用 Hibernate Search 配置属性将配置器分配给后端。 |
18.12. 自定义索引设置
Hibernate Search可以创建和验证索引,但默认情况下创建的索引只包含索引和搜索所需的最少内容:映射和分析设置。如果需要设置一些自定义索引设置,可以向Hibernate Search提供这些设置:它将在创建索引时包含这些设置,并在验证索引时考虑这些设置。
# To configure the defaults for all indexes:
hibernate.search.backend.schema_management.settings_file = custom/index-settings.json
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.schema_management.settings_file = custom/index-settings.jsoncustom/index-settings.json 文件可能的內容{
"number_of_shards": "3",
"number_of_replicas": "3",
"analysis": {
"analyzer": {
"my_standard-english": {
"type": "standard",
"stopwords": "_english_"
},
"my_analyzer_ngram": {
"type": "custom",
"tokenizer": "my_analyzer_ngram_tokenizer"
}
},
"tokenizer": {
"my_analyzer_ngram_tokenizer": {
"type": "ngram",
"min_gram": "5",
"max_gram": "6"
}
}
}
}提供的設定將會與 Hibernate Search 生成的設定合併,包括分析器定義。當分析同時透過 分析配置器 和這些自訂設定進行配置時,其行為未定義;不應依賴此行為。
|
自訂索引設定必須以簡化形式提供,即不包含 |
18.13. 線程
Elasticsearch 後端依賴內部線程池來協調索引請求(新增/更新/刪除)並安排請求超時。
默认情况下,池包含与启动时 JVM 可用的处理器数量完全相同的线程。可以使用配置属性更改此设置
hibernate.search.backend.thread_pool.size = 4|
此数字是 *每个后端*,而不是 *每个索引*。添加更多索引不会添加更多线程。 |
|
由於此線程池中的所有操作都是非阻塞的,因此將其大小提高到 JVM 可用的處理器核心數量以上不會帶來明顯的性能提升。 更改此設定的唯一原因是減少線程數量;例如,在具有單個索引和單個索引隊列的應用程式中,在具有 64 個處理器核心的機器上運行,您可能希望降低線程數量。 |
18.14. 索引隊列
在 Hibernate Search 發送到 Elasticsearch 的所有請求中,預計會有大量的「索引」請求來建立/更新/刪除特定文檔。逐一發送這些請求效率低下(主要是由於網路延遲)。此外,我們通常希望在處理相同文檔的請求時保留它們的相對順序。
出於這些原因,Hibernate Search 將這些請求推送到有序隊列,並依賴 批量 API 來批量發送它們。每個索引維護 10 個隊列,每個隊列最多包含 1000 個元素,每個隊列將發送最多包含 100 個索引請求的批量請求。隊列獨立運作(並行),但每個隊列在發送一個批量請求後才會發送另一個,因此在任何給定時間,每個索引最多可以發送 10 個批量請求。
|
相对于相同文档 ID 的索引操作始终被推送到同一个队列。 |
可以自訂隊列以減輕 Elasticsearch 伺服器的負擔,或者相反地提高吞吐量。這通過以下配置屬性實現
# To configure the defaults for all indexes:
hibernate.search.backend.indexing.queue_count = 10
hibernate.search.backend.indexing.queue_size = 1000
hibernate.search.backend.indexing.max_bulk_size = 100
# To configure a specific index:
hibernate.search.backend.indexes.<index-name>.indexing.queue_count = 10
hibernate.search.backend.indexes.<index-name>.indexing.queue_size = 1000
hibernate.search.backend.indexes.<index-name>.indexing.max_bulk_size = 100-
indexing.queue_count定义队列的数量。期望一个严格的正整数。此属性的默认值为 `10`。更高的值將導致更多連接並行使用,這可能會導致更高的索引吞吐量,但會冒著 過載 Elasticsearch 的風險,從而導致 Elasticsearch 放棄某些請求,並導致索引失敗。
-
indexing.queue_size定义每个队列可以容纳的最大元素数量。期望一个严格的正整数。此属性的默认值为 `1000`。更低的值可能會導致更低的記憶體使用量,特別是當有許多隊列時,但過低的值會降低達到最大批量大小的可能性,並增加 應用程式線程阻塞 的可能性,因為隊列已滿,這可能會導致更低的索引吞吐量。
-
indexing.max_bulk_size定義每個批量請求中索引請求的最大數量。預期為嚴格的正整數值。此屬性的默認值為100。更高的值將導致在發送到 Elasticsearch 的每個 HTTP 請求中發送更多文檔,這可能會導致更高的索引吞吐量,但會冒著 過載 Elasticsearch 的風險,從而導致 Elasticsearch 放棄某些請求,並導致索引失敗。
請注意,將此數字提高到超過隊列大小不會有任何效果,因為批量不能包含超過隊列中包含的請求數量。
|
当队列已满时,任何尝试请求索引的操作都会阻塞,直到请求可以放入队列中。 为了获得合理的性能水平,请确保将队列的大小设置为足够大的数字,以便这种阻塞仅在应用程序承受非常高的负载时才会发生。 |
|
Elasticsearch 節點只能處理這麼多並行請求,特別是它們 限制可用於存儲所有待處理請求的記憶體量。在任何給定時間。 為避免索引失敗,避免為隊列數量和最大批量大小使用過大的數字,特別是在您預計索引將包含大量文檔的情況下。 |
18.15. 寫入和讀取
|
有关在 Hibernate Search 中写入和读取索引的初步介绍,特别是包括 *提交* 和 *刷新* 的概念,请参见 提交和刷新。 |
18.15.1. 提交
當寫入索引時,Elasticsearch 依賴 事務日誌 來確保更改,即使未提交,只要 REST API 調用返回,就始終安全。
出於這個原因,"提交"的概念對於 Elasticsearch 後端並不那麼重要,提交需求在很大程度上無關緊要。
18.16. 搜索
使用 Elasticsearch 後端進行搜索依賴於 與任何其他後端相同的 API。
本節詳細說明與搜索相關的 Elasticsearch 特定配置。
18.16.1. 滾動超時
使用 Elasticsearch 後端,滾動 會受到超時限制。如果 next() 在很長一段時間(默認:60 秒)內未被調用,滾動將會自動關閉,並且下一次調用 next() 將會失敗。
在後端級別使用以下配置屬性來配置超時時間(以秒為單位)
hibernate.search.backend.scroll_timeout = 60此屬性的默認值為 60。
18.16.2. 部分分片失敗
使用 Elasticsearch 後端,獲取結果 可能會導致部分分片失敗,即一些分片將無法產生結果,而其他分片將會成功。在這種情況下,Elasticsearch 集群將產生具有成功狀態碼的響應,但將包含有關失敗分片的額外信息以及它們失敗的原因。
默認情況下,Hibernate Search 將檢查是否有任何分片在獲取結果時失敗,如果失敗,將會拋出異常。
在後端級別使用以下配置屬性來更改默認行為
hibernate.search.backend.query.shard_failure.ignore = true此屬性的默認值為 false。
19. 協調
19.1. 基本知識
|
協調是一個複雜的主題,它解決的問題乍一看可能不太清楚。您可能會發現從更高層次理解協調更容易。 有關涉及不同協調策略的一些示例架構,以及每個架構之間差異的摘要,請參閱 架構示例。 有關特定於監聽器觸發索引上下文中協調策略之間差異的摘要,請參閱 基本知識。 |
使用 Hibernate Search 的應用程式通常依賴於多個線程,甚至多個應用程式實例,這些實例將同時更新數據庫。
協調策略定義了這些線程/節點如何彼此協調以根據這些數據庫更新更新索引,以確保一致性,防止數據丟失並優化性能。
默認策略不提供任何協調。請參閱以下小節以獲取有關 默認工作方式 的詳細信息,以及如何使用其他策略,即 outbox-polling。
|
協調策略僅適用於與 Hibernate ORM 的集成。 請參閱 本節,了解有關獨立 POJO 映射器中協調的信息。 |
19.2. 無協調
19.2.1. 基本知識
none 策略是最簡單的策略,不涉及任何額外的基礎架構來實現應用程式節點之間的通信。
所有 顯式或監聽器觸發索引 操作都在應用程式線程中直接執行,這使得此策略具有獨特的特性,可以提供 同步索引,但代價是有一些限制
此策略默認啟用,但也可以使用以下設定顯式選擇
hibernate.search.coordination.strategy = none19.2.2. 在沒有協調的情況下索引的工作方式
- 更改必須在 ORM 會話中發生才能觸發 索引監聽器
-
請參閱 會話內實體更改檢測及其限制,了解更詳細的信息。
- 关联必须在两端更新
-
請參閱 監聽器觸發索引忽略非對稱關聯更新,了解更詳細的信息。
- 只有相關更改會觸發索引
-
請參閱 髒檢查,了解更詳細的信息。
- 實體數據在會話刷新或
SearchSession.close()時從實體中提取 -
當 Hibernate ORM 會話被刷新時,或者(使用 獨立 POJO 映射器)當調用
SearchSession.close()時,Hibernate Search 將從實體中提取數據來構建要索引的文檔,並將這些文檔放入內部緩衝區以供 稍後索引。此提取 可能涉及從數據庫加載額外數據。使用 Hibernate ORM 集成,在 Hibernate ORM 會話刷新時填充此內部緩衝區意味著您可以在
flush()後安全地clear()會話:在刷新之前執行的實體更改將會被正確索引。如果您來自 Hibernate Search 5 或更早版本,您可能會認為這是一個重大改進:除了大量數據以外(請參閱 Hibernate ORM 和使用
SearchIndexingPlan的週期性“刷新-清除”模式),不再需要在事務中間調用flushToIndexes()和更新索引。但是,如果您使用 Hibernate ORM 集成 在事務中執行批處理過程,並定期調用
session.flush()/session.clear()來節省記憶體,請注意,Hibernate Search 用於保存要索引的文檔的內部緩衝區將在每次刷新時增長,並且在事務提交或回滾之前不會被清除。如果您因其而遇到記憶體問題,請參閱 Hibernate ORM 和使用SearchIndexingPlan的週期性“刷新-清除”模式,以獲取一些解決方案。
- 提取實體數據可能會從數據庫中提取額外數據
-
即使您只更改了已索引實體的單個屬性,如果該屬性已索引,Hibernate Search 需要完全重新構建對應的文檔。
Hibernate Search 嘗試僅加載索引所需的內容,但根據您的映射,這可能會導致懶加載關聯被加載僅用於重新索引實體,即使您在業務代碼中不需要它們,這可能會給應用程式線程和數據庫帶來額外的開銷。
使用 Hibernate ORM 集成,這項額外成本可以通過以下方式在一定程度上得到緩解
-
利用 Hibernate ORM 的批量获取:请参阅
batch_fetch_size属性 和@BatchSize注解。 -
利用 Hibernate ORM 的 二级缓存,特别是对于从索引实体引用的不可变实体(例如,国家、城市等参考数据)。
-
- 索引不在提交时保证,而是在应用程序线程返回后保证。
-
当实体更改发生在事务内时,索引不会立即更新,而是在事务成功提交后才更新。这样,如果事务回滚,索引将保持与数据库一致的状态,丢弃在事务期间计划的所有索引更改。
同样,当使用 独立 POJO 映射器 时,索引在
SearchSession.close()返回后保证更新。但是,如果在索引时后端出现错误,这种行为意味着 索引更改可能会丢失,导致索引不同步。如果这对您来说是一个问题,您应该考虑切换到 其他协调策略。
使用 Hibernate ORM 集成 时,当实体更改发生在任何事务之外(不推荐)时,索引会在会话 flush()时立即更新。如果没有执行 flush 操作,索引将不会自动更新。
- 索引更改可能不会立即可见。
-
默认情况下,索引将在索引更改提交到索引后恢复应用程序线程。这意味着索引更改已安全存储到磁盘,但这并不意味着在索引后立即运行的搜索查询将考虑这些更改:特别是当使用 Elasticsearch 后端时,更改可能需要一些时间才能从搜索查询中可见。
有关详细信息,请参阅 与索引同步。
19.3. outbox-polling:附加事件表和后台处理器的轮询
|
以下详细介绍的功能处于 孵化 状态:它们仍在积极开发中。 通常的 兼容性策略 不适用:孵化元素(例如类型、方法、配置属性等)的契约可能会在后续版本中以向后不兼容的方式更改(甚至被删除)。 建议您使用孵化功能,以便开发团队可以获得反馈并改进它们,但您应该准备好根据需要更新依赖于它们的代码。 |
19.3.1. 基础知识
outbox-polling 策略通过 应用程序数据库中的附加表 实现协调。
显式和监听器触发的索引 通过将事件推送到与实体更改相同事务中的 outbox 表来实现,并从后台处理器轮询此 outbox 表,后台处理器执行索引。
这种策略能够提供保证,无论后端中是否存在临时 I/O 错误,实体都将被索引,但代价是只能异步执行此索引。
outbox-polling 策略可以通过以下设置启用
hibernate.search.coordination.strategy = outbox-polling您还需要添加此依赖项
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-mapper-orm-outbox-polling</artifactId>
<version>7.2.0.Final</version>
</dependency>19.3.2. outbox-polling 协调如何工作
- 更改必須在 ORM 會話中發生才能觸發 索引監聽器
-
請參閱 會話內實體更改檢測及其限制,了解更詳細的信息。
- 关联必须在两端更新
-
請參閱 監聽器觸發索引忽略非對稱關聯更新,了解更詳細的信息。
- 只有相關更改會觸發索引
-
請參閱 髒檢查,了解更詳細的信息。
- 索引在后台线程中进行
-
当 Hibernate ORM 会话被刷新时,Hibernate Search 将在同一个 Hibernate ORM 会话和同一个事务中持久化实体更改事件。
事件处理器 轮询数据库以查找新的实体更改事件,并在找到新事件时异步执行相应实体的重新索引(即在事务提交后)。
事件在会话刷新时持久化的事实意味着您可以在
flush()后安全地clear()会话:在刷新之前检测到的实体更改事件将被正确持久化。如果您来自 Hibernate Search 5 或更早版本,您可能会将其视为一项重大改进:不再需要在事务中间调用
flushToIndexes()和更新索引。
- 后台处理器将完全从数据库重新加载实体
-
负责重新索引实体的后台处理器在实体更改发生时无法访问 一级缓存 的状态,因为它发生在不同的会话中。
这意味着每次实体更改并且需要重新索引时,后台进程都会完全加载该实体。根据您的映射,它可能还需要加载到其他实体的延迟关联。
可以通过以下方式在一定程度上缓解这种额外的成本
-
利用 Hibernate ORM 的批量获取;请参阅
batch_fetch_size属性 和@BatchSize注解。 -
利用 Hibernate ORM 的 二级缓存,特别是对于从索引实体引用的不可变实体(例如,国家、城市等参考数据)。
-
- 索引在事务提交时保证
-
当实体更改发生在事务内时,Hibernate Search 将在同一个事务中持久化实体更改事件。
如果事务提交,这些事件也将提交;如果事务回滚,事件也将回滚。这保证事件最终将被后台线程处理,并且索引将相应地更新,但只有在事务成功的情况下才会更新。
当实体更改发生在任何事务之外(不推荐)时,事件索引会在会话 flush()后立即发送。如果没有执行 flush 操作,索引将不会自动更新。
- 索引更改不会立即可见
-
默认情况下,应用程序线程将在实体更改事件提交到数据库后恢复。这意味着这些更改已安全存储到磁盘,但这并不意味着在线程恢复后立即运行的搜索查询将考虑这些更改:索引将在以后异步地在后台处理器中进行。
您可以 配置此事件处理器 运行更频繁,但它将保持异步。
19.3.3. 对数据库模式的影响
基础知识
outbox-polling 协调策略需要在应用程序数据库中的附加表中存储数据,以便后台线程可以消费这些数据。
这尤其包括一个 outbox 表,每次以需要重新索引的方式更改实体时,都会向该表推送一行(表示更改事件)。
这些表通过自动添加到 Hibernate ORM 配置中的实体进行访问,因此,在依赖 Hibernate ORM 的 自动模式生成 时,它们应该会自动生成。
如果您需要将这些表的创建/删除集成到自己的脚本中,最简单的解决方案是让 Hibernate ORM 为您的整个模式生成 DDL 脚本,并将与构造(表、序列等)相关的所有内容复制到以 HSEARCH_ 为前缀的名称。请参阅 自动模式生成,特别是 Hibernate ORM 属性 javax.persistence.schema-generation.scripts.action、javax.persistence.schema-generation.scripts.create-target 和 javax.persistence.schema-generation.scripts.drop-target。
自定义模式/表名等
默认情况下,上一节中提到的 outbox 和代理表预计将在默认目录/模式中找到,并且使用以 HSEARCH_ 为前缀的大写表名。用于这些表的标识生成器名称以 HSEARCH_ 为前缀,以 _GENERATOR 为后缀。
有时,数据库对象存在特定的命名约定,或者需要将域表和技术表分开。为了允许在这一领域具有一定的灵活性,Hibernate Search 提供了一组配置属性来指定目录/模式/表名以及 outbox 事件和代理表用于自定义 UUID 生成器策略/数据类型
# Configure the agent mapping:
hibernate.search.coordination.entity.mapping.agent.catalog=CUSTOM_CATALOG
hibernate.search.coordination.entity.mapping.agent.schema=CUSTOM_SCHEMA
hibernate.search.coordination.entity.mapping.agent.table=CUSTOM_AGENT_TABLE
hibernate.search.coordination.entity.mapping.agent.uuid_gen_strategy=time
hibernate.search.coordination.entity.mapping.agent.uuid_type=BINARY
# Configure the outbox event mapping:
hibernate.search.coordination.entity.mapping.outboxevent.catalog=CUSTOM_CATALOG
hibernate.search.coordination.entity.mapping.outboxevent.schema=CUSTOM_SCHEMA
hibernate.search.coordination.entity.mapping.outboxevent.table=CUSTOM_OUTBOX_TABLE
hibernate.search.coordination.entity.mapping.outboxevent.uuid_gen_strategy=time
hibernate.search.coordination.entity.mapping.outboxevent.uuid_type=BINARY-
agent.catalog定义用于代理表的数据库目录。默认为在 Hibernate ORM 中配置的默认目录。
-
agent.schema定义用于代理表的数据库模式。默认为在 Hibernate ORM 中配置的默认模式。
-
agent.table定义代理表的名称。默认为
HSEARCH_AGENT。 -
agent.uuid_gen_strategy定义用于代理表的 UUID 生成器策略的名称。可用选项为auto/random/time。auto是默认值,与random相同,它使用UUID#randomUUID()。time是一种基于 IP 的策略,与 IETF RFC 4122 一致。默认为
auto。 -
agent.uuid_type定义 用于在代理表中表示 UUID 的 HibernateSqlType的名称。Hibernate Search 提供了一个特殊的default选项,该选项将默认使用,并将根据所使用的数据库生成UUID/BINARY/CHAR之一。虽然目前 Hibernate Search 将使用方言的默认 数据库中 UUID 的表示形式,但这并非保证。如果需要特定类型,最好通过此属性显式提供它。请参阅 SqlTypes 以查看 Hibernate ORM 支持的可用类型代码列表。SQL 类型代码可以作为org.hibernate.type.SqlTypes中对应常量的名称传递,也可以作为整数传递。默认为
default。 -
outboxevent.catalog定义用于 outbox 事件表的数据库目录。默认为在 Hibernate ORM 中配置的默认目录。
-
outboxevent.schema定义用于 outbox 事件表的数据库模式。默认为在 Hibernate ORM 中配置的默认模式。
-
outboxevent.table定义 outbox 事件表的名称。默认为
HSEARCH_OUTBOX_EVENT。 -
outboxevent.uuid_gen_strategy定义用于 outbox 事件表的 UUID 生成器策略的名称。可用选项为auto/random/time。auto是默认值,与random相同,它使用UUID#randomUUID()。time是一种基于 IP 的策略,与 IETF RFC 4122 一致。默认为
auto。 -
outboxevent.uuid_type定义了用于在 outbox 事件表中表示 UUID 的 HibernateSqlType名称。Hibernate Search 提供了一个特殊的default选项,它将被默认使用,并将根据使用的数据库生成UUID/BINARY/CHAR之一。虽然 Hibernate Search 目前将在数据库中使用方言的默认 UUID 表示形式,但这并不保证。如果需要特定类型,最好通过此属性显式提供。请参考 SqlTypes 查看 Hibernate ORM 支持的可用类型代码列表。SQL 类型代码可以作为org.hibernate.type.SqlTypes中相应常量的名称或作为整数值传递。默认为
default。
|
如果您的应用程序依赖于 自动数据库模式生成,请确保底层数据库在指定目录/模式时支持它们。还要检查名称长度和大小写敏感性是否有任何限制。 |
|
不需要同时提供所有属性。例如,您可以只自定义模式。未指定的属性将使用其默认值。 |
19.3.4. 分片和脉冲
为了避免在不同的应用程序节点上不必要地对同一个实体进行多次索引,Hibernate Search 将实体划分为它称为“分片”的东西。
-
每个实体都属于一个分片。
-
参与 事件处理 的每个应用程序节点都唯一地分配了一个或多个分片,并且只处理与这些分片中的实体相关的事件。
为了可靠地分配分片,Hibernate Search 向数据库添加了一个代理表,并使用该表来注册参与索引的代理(大多数情况下,一个应用程序实例 = 一个代理 = 事件处理器)。注册的代理形成一个集群。
为了确保代理始终分配一个分片,并且一个分片从不分配给多个代理,每个代理将定期执行“脉冲”,更新和检查代理表。
脉冲期间发生的情况取决于代理类型。在“脉冲”期间
有关动态和静态分片的更多详细信息,请参阅以下部分。
19.3.5. 事件处理器
基础知识
在后台执行的 outbox-polling 协调策略的代理中,最重要的一个是事件处理器:它轮询 outbox 表以查找事件,然后在找到新事件时重新索引相应的实体。
可以使用以下配置属性配置事件处理器
hibernate.search.coordination.event_processor.enabled = true
hibernate.search.coordination.event_processor.polling_interval = 100
hibernate.search.coordination.event_processor.pulse_interval = 2000
hibernate.search.coordination.event_processor.pulse_expiration = 30000
hibernate.search.coordination.event_processor.batch_size = 50
hibernate.search.coordination.event_processor.transaction_timeout = 10
hibernate.search.coordination.event_processor.retry_delay = 15-
event_processor.enabled定义事件处理器是否启用,作为 布尔值。此属性的默认值为true,但可以将其设置为false以禁用某些应用程序节点上的事件处理,例如将某些节点专门用于 HTTP 请求处理,而其他节点专门用于事件处理。 -
event_processor.polling_interval定义在查询没有返回任何事件后,在对 outbox 事件表进行另一次查询之前等待多长时间,作为 整数值(以毫秒为单位)。此属性的默认值为100。较高的值意味着实体更改与其在索引中的相应更新之间存在更高的延迟,但在没有事件要处理时,对数据库的压力较小。
较低的值意味着实体更改与其在索引中的相应更新之间存在更低的延迟,但在没有事件要处理时,对数据库的压力更大。
-
event_processor.pulse_interval定义事件处理器在必须执行“脉冲”之前可以轮询事件多长时间,作为 整数值(以毫秒为单位)。此属性的默认值为2000。有关“脉冲”的信息,请参阅 分片基础知识。
脉冲间隔必须设置为介于轮询间隔(见上文)和过期间隔的三分之一 (1/3) 之间的值。
较低的值(更接近于轮询间隔)意味着当节点加入或离开集群时,浪费在不处理事件上的时间更少,并且减少了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险,但由于更频繁地检查代理列表,对数据库的压力更大。
较高的值(更接近于过期间隔)意味着当节点加入或离开集群时,浪费在不处理事件上的时间更多,并且增加了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险,但由于不那么频繁地检查代理列表,对数据库的压力更小。
-
event_processor.pulse_expiration定义事件处理器“脉冲”在将处理器视为断开连接并将其从集群中强制删除之前保持有效的持续时间,作为 整数值(以毫秒为单位)。此属性的默认值为30000。有关“脉冲”的信息,请参阅 分片基础知识。
过期间隔必须设置为至少是脉冲间隔(见上文)的 3 倍的值。
较低的值(更接近于脉冲间隔)意味着当节点由于崩溃或网络故障而突然离开集群时,浪费在不处理事件上的时间更少,但增加了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险。
较高的值(比脉冲间隔大得多)意味着当节点由于崩溃或网络故障而突然离开集群时,浪费在不处理事件上的时间更多,但减少了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险。
-
event_processor.batch_size定义在一个事务中最多处理多少个 outbox 事件,作为 整数值。此属性的默认值为50。较高的值意味着后台进程打开的事务数量更少,并且可能由于一级缓存(持久性上下文)而提高性能,但会增加内存使用量,在极端情况下可能会导致
OutOfMemoryErrors。 -
event_processor.transaction_timeout定义处理 outbox 事件的事务的超时时间,作为 整数值(以秒为单位)。仅在配置了 JTA 事务管理器时才有效。
当使用 JTA 并且未设置此属性时,Hibernate Search 将使用 JTA 事务管理器中配置的任何默认事务超时时间。
-
event_processor.retry_delay定义事件处理器在处理失败后必须等待多长时间才能重新处理事件,作为 正整数值(以秒为单位)。此属性的默认值为30。使用值
0表示尽快重新处理失败的事件,无需延迟。
分片
默认情况下,分片 是动态的:Hibernate Search 将每个应用程序实例注册到数据库中,并使用这些信息为每个应用程序实例动态分配一个唯一的分片,并在实例启动或停止时更新分配。动态分片不接受除 基础知识 之外的任何配置。
如果要显式配置分片,可以通过设置以下配置属性来使用静态分片
hibernate.search.coordination.event_processor.shards.total_count = 4
hibernate.search.coordination.event_processor.shards.assigned = 0-
shards.total_count定义分片的总数,作为 整数值。此属性没有默认值,如果要使用静态分片,则必须显式设置。它必须在所有分配了分片的应用程序节点上设置为相同的值。当设置此属性时,shards.assigned也必须设置 -
shards.assigned定义分配给应用程序节点的分片,作为 整数值 或多个以逗号分隔的整数值。此属性没有默认值,如果要使用静态分片,则必须显式设置。当设置此属性时,shards.total_count也必须设置。分片通过
[0, total_count - 1]范围内的索引来引用(有关total_count的信息,请参阅上文)。给定的应用程序节点必须分配至少一个分片,但可以通过将shards.assigned设置为以逗号分隔的列表(例如,0,3)来分配多个分片。
|
每个分片必须分配给一个且仅一个应用程序节点。 事件处理将一直不会启动,直到每个分片都只有一个节点。 |
例如,以下具有 4 个应用程序节点的配置将分片 0 分配给应用程序节点 #0,分片 1 分配给应用程序节点 #1,而应用程序节点 #2 和 #3 则不分配任何分片
# Node #0
hibernate.search.coordination.strategy = outbox-polling
hibernate.search.coordination.event_processor.shards.total_count = 2
hibernate.search.coordination.event_processor.shards.assigned = 0# Node #1
hibernate.search.coordination.strategy = outbox-polling
hibernate.search.coordination.event_processor.shards.total_count = 2
hibernate.search.coordination.event_processor.shards.assigned = 1# Node #2
hibernate.search.coordination.strategy = outbox-polling
hibernate.search.coordination.event_processor.enabled = false# Node #3
hibernate.search.coordination.strategy = outbox-polling
hibernate.search.coordination.event_processor.enabled = false处理顺序
可以使用配置属性调整处理 outbox 事件的顺序
hibernate.search.coordination.event_processor.order = auto可用选项包括
auto-
默认值。
根据方言和其他设置选择最安全、最合适的顺序
-
当使用基于时间的 UUID 用于 outbox 事件时(请参阅 对数据库模式的影响),选择
id。 -
否则,如果使用 Microsoft SQL Server 方言,选择
none。 -
否则,选择
time。
-
none-
以任何特定顺序处理 outbox 事件。
这实际上意味着事件将以数据库特定的、不确定的顺序进行使用。
在具有多个事件处理器的设置中,这降低了由事务死锁引起的后台故障的发生率(特别是对于 Microsoft SQL Server),这在技术上并不能“修复”事件处理(这些故障会通过自动重试进行处理),但可以提高性能并减少日志中不必要的噪音。
但是,这可能会导致某些特定事件的处理被不断推迟,因为较新的事件会在此特定事件之前被处理,这在写入密集型场景中可能是一个问题,在这些场景中,事件队列永远不会为空。
time-
按“时间”顺序处理 outbox 事件,即按创建事件的顺序。
这确保事件按创建顺序或多或少地进行处理,并避免由于在特定事件之前处理较新的事件而导致对特定事件的处理持续推迟的情况。
但是,在具有多个事件处理器的设置中,这可能会增加由于事务死锁(特别是对于 Microsoft SQL Server)导致的后台失败率,这在技术上不会中断事件处理(这些失败会通过重试自动处理),但可能会降低性能并导致日志中出现不必要的噪音。
id-
按标识符顺序处理 outbox 事件。
如果 outbox 事件标识符是基于时间的 UUID(参见 对数据库架构的影响),则其行为类似于
time,但没有死锁风险。如果 outbox 事件标识符是随机 UUID(参见 对数据库架构的影响),则其行为类似于
none。
19.3.6. 批量索引器
基础
绕过分片可能很危险,因为事件处理器和批量索引器同时索引同一个实体可能会在某些罕见情况下导致索引不同步。因此,为了完全安全,事件处理将在批量索引进行时暂停。事件仍然会生成和持久化,但它们的处理将延迟到批量索引完成为止。
事件处理的暂停是通过在代理表中注册批量索引器代理来实现的,事件处理器最终会检测到该代理并通过暂停自身来做出反应。当批量索引完成后,批量索引器代理将从代理表中删除,事件处理器会检测到并恢复事件处理。
批量索引器代理可以使用以下配置属性进行配置
hibernate.search.coordination.mass_indexer.polling_interval = 100
hibernate.search.coordination.mass_indexer.pulse_interval = 2000
hibernate.search.coordination.mass_indexer.pulse_expiration = 30000-
mass_indexer.polling_interval定义了在主动等待事件处理器暂停时,等待对代理表进行另一次查询的时间,以 整数 毫秒为单位。此属性的默认值为100。较低的值将缩短批量索引器代理检测到事件处理器最终暂停自身所需的时间,但会增加批量索引器代理主动等待时对数据库的压力。
较高值将增加批量索引器代理检测到事件处理器最终暂停自身所需的时间,但会降低批量索引器代理主动等待时对数据库的压力。
-
mass_indexer.pulse_interval定义了批量索引器在必须执行“脉冲”之前可以等待的时间,以 整数 毫秒为单位。此属性的默认值为2000。有关“脉冲”的信息,请参阅 分片基础知识。
脉冲间隔必须设置为介于轮询间隔(见上文)和过期间隔的三分之一 (1/3) 之间的值。
较低的值(更接近轮询间隔)意味着降低了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接,但由于批量索引器代理在代理表中的条目更新更频繁,因此对数据库的压力更大。
较高值(更接近过期间隔)意味着增加了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接,但由于批量索引器代理在代理表中的条目更新频率较低,因此对数据库的压力较小。
-
mass_indexer.pulse_expiration定义了事件处理器“脉冲”在被认为已断开连接并强制将其从集群中删除之前保持有效的时长,以 整数 毫秒为单位。此属性的默认值为30000。有关“脉冲”的信息,请参阅 分片基础知识。
过期间隔必须设置为至少是脉冲间隔(见上文)的 3 倍的值。
较低的值(更接近脉冲间隔)意味着当批量索引器代理由于崩溃而终止时,事件处理器不会处理事件的浪费时间更少,但增加了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接。
较高值(远大于脉冲间隔)意味着当批量索引器代理由于崩溃而终止时,事件处理器不会处理事件的浪费时间更多,但降低了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接。
19.3.7. 多租户
如果你使用 Hibernate ORM 的多租户支持,你需要 配置所有可能的租户标识符列表。
除此之外,多租户支持应该相当透明:Hibernate Search 只是为每个租户标识符复制事件处理器。
你可以使用不同的配置根来为不同的租户使用不同的配置
-
hibernate.search.coordination是默认根,其属性将用作所有租户的默认值。 -
hibernate.search.coordination.tenants.<tenant-identifier>是租户特定的根。
请参阅下面的示例。
节点 1
hibernate.search.multi_tenancy.tenant_ids=tenant1,tenant2,tenant3,tenant4
hibernate.search.coordination.strategy = outbox-polling
hibernate.search.coordination.tenants.tenant1.event_processor.enabled = false (1)| 1 | 此节点将处理所有租户的事件,除了 tenant1。 |
节点 2
hibernate.search.multi_tenancy.tenant_ids=tenant1,tenant2,tenant3,tenant4
hibernate.search.coordination.strategy = outbox-polling
hibernate.search.coordination.event_processor.enabled = false (1)
hibernate.search.coordination.tenants.tenant1.event_processor.enabled = true (2)| 1 | 此节点不会处理任何租户的事件… |
| 2 | … 除了 tenant1。 |
19.3.8. 中止的事件
如果在处理 outbox 事件时出现问题,事件处理器将尝试重新处理事件两次,之后该事件将被标记为中止。中止的事件将不会被处理器处理。
Hibernate Search 公开了用于处理中止事件的一些 API。
OutboxPollingSearchMapping searchMapping = Search.mapping( sessionFactory ).extension( OutboxPollingExtension.get() ); (1)
long count = searchMapping.countAbortedEvents(); (2)
searchMapping.reprocessAbortedEvents(); (3)
searchMapping.clearAllAbortedEvents(); (4)| 1 | 要访问 API,我们需要传递 OutboxPollingExtension |
| 2 | 统计中止的事件数 |
| 3 | 重新处理中止的事件 |
| 4 | 清除所有中止的事件 |
如果启用了多租户,则需要传递租户 ID 来指定要对该租户执行操作。
long count = searchMapping.countAbortedEvents( tenantId ); (1)
searchMapping.reprocessAbortedEvents( tenantId ); (2)
searchMapping.clearAllAbortedEvents( tenantId ); (3)| 1 | 统计给定租户 ID 中止的事件数 |
| 2 | 重新处理给定租户 ID 中止的事件 |
| 3 | 清除给定租户 ID 中止的所有事件 |
20. 标准和集成
20.1. Jakarta EE
Hibernate Search 目标是 Jakarta EE(在相关的情况下),特别是使用 Hibernate ORM 映射器 的 Jakarta Persistence 3.1。
20.3. Hibernate ORM 6
在以前的版本中,Hibernate Search 的主要 Maven 工件用于针对 Hibernate ORM 5,而单独的专用 Maven 工件则针对 Hibernate ORM 6。
现在情况不再如此:主要 Maven 工件现在针对 Hibernate ORM 6,而 Hibernate ORM 5 不再兼容。
如果你的依赖项包含对以 -orm6 结尾的工件的引用(例如 hibernate-search-mapper-orm-orm6),只需在升级到此版本的 Hibernate Search 时删除 -orm6(例如,改用 hibernate-search-mapper-orm)。
21. 已知问题和限制
21.1. 在没有协调的情况下,在极少数情况下,涉及 @IndexedEmbedded 的索引会导致索引不同步
21.1.1. 描述
使用默认设置(无协调),如果两个实体实例在同一个“索引嵌入”实体中被 索引嵌入,并且这两个实体实例在并行事务中被更新,则存在很小的风险,即事务提交以错误的方式发生,导致“索引嵌入”实体仅被部分更新后的数据重新索引。
例如,考虑索引实体 A,它索引嵌入 B 和 C。以下涉及两个并行事务(T1 和 T2)的事件过程将导致索引过时
-
T1:加载 B。
-
T1:以需要重新索引 A 的方式更改 B。
-
T2:加载 C。
-
T2:以需要重新索引 A 的方式更改 C。
-
T2:请求事务提交。Hibernate Search 构建 A 的文档。在构建时,它会自动加载 B。B 似乎未修改,因为 T1 尚未提交。
-
T1:请求事务提交。Hibernate Search 构建要索引的文档。在构建时,它会自动加载 C。C 似乎未修改,因为 T2 尚未提交。
-
T1:事务已提交。Hibernate Search 自动将更新后的 A 发送到索引。在此版本中,B 已更新,但 C 未更新。
-
T2:事务已提交。Hibernate Search 自动将更新后的 A 发送到索引。在此版本中,C 已更新,但 B 未更新。
此事件链以索引包含 A 的版本结束,其中 C 已更新,但 B 未更新。
21.1.2. 解决方案和解决方法
以下解决方案可以帮助规避此限制
-
使用更安全的 协调策略,例如
outbox-polling协调策略。特别是参见 架构示例。 -
或者避免对在同一个索引实体中索引嵌入的实体进行并行更新。这仅在非常特殊的设置中才有可能。
-
或者定期(例如,每天晚上)安排对数据库进行 完全重新索引,以使索引与数据库保持同步。
21.2. 在没有协调的情况下,索引期间的后端错误会导致索引不同步
21.2.1. 描述
因此,如果在索引过程中后端出现错误(即 I/O 错误),此索引将被取消,并且无法取消相应的数据库事务:因此,索引将变得不同步。
| 风险完全与后端错误相关,主要是文件系统或网络问题。在用户代码(getter、自定义 桥接器 等)中发生的错误将安全地取消整个数据库事务,而不会索引任何内容,从而确保索引仍然与数据库同步。 |
21.2.2. 解决方案和变通方法
以下解决方案可以帮助规避此限制
-
使用更安全的 协调策略,例如
outbox-polling协调策略。特别是参见 架构示例。 -
或者定期(例如,每天晚上)安排对数据库进行 完全重新索引,以使索引与数据库保持同步。
21.2.3. 路线图
此限制直接由实体变更事件缺乏持久性造成,因此只能通过持久化这些事件来完全解决,例如切换到 outbox-polling 协调策略。
一些不完全的应急措施可能会在未来版本中考虑,例如自动线程内重试,但它们永远无法完全解决问题,而且它们目前不在路线图上。
21.3. 监听器触发索引只考虑对 Hibernate ORM 会话中的实体实例直接应用的变更
21.3.1. 描述
由于 Hibernate Search 如何使用 Hibernate ORM 的内部事件 来检测变更,它将不会检测由 insert/delete/update 查询产生的变更,无论是 SQL 查询还是 JPQL/HQL 查询。
这是因为查询在数据库端执行,Hibernate ORM 或 Search 无法获知实际上创建、删除或更新了哪些实体。
21.3.2. 解决方案和变通方法
一种变通方法是在运行 JPQL/SQL 查询后显式地重新索引,可以使用 MassIndexer,使用 Jakarta Batch 批量索引作业,或者 显式地。
21.4. 监听器触发索引忽略非对称关联更新
21.4.1. 描述
Hibernate ORM 能够处理关联的非对称更新,其中只更新关联的拥有方,而忽略另一方。在会话持续时间内,会话中的实体将不一致,但由于实体加载方式,重新加载后它们将再次一致。
这种关联非对称更新的做法通常会在应用程序中引起问题,但在 Hibernate Search 中尤其如此,它可能会导致索引不同步。因此,必须避免这种情况。
例如,假设一个已索引实体 A 与实体 B 有一个 @IndexedEmbedded 关联 A.b,并且 B 在其侧拥有该关联,B.a。可以只将 B.a 设置为 null 来删除 A 和 B 之间的关联,对数据库的影响将完全是我们想要的。
但是,Hibernate Search 只能检测到 B.a 发生了变更,当它尝试推断哪些实体需要重新索引时,它将无法再知道 B.a 以前指的是什么。这种变更本身对 Hibernate Search 无用:Hibernate Search 将不知道具体是 A 需要重新索引。它将“忘记”重新索引 A,导致索引不同步,其中 A.b 仍然包含 B。
最终,Hibernate Search 唯一能知道 A 需要重新索引的方法是也将 A.b 设置为 null,这将导致 Hibernate Search 检测到 A.b 发生了变更,从而也检测到 A 发生了变更。
21.4.2. 解决方案和变通方法
以下解决方案可以帮助规避此限制
-
更新关联的一侧时,始终一致地更新另一侧。
-
如果上述方法不可行,则在关联更新后显式地重新索引受影响的实体,可以使用
MassIndexer,使用 Jakarta Batch 批量索引作业,或者 显式地。
21.4.3. 路线图
Hibernate Search 可能会在将来处理关联的非对称更新,方法是跟踪添加到/从关联中删除的实体。但是,只有在索引在后台线程中异步发生时,例如使用 outbox-polling 协调策略,才能完全解决问题。这被跟踪为 HSEARCH-3567。
或者,从数据库直接获取实体变更事件,例如使用 Debezium,也可以解决问题。这被跟踪为 HSEARCH-3513,但这是一个长期目标。
21.5. 监听器触发索引与 Session 序列化不兼容
21.5.1. 描述
当 监听器触发索引 启用时,Hibernate Search 会收集实体变更事件,以便在 ORM EntityManager/Session 中构建一个“索引计划”。索引计划保存与哪些实体需要重新索引相关的信息,有时还保存尚未索引的文档。
索引计划无法序列化。
如果 ORM Session 被序列化,所有收集的变更事件将在反序列化会话时丢失,Hibernate Search 可能会“忘记”重新索引一些实体。
这在大多数应用程序中是可以的,因为它们不依赖于序列化会话,但对于一些依赖于 Bean Passivation 的 JEE 应用程序来说可能是一个问题。
22. 故障排除
22.1. 找出幕后执行的内容
对于搜索查询,可以通过调用 toString() 或 queryString() 来获取 SearchQuery 对象 的人类可读表示。或者,依赖于日志:org.hibernate.search.query 将在执行之前以 TRACE 级别记录每个查询。
有关正在执行内容的更多一般信息,请依赖于记录器
-
org.hibernate.search.elasticsearch.request用于 Elasticsearch。
22.2. 记录器
以下是一些在调试使用 Hibernate Search 的应用程序时可能很有用的记录器
org.hibernate.search.query-
适用于所有后端。
在执行之前,以
TRACE级别记录每个搜索查询。 org.hibernate.search.elasticsearch.request-
仅适用于 Elasticsearch 后端。
以
DEBUG或TRACE级别记录发送到 Elasticsearch 的请求,并在执行后记录它们。所有可用的请求和响应信息都会被记录:方法、路径、执行时间、状态代码,以及完整的请求和响应。使用
DEBUG级别只记录非成功请求(状态代码不同于2xx),或者使用TRACE级别记录每个请求。可以使用 配置属性 为请求和响应启用漂亮打印(换行和缩进)。
org.hibernate.search.backend.lucene.infostream-
仅适用于 Lucene 后端。
以
TRACE级别记录有关 Lucene 内部组件的低级别跟踪信息。启用此记录器的
TRACE级别还不够:还必须使用 配置属性 启用 infostream。
22.3. 常见问题解答
22.3.1. 搜索命中结果中出现意外或缺少的文档
如果某些文档意外匹配或不匹配查询,则需要有关正在执行的精确查询以及索引内容的信息。
要找出正在执行的查询的确切外观,请参见 找出幕后执行的内容。
要检查索引的内容
-
使用 Elasticsearch 后端,直接使用 Hibernate Search 或 REST API 运行更简单的查询。
-
使用 Lucene 后端,使用 Hibernate Search 或 使用 Luke 工具(作为 Lucene 二进制包 的一部分进行分发)。
22.3.2. 按得分排序时搜索命中结果的顺序不令人满意
按得分排序时,如果文档没有按预期顺序显示,则表示某些文档的得分高于或低于预期。
获得这些分数洞察力的最佳方法是要求后端解释分数是如何计算的。返回的解释将包括对如何计算特定文档的分数的人类可读描述。
|
无论使用哪种 API,解释在性能方面都相当昂贵:仅将其用于调试目的。 |
有两种方法可以检索解释
-
如果您对特定实体感兴趣并知道其标识符:在查询上使用
explain(…)方法。请参见explain(…):解释分数。 -
如果您只需要对所有最佳命中结果进行解释:使用
explanation投影。请参见 Lucene 的说明 和 Elasticsearch 的说明。
23. 进一步阅读
23.1. Hibernate Search
Hibernate Search 网站 是寻找有关 Hibernate Search 信息的绝佳起点,无论是了解 版本、所有版本的文档、迁移指南、路线图,还是只是获取指向源代码和问题跟踪器的链接。
Hibernate Search 网站还包含指向 各种外部资源 的链接,例如博客文章和演讲。
要为 Hibernate Search 或任何 Hibernate 项目做出贡献或提出问题,请从同一网站上的 社区 页面开始。
最后,要查看在应用程序中使用 Hibernate Search 的示例,请参见
-
Quarkus 快速入门,这是一个使用 Hibernate Search 和 Quarkus 框架的示例应用程序。
-
"图书馆" 展示,这是一个使用 Hibernate Search 和 Spring Boot 框架的示例应用程序。
-
上面提到的 博客文章和演讲,其中大部分包含教程和/或简单应用程序。
23.2. Elasticsearch
Elasticsearch 的参考文档 是了解 Elasticsearch 的绝佳起点。
23.3. Lucene
要了解有关 Lucene 的更多信息,可以获取 Lucene in Action (第二版) 的副本,尽管它涵盖了 Lucene 的旧版本。
否则,您始终可以尝试使用 Lucene 的 Javadoc。
23.4. Hibernate ORM
如果您想深入了解 Hibernate ORM,可以从 在线文档 开始,或者获取一本 Java Persistence with Hibernate, Second Edition 的副本。
23.5. 其他
如果您对 Hibernate Search 有任何进一步的问题或反馈,请联系 Hibernate 社区。 我们期待您的来信。
如果您想报告错误,请使用 Hibernate Search JIRA 实例。
24. 鸣谢
Hibernate Search 的所有贡献者列表可以在 Hibernate Search 源代码中的 copyright.txt 文件中找到,该文件特别在我们的 git 存储库 中。
以下贡献者参与了本文档
-
Marko Bekhta
-
Emmanuel Bernard
-
Hardy Ferentschik
-
Gustavo Fernandes
-
Fabio Massimo Ercoli
-
Sanne Grinovero
-
Mincong Huang
-
Nabeel Ali Memon
-
Gunnar Morling
-
Yoann Rodière
-
Guillaume Smet
附录 A:所有可用配置属性列表
A.1. Hibernate Search 引擎
-
hibernate.search.background_failure_handler -
应在后台进程(主要是索引操作)中发生任何故障时通知的
FailureHandler实例。期望
FailureHandler类型bean的引用。默认值为
EngineSettings.Defaults.BACKGROUND_FAILURE_HANDLER,一个日志处理程序。 -
hibernate.search.configuration_property_checking.strategy -
如何报告配置属性检查的结果。
配置属性检查将检测从未使用的配置属性,这可能表明配置问题。
期望
ConfigurationPropertyCheckingStrategyName值,或该值的字符串表示形式。 -
hibernate.search.backend.type -
后端的类型。
仅当类路径中有多个后端技术时才有用;否则,将自动检测后端类型。
期望一个字符串,例如“lucene”或“elasticsearch”。 请参阅您的后端的文档以找到适当的值。
默认值
-
如果类路径中只有一个后端类型,则默认为该后端。
-
否则,无默认值:必须设置此属性。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.type
-
A.2. Hibernate Search 后端 - Lucene
-
hibernate.search.backend.analysis.configurer -
分析配置器。
期望
LuceneAnalysisConfigurer类型 bean 的单值或多值引用。默认值为无值。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.analysis.configurer
-
-
hibernate.search.backend.directory.filesystem_access.strategy -
如何访问目录中的文件系统。
仅适用于“local-filesystem”目录类型。
期望
FileSystemAccessStrategyName值,或该值的字符串表示形式。此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.directory.filesystem_access.strategy -
hibernate.search.backends.<backend-name>.directory.filesystem_access.strategy -
hibernate.search.backends.<backend-name>.indexes.<index-name>.directory.filesystem_access.strategy
-
-
hibernate.search.backend.directory.locking.strategy -
如何在目录上锁定。
期望
LockingStrategyName值,或该值的字符串表示形式。默认值特定于每种目录类型。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.directory.locking.strategy -
hibernate.search.backends.<backend-name>.directory.locking.strategy -
hibernate.search.backends.<backend-name>.indexes.<index-name>.directory.locking.strategy
-
-
hibernate.search.backend.directory.root -
目录的文件系统根目录。
仅适用于“local-filesystem”目录类型。
期望一个字符串,表示对现有目录的路径,该目录以读写模式访问,例如“local-filesystem”。
实际的索引文件将在目录
<root>/<index-name>中创建。默认值为 JVM 的工作目录。
默认值:
"."此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.directory.root -
hibernate.search.backends.<backend-name>.directory.root -
hibernate.search.backends.<backend-name>.indexes.<index-name>.directory.root
-
-
hibernate.search.backend.directory.type -
从索引读取或写入索引时使用的目录类型。
期望一个字符串,例如“local-filesystem”。 请参阅参考文档以了解可用值的列表。
默认值:
"local-filesystem"此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.directory.type -
hibernate.search.backends.<backend-name>.directory.type -
hibernate.search.backends.<backend-name>.indexes.<index-name>.directory.type
-
-
hibernate.search.backend.indexing.queue_count -
分配给每个索引的索引队列数量(或在启用分片时分配给每个索引的每个分片的索引队列数量)。
期望一个严格的正整数值,或一个可以解析为整数值的字符串。
请参阅参考文档中的“Lucene 后端 - 索引”部分,了解有关此设置及其影响的更多信息。
默认值:
10此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.indexing.queue_count -
hibernate.search.backends.<backend-name>.indexing.queue_count -
hibernate.search.backends.<backend-name>.indexes.<index-name>.indexing.queue_count
-
-
hibernate.search.backend.indexing.queue_size -
索引队列的大小。
期望一个严格的正整数值,或一个可以解析为整数值的字符串。
请参阅参考文档中的“Lucene 后端 - 索引”部分,了解有关此设置及其影响的更多信息。
默认值:
1000此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.indexing.queue_size -
hibernate.search.backends.<backend-name>.indexing.queue_size -
hibernate.search.backends.<backend-name>.indexes.<index-name>.indexing.queue_size
-
-
hibernate.search.backend.io.commit_interval -
索引更改后可能经过多长时间才能提交更改。
仅适用于“近实时”I/O 策略。
这实际上定义了更改可能处于“不安全”状态的时间,在此状态下,崩溃或电源故障会导致数据丢失。 例如
-
如果设置为 0,则更改在后台进程完成处理一批更改后立即变得安全。
-
如果设置为 1000,则更改在后台进程完成处理一批更改后可能在另外 1 秒内才安全。 不过,这样做也有好处:在距另一个更改不到 1 秒的时间内发生的索引更改可能执行得更快。
请注意,单个写入操作可能会触发强制提交(例如,使用 ORM 映射器中的
write-sync和sync索引计划同步策略),在这种情况下,您将仅在密集索引(批量索引器等)期间受益于非零提交间隔。请注意,提交**不是**使更改对搜索查询可见所必需的:这两个概念无关。 请参阅
IO_REFRESH_INTERVAL。期望以毫秒为单位的正整数,例如
1000,或一个可以解析为该整数的字符串。默认值:
1000此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.commit_interval -
hibernate.search.backends.<backend-name>.io.commit_interval -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.commit_interval
-
-
hibernate.search.backend.io.merge.calibrate_by_deletes -
要传递给
LogMergePolicy.setCalibrateSizeByDeletes(boolean)的值。期望一个布尔值,例如
true或false,或一个可以解析为该布尔值的字符串。此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.merge.calibrate_by_deletes -
hibernate.search.backends.<backend-name>.io.merge.calibrate_by_deletes -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.merge.calibrate_by_deletes
-
-
hibernate.search.backend.io.merge.factor -
要传递给
LogMergePolicy.setMergeFactor(int)的值。期望一个正整数值,或一个可以解析为该整数值的字符串。
此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.merge.factor -
hibernate.search.backends.<backend-name>.io.merge.factor -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.merge.factor
-
-
hibernate.search.backend.io.merge.max_docs -
要传递给
LogMergePolicy.setMaxMergeDocs(int)的值。期望一个正整数值,或一个可以解析为该整数值的字符串。
此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.merge.max_docs -
hibernate.search.backends.<backend-name>.io.merge.max_docs -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.merge.max_docs
-
-
hibernate.search.backend.io.merge.max_forced_size -
要传递给
LogByteSizeMergePolicy.setMaxMergeMBForForcedMerge(double)的值。期望以兆字节为单位的正整数值,或一个可以解析为该整数值的字符串。
此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.merge.max_forced_size -
hibernate.search.backends.<backend-name>.io.merge.max_forced_size -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.merge.max_forced_size
-
-
hibernate.search.backend.io.merge.max_size -
传递给
LogByteSizeMergePolicy.setMaxMergeMB(double)的值。期望以兆字节为单位的正整数值,或一个可以解析为该整数值的字符串。
此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.merge.max_size -
hibernate.search.backends.<backend-name>.io.merge.max_size -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.merge.max_size
-
-
hibernate.search.backend.io.merge.min_size -
传递给
LogByteSizeMergePolicy.setMinMergeMB(double)的值。期望以兆字节为单位的正整数值,或一个可以解析为该整数值的字符串。
此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.merge.min_size -
hibernate.search.backends.<backend-name>.io.merge.min_size -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.merge.min_size
-
-
hibernate.search.backend.io.refresh_interval -
索引写入后,索引读取器被视为陈旧并重新创建之前可能经过的时间。
仅适用于“近实时”I/O 策略。
这实际上定义了搜索查询结果可能有多陈旧。例如
-
如果设置为 0,搜索结果将始终与索引写入完全同步。
-
如果设置为 1000,搜索结果可能反映最多 1 秒前的索引状态。不过,这样做有一个好处:在频繁写入索引的情况下,在另一个查询后不到 1 秒执行的搜索查询可能会更快执行。
请注意,单个写入操作可能会触发强制刷新(例如,在 ORM 映射器中使用
read-sync和sync索引计划同步策略),在这种情况下,您只会在密集索引(批量索引器等)期间受益于非零刷新间隔。期望以毫秒为单位的正整数,例如
1000,或一个可以解析为该整数的字符串。默认值:
0此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.refresh_interval -
hibernate.search.backends.<backend-name>.io.refresh_interval -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.refresh_interval
-
-
hibernate.search.backend.io.strategy -
如何处理输入/输出,即如何写入和读取索引。
期望一个
IOStrategyName值,或此类值的字符串表示形式。此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.strategy -
hibernate.search.backends.<backend-name>.io.strategy -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.strategy
-
-
hibernate.search.backend.io.writer.infostream -
是否记录
IndexWriterConfig.setInfoStream(InfoStream)(在跟踪级别)或不记录。日志附加到记录器“org.hibernate.search.backend.lucene.infostream”。
期望一个布尔值,例如
true或false,或一个可以解析为该布尔值的字符串。默认为
false。此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.writer.infostream -
hibernate.search.backends.<backend-name>.io.writer.infostream -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.writer.infostream
-
-
hibernate.search.backend.io.writer.max_buffered_docs -
传递给
IndexWriterConfig.setMaxBufferedDocs(int)的值。期望一个正整数值,或一个可以解析为该整数值的字符串。
此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.writer.max_buffered_docs -
hibernate.search.backends.<backend-name>.io.writer.max_buffered_docs -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.writer.max_buffered_docs
-
-
hibernate.search.backend.io.writer.ram_buffer_size -
传递给
IndexWriterConfig.setRAMBufferSizeMB(double)的值。期望以兆字节为单位的正整数值,或一个可以解析为该整数值的字符串。
此设置的默认值由 Lucene 定义。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.io.writer.ram_buffer_size -
hibernate.search.backends.<backend-name>.io.writer.ram_buffer_size -
hibernate.search.backends.<backend-name>.indexes.<index-name>.io.writer.ram_buffer_size
-
-
hibernate.search.backend.lucene_version -
创建分析器时传递给分析器的 Lucene 版本。
应设置此项以在升级 Lucene 时获得一致的行为。
期望一个 Lucene
Version对象,或Version.parseLeniently(java.lang.String)接受的字符串。默认为
LuceneBackendSettings.Defaults.LUCENE_VERSION,当 Hibernate Search 或 Lucene 升级时该版本可能会发生变化,因此不提供任何向后兼容性保证。建议的做法是将此属性显式设置为要定位的 Lucene 版本。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.lucene_version
-
-
hibernate.search.backend.multi_tenancy.strategy -
如何实现多租户。
期望一个
MultiTenancyStrategyName值,或此类值的字符串表示形式。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.multi_tenancy.strategy
-
-
hibernate.search.backend.query.caching.configurer -
查询缓存的配置器。
期望一个单值或多值引用,引用类型为
QueryCachingConfigurer的 Bean。默认值为无值。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.query.caching.configurer
-
-
hibernate.search.backend.sharding.number_of_shards -
为索引创建的分片数量,即“物理”索引的数量,每个索引保存索引数据的一部分。
仅适用于
hash分片策略。期望一个严格为正的 Integer 值,例如 4,或一个可以解析为此类 Integer 值的字符串。
无默认值:使用
hash分片策略时,必须设置此属性。此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.sharding.number_of_shards -
hibernate.search.backends.<backend-name>.sharding.number_of_shards -
hibernate.search.backends.<backend-name>.indexes.<index-name>.sharding.number_of_shards
-
-
hibernate.search.backend.sharding.shard_identifiers -
索引接受的分片标识符列表。
仅适用于
explicit分片策略。期望一个包含多个分片标识符(用逗号 (,) 分隔)的字符串,或一个包含此类分片标识符的
Collection<String>。无默认值:使用
explicit分片策略时,必须设置此属性。此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.sharding.shard_identifiers -
hibernate.search.backends.<backend-name>.sharding.shard_identifiers -
hibernate.search.backends.<backend-name>.indexes.<index-name>.sharding.shard_identifiers
-
-
hibernate.search.backend.sharding.strategy -
分片策略,决定分片的数量、其标识符以及如何将路由键转换为分片标识符。
期望一个字符串,例如“hash”。有关可用值的列表,请参阅参考文档。
默认值:
"none"此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.sharding.strategy -
hibernate.search.backends.<backend-name>.sharding.strategy -
hibernate.search.backends.<backend-name>.indexes.<index-name>.sharding.strategy
-
-
hibernate.search.backend.thread_pool.size -
分配给后端的线程池的大小。
期望一个严格的正整数值,或一个可以解析为整数值的字符串。
有关此设置及其含义的更多信息,请参阅参考文档中的“Lucene 后端 - 线程”部分。
默认为 JVM 在启动时可用的处理器内核数量。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.thread_pool.size
-
A.3. Hibernate Search 后端 - Elasticsearch
-
hibernate.search.backend.analysis.configurer -
应用于此索引的分析配置器。
期望一个单值或多值引用,引用类型为
ElasticsearchAnalysisConfigurer的 Bean。默认值为无值。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.analysis.configurer -
hibernate.search.backends.<backend-name>.analysis.configurer -
hibernate.search.backends.<backend-name>.indexes.<index-name>.analysis.configurer
-
-
hibernate.search.backend.client.configurer -
一个
ElasticsearchHttpClientConfigurer,它定义自定义 HTTP 客户端配置。例如,它可用于调整 SSL 上下文以接受自签名证书。它允许覆盖其他 HTTP 客户端设置,例如
USERNAME或MAX_CONNECTIONS_PER_ROUTE。期望一个引用,引用类型为
ElasticsearchHttpClientConfigurer的 Bean。默认值为无值。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.client.configurer
-
-
hibernate.search.backend.connection_timeout -
建立与 Elasticsearch 服务器的连接时的超时。
期望一个以毫秒为单位的正 Integer 值,例如
3000,或一个可以解析为此类 Integer 值的字符串。默认值:
1000此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.connection_timeout
-
-
hibernate.search.backend.discovery.enabled -
是否启用 Elasticsearch 集群中节点的自动发现。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
false此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.discovery.enabled
-
-
hibernate.search.backend.discovery.refresh_interval -
如果启用自动发现,两次自动发现执行之间的间隔时间。
期望一个以秒为单位的正 Integer 值,例如
2,或一个可以解析为此类 Integer 值的字符串。默认值:
10此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.discovery.refresh_interval
-
-
hibernate.search.backend.dynamic_mapping -
Elasticsearch 映射中
dynamic_mapping属性的默认值。如果使用动态字段和字段模板,此设置将被忽略,因为字段模板会强制
dynamic_mapping为DynamicMapping.TRUE。此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.dynamic_mapping -
hibernate.search.backends.<backend-name>.dynamic_mapping -
hibernate.search.backends.<backend-name>.indexes.<index-name>.dynamic_mapping
-
-
hibernate.search.backend.hosts -
要连接到的 Elasticsearch 服务器的主机名和端口。
期望一个表示主机名和端口的字符串,例如
localhost或es.mycompany.com:4400,或者包含多个以逗号分隔的主机名和端口字符串的字符串,或者包含此类主机名和端口字符串的Collection<String>。可以指定多个服务器以进行负载均衡:请求将轮流分配给每个主机。
同时设置此属性和
URIS将导致在启动时抛出异常。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.hosts
-
-
hibernate.search.backend.indexing.max_bulk_size -
处理索引队列时创建的批量请求的最大大小。
期望一个严格的正整数值,或一个可以解析为整数值的字符串。
有关此设置及其影响的更多信息,请参见参考文档,"Elasticsearch 后端 - 索引"部分。
默认值:
100此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.indexing.max_bulk_size -
hibernate.search.backends.<backend-name>.indexing.max_bulk_size -
hibernate.search.backends.<backend-name>.indexes.<index-name>.indexing.max_bulk_size
-
-
hibernate.search.backend.indexing.queue_count -
分配给每个索引的索引队列的数量。
期望一个严格的正整数值,或一个可以解析为整数值的字符串。
有关此设置及其影响的更多信息,请参见参考文档,"Elasticsearch 后端 - 索引"部分。
默认值:
10此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.indexing.queue_count -
hibernate.search.backends.<backend-name>.indexing.queue_count -
hibernate.search.backends.<backend-name>.indexes.<index-name>.indexing.queue_count
-
-
hibernate.search.backend.indexing.queue_size -
索引队列的大小。
期望一个严格的正整数值,或一个可以解析为整数值的字符串。
有关此设置及其影响的更多信息,请参见参考文档,"Elasticsearch 后端 - 索引"部分。
默认值:
1000此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.indexing.queue_size -
hibernate.search.backends.<backend-name>.indexing.queue_size -
hibernate.search.backends.<backend-name>.indexes.<index-name>.indexing.queue_size
-
-
hibernate.search.backend.layout.strategy -
如何确定索引名称和别名。
期望一个类型为
IndexLayoutStrategy的 Bean 的引用。默认值为
simple策略-
非别名名称遵循以下格式
<hibernateSearchIndexName>-<6 位数字> -
写入别名遵循以下格式
<hibernateSearchIndexName>-write -
读取别名遵循以下格式
<hibernateSearchIndexName>-read
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.layout.strategy
-
-
hibernate.search.backend.log.json_pretty_printing -
日志中包含的 JSON 是否应该进行美化打印(缩进,并带换行符)。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
false此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.log.json_pretty_printing
-
-
hibernate.search.backend.mapping.type_name.strategy -
如何将文档映射到其类型名称,即如何在搜索命中中确定文档的类型名称。
期望一个
TypeNameMappingStrategyName值,或者此类值的字符串表示。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.mapping.type_name.strategy
-
-
hibernate.search.backend.max_connections -
与 Elasticsearch 集群的同步连接的最大数量,所有主机加在一起。
期望一个正整数,例如
20,或者可以解析为此类整数的字符串。默认值:
20此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.max_connections
-
-
hibernate.search.backend.max_connections_per_route -
与 Elasticsearch 集群中每个主机的同步连接的最大数量。
期望一个正整数,例如
10,或者可以解析为此类整数的字符串。默认值:
10此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.max_connections_per_route
-
-
hibernate.search.backend.max_keep_alive -
与 Elasticsearch 集群的连接保持空闲的时间。
期望一个正的毫秒数,例如 60000,或者可以解析为此类整数的字符串。
如果来自 Elasticsearch 集群的响应包含
Keep-Alive标头,则有效的最大空闲时间将是两者中较低的一个:Keep-Alive标头中的持续时间或此属性的值(如果已设置)。如果未设置此属性,则只考虑
Keep-Alive标头,如果不存在,则空闲连接将永远保持活动状态。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.max_keep_alive
-
-
hibernate.search.backend.multi_tenancy.strategy -
如何实现多租户。
期望一个
MultiTenancyStrategyName值,或者此类值的字符串表示。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.multi_tenancy.strategy
-
-
hibernate.search.backend.password -
连接到 Elasticsearch 服务器时要发送的密码(HTTP 身份验证)。
期望一个字符串。
默认值为无用户名(匿名访问)。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.password
-
-
hibernate.search.backend.path_prefix -
用于指定添加到请求端点的路径前缀的属性。如果您的 Elasticsearch 实例位于特定上下文路径,请使用路径前缀。
默认值:
""此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.path_prefix
-
-
hibernate.search.backend.protocol -
连接到 Elasticsearch 服务器时要使用的协议。
期望一个字符串:
http或https。同时设置此属性和
URIS将导致在启动时抛出异常。默认值:
"http"此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.protocol
-
-
hibernate.search.backend.query.shard_failure.ignore -
此属性定义是否忽略部分分片故障。
如果所有分片都失败,Elasticsearch 集群本身将返回 400 状态码,但如果只有一部分分片失败,则客户端将从成功的分片接收成功的部分响应。
为了防止获得任何部分结果,可以将此设置设置为
false。如果应忽略部分故障并将其视为有效结果,则应将值设置为true。期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
false此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.query.shard_failure.ignore
-
-
hibernate.search.backend.read_timeout -
从 Elasticsearch 服务器读取响应时的超时时间。
期望一个正整数,以毫秒为单位,例如
60000,或者可以解析为此类整数的字符串。默认值:
30000此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.read_timeout
-
-
hibernate.search.backend.request_timeout -
对 Elasticsearch 服务器执行请求时的超时时间。
这包括建立连接、发送请求和读取响应所需的时间。
期望一个正整数,以毫秒为单位,例如 60000,或者可以解析为此类整数的字符串。
默认值为无请求超时。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.request_timeout
-
-
hibernate.search.backend.schema_management.mapping_file -
映射文件的路径,允许为 Hibernate Search 创建的索引提供自定义映射,作为架构管理的一部分。
期望一个表示类路径中 UTF-8 编码文件的路径的字符串。该文件必须包含以 JSON 格式表达的索引设置,其语法与 Elasticsearch 服务器在 "mappings" 属性下期望的语法完全相同 定义索引的映射时。
该文件不需要包含完整的映射:Hibernate Search 会自动将给定映射中缺少的属性(索引字段)注入其中。
给定映射与 Hibernate Search 生成的映射之间的冲突将按如下方式处理
-
映射根目录下除了
properties以外的映射参数将来自给定映射;由 Hibernate Search 生成的那些参数将被忽略。 -
properties将被合并,使用在给定映射和由 Hibernate Search 生成的映射中定义的属性。如果一个属性在两边都定义,则将使用来自给定映射的映射参数,除了properties,它将以相同的方式递归合并。
默认值为无值,这意味着将只使用由 Hibernate Search 生成的索引映射。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.schema_management.mapping_file -
hibernate.search.backends.<backend-name>.schema_management.mapping_file -
hibernate.search.backends.<backend-name>.indexes.<index-name>.schema_management.mapping_file
-
-
hibernate.search.backend.schema_management.minimal_required_status -
启动时索引的最低要求状态,Hibernate Search 才能开始使用它。
期望一个
IndexStatus值,或者此类值的字符串表示。默认值为
yellow,目标是支持索引状态检查的 Elasticsearch 发行版,当目标是支持索引状态检查的 Elasticsearch 发行版(例如 Amazon OpenSearch Serverless)时,默认值为无值(无要求)。此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.schema_management.minimal_required_status -
hibernate.search.backends.<backend-name>.schema_management.minimal_required_status -
hibernate.search.backends.<backend-name>.indexes.<index-name>.schema_management.minimal_required_status
-
-
hibernate.search.backend.schema_management.minimal_required_status_wait_timeout -
等待
所需状态时的超时时间。期望一个正整数,以毫秒为单位,例如
60000,或者可以解析为此类整数的字符串。默认值:
10000此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.schema_management.minimal_required_status_wait_timeout -
hibernate.search.backends.<backend-name>.schema_management.minimal_required_status_wait_timeout -
hibernate.search.backends.<backend-name>.indexes.<index-name>.schema_management.minimal_required_status_wait_timeout
-
-
hibernate.search.backend.schema_management.settings_file -
设置文件的路径,允许为 Hibernate Search 作为架构管理的一部分创建的索引自定义设置。
期望一个字符串,表示类路径中 UTF-8 编码文件的路径。该文件必须包含以 JSON 格式表示的索引设置,与 Elasticsearch 服务器在“settings”属性下期望的语法完全相同 创建索引时。例如,如果文件内容为
{"index.codec": "best_compression"},它将把index.codec设置为best_compression。请注意,如果某些定义发生冲突,Hibernate Search 生成的设置将被覆盖。例如,如果分析器“myAnalyzer”由
ANALYSIS_CONFIGURER和 此设置文件定义,则来自设置文件的定义将优先。如果它仅在分析配置器或设置文件中定义,而不在两者中都定义,则它将按原样保留。默认为无值,这意味着将仅使用 Hibernate Search 生成的索引设置。
此配置属性的变体(点击打开)
-
hibernate.search.backend.indexes.<index-name>.schema_management.settings_file -
hibernate.search.backends.<backend-name>.schema_management.settings_file -
hibernate.search.backends.<backend-name>.indexes.<index-name>.schema_management.settings_file
-
-
hibernate.search.backend.scroll_timeout -
用于指定如果从 Elasticsearch 中没有获取其他结果,
scroll可用的最长时间的属性。期望以秒为单位的正整数,例如 60,或可以解析为该整数的字符串。
默认值:
60此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.scroll_timeout
-
-
hibernate.search.backend.thread_pool.size -
分配给后端的线程池的大小。
期望一个严格的正整数值,或一个可以解析为整数值的字符串。
有关此设置及其影响的更多信息,请参阅参考文档中的“Elasticsearch 后端 - 线程”部分。
默认为 JVM 在启动时可用的处理器内核数量。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.thread_pool.size
-
-
hibernate.search.backend.uris -
要连接的 Elasticsearch 服务器的协议、主机名和端口。
期望一个表示 URI 的字符串,例如
https://或https://es.mycompany.com:4400,或一个包含多个用逗号分隔的此类 URI 的字符串,或一个包含此类 URI 的Collection<String>。所有 URI 必须指定相同的协议。
默认情况下为
https://:9200,除非设置了HOSTS或PROTOCOL,在这种情况下,它们将优先。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.uris
-
-
hibernate.search.backend.username -
连接到 Elasticsearch 服务器时要发送的用户名(HTTP 身份验证)。
期望一个字符串。
默认值为无用户名(匿名访问)。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.username
-
-
hibernate.search.backend.version -
在 Elasticsearch 集群上运行的 Elasticsearch 版本。
期望一个
ElasticsearchVersion对象,或一个可以解析为该对象的字符串。无默认值:如果未提供,将在启动时通过向 Elasticsearch 集群发送请求来自动解析版本。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.version
-
-
hibernate.search.backend.version_check.enabled -
是否启用检查 Elasticsearch 集群的版本。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。当
VERSION未配置或设置为支持版本检查的分布式版本时,默认为true,当VERSION设置为不支持版本检查的分布式版本(如 Amazon OpenSearch Serverless)时,默认为false。默认值:
true此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.version_check.enabled
-
A.4. Hibernate Search 后端 - Elasticsearch - AWS 集成
-
hibernate.search.backend.aws.credentials.access_key_id -
使用
静态凭据时的 AWS 访问密钥 ID。期望一个字符串值,例如
AKIDEXAMPLE。无默认值:启用签名并且凭据类型设置为
ElasticsearchAwsCredentialsTypeNames.STATIC时,必须提供该值。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.aws.credentials.access_key_id
-
-
hibernate.search.backend.aws.credentials.secret_access_key -
使用
静态凭据时的 AWS 秘密访问密钥。期望一个字符串值,例如
wJalrXUtnFEMI/K7MDENG+bPxRfiCYEXAMPLEKEY无默认值:启用签名并且凭据类型设置为
ElasticsearchAwsCredentialsTypeNames.STATIC时,必须提供该值。此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.aws.credentials.secret_access_key
-
-
hibernate.search.backend.aws.credentials.type -
启用签名时要使用的凭据类型
启用。期望
ElasticsearchAwsCredentialsTypeNames中列出的常量之一。默认值:
"default"此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.aws.credentials.type
-
-
hibernate.search.backend.aws.region -
AWS 区域。
期望一个字符串值,例如
us-east-1。无默认值:启用签名时必须提供该值。
此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.aws.region
-
-
hibernate.search.backend.aws.signing.enabled -
是否应使用 AWS 凭据对请求进行签名。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
false此配置属性的变体(点击打开)
-
hibernate.search.backends.<backend-name>.aws.signing.enabled
-
A.5. Hibernate Search ORM 集成
-
hibernate.search.automatic_indexing.enable_dirty_check -
已弃用。
此设置将在未来版本中删除。将不会提供替代方案来替换它。在未来版本中删除此属性后,在考虑是否触发重新索引时,将始终执行脏检查。
在实际重新索引实体之前,是否检查脏属性是否与索引相关。
启用后,如果仅对与索引无关的属性进行更改,则会跳过实体的重新索引。此功能被认为是安全的,因此默认情况下启用。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
true -
hibernate.search.automatic_indexing.enabled -
已弃用。
是否启用监听器触发的索引,即是否自动检测 Hibernate ORM 会话中对实体的更改并导致重新索引。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
true -
hibernate.search.automatic_indexing.strategy -
已弃用。
请改用
INDEXING_LISTENERS_ENABLED(注意:它期望一个布尔值)。如何启用或禁用监听器触发的索引。
期望一个
AutomaticIndexingStrategyName值,或该值的字符串表示形式。 -
hibernate.search.automatic_indexing.synchronization.strategy -
已弃用。
如何在应用程序线程和由
SearchIndexingPlan触发的索引之间同步。期望
AutomaticIndexingSynchronizationStrategyNames中定义的字符串之一,或对类型为AutomaticIndexingSynchronizationStrategy的 Bean 的引用。 -
hibernate.search.coordination.strategy -
如何在分布式应用程序的节点之间协调。
期望一个对协调策略的引用;有关可用策略和相关 Maven 依赖项,请参阅参考文档。
-
hibernate.search.enabled -
是否启用或禁用 Hibernate Search。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
true -
hibernate.search.indexing.listeners.enabled -
是否启用 Hibernate ORM 监听器,这些监听器可以检测实体更改并自动触发索引操作。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
true -
hibernate.search.indexing.mass.default_clean_operation -
在批量索引期间应用的默认索引清理操作,除非显式配置。
期望一个
MassIndexingDefaultCleanOperation值,或该值的字符串表示形式。 -
hibernate.search.indexing.plan.synchronization.strategy -
如何在应用程序线程和由
SearchIndexingPlan触发的索引之间同步。期望
IndexingPlanSynchronizationStrategyNames中定义的字符串之一,或IndexingPlanSynchronizationStrategy类型 bean 的引用。 -
hibernate.search.mapping.build_missing_discovered_jandex_indexes -
当
启用注解处理(默认)时,Hibernate Search 是否应自动为注册用于注解处理的类型(尤其是实体)构建 Jandex 索引,以确保这些 JAR 中的所有“根映射”注解(例如ProjectionConstructor)都被考虑在内。期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
true -
hibernate.search.mapping.configurer -
Hibernate Search 映射的配置器。
期望单个值或多个值的引用,这些引用指向
HibernateOrmSearchMappingConfigurer类型的 bean。默认值为无值。
-
hibernate.search.mapping.discover_annotated_types_from_root_mapping_annotations -
当
启用注解处理(默认)时,Hibernate Search 是否应自动发现 Jandex 索引中存在的已注解类型,这些类型也已使用根映射注解注解。启用后,如果在 Jandex 索引中找到用
RootMapping元注解的注解,并且在 Jandex 索引中找到用该注解注解的类型(例如SearchEntity或ProjectionConstructor),则将自动扫描该类型以查找映射注解,即使该类型未被明确添加。期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值为
HibernateOrmMapperSettings.Defaults.MAPPING_DISCOVER_ANNOTATED_TYPES_FROM_ROOT_MAPPING_ANNOTATIONS。默认值:
true -
hibernate.search.mapping.process_annotations -
是否应自动处理实体类型的注解,以及这些实体类型中的嵌套类型,例如
index-embedded类型。期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
true -
hibernate.search.multi_tenancy.tenant_identifier_converter -
如何将租户标识符转换为字符串表示形式,以及从字符串表示形式转换为对象表示形式。
将租户标识符转换为要写入索引的字符串表示形式,并将字符串转换为其对象表示形式,以便在必须打开新的 Hibernate ORM 会话时使用。
启用多租户功能时,如果使用非字符串租户标识符,则 **必须** 通过此属性提供自定义转换器。
默认值为
HibernateOrmMapperSettings.Defaults.MULTI_TENANCY_TENANT_IDENTIFIER_CONVERTER。此转换器仅支持字符串租户标识符,如果使用其他类型的标识符,则会失败。 -
hibernate.search.multi_tenancy.tenant_ids -
启用多租户功能时,应用程序可以使用的所有租户标识符的详尽列表。
期望一个表示多个租户 ID(用逗号分隔)的字符串,或一个包含租户 ID 的
Collection<String>。无默认值;根据
协调策略,可能需要显式设置此属性。 -
hibernate.search.query.loading.cache_lookup.strategy -
在为搜索查询加载实体时,如何在二级缓存中查找实体。
期望一个
EntityLoadingCacheLookupStrategy值,或该值的字符串表示形式。 -
hibernate.search.query.loading.fetch_size -
在为搜索查询加载实体时,每次数据库查询要加载的实体数量。
期望一个严格正的 Integer 值,例如
100,或可以解析为该 Integer 值的字符串。默认值:
100 -
hibernate.search.schema_management.strategy -
启动和关闭时如何创建、更新、验证或删除索引及其架构。
期望一个
SchemaManagementStrategyName值,或该值的字符串表示形式。
A.6. Hibernate Search ORM 集成 - 协调 - Outbox 轮询
-
hibernate.search.coordination.entity.mapping.agent.catalog -
要用于代理表的数据库目录。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
默认值为 Hibernate ORM 中配置的默认目录。请参阅
MappingSettings.DEFAULT_CATALOG。 -
hibernate.search.coordination.entity.mapping.agent.schema -
要用于代理表的数据库模式。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
默认值为 Hibernate ORM 中配置的默认模式。请参阅
MappingSettings.DEFAULT_SCHEMA。 -
hibernate.search.coordination.entity.mapping.agent.table -
代理表的名称。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
此值的默认值为 "HSEARCH_AGENT"。
默认值:
"HSEARCH_AGENT" -
hibernate.search.coordination.entity.mapping.agent.uuid_gen_strategy -
代理表使用的 UUID 生成器策略的名称,由
UuidGenerator使用。仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
-
hibernate.search.coordination.entity.mapping.agent.uuid_type -
用于在代理表中表示 UUID 的
Hibernate ORM 常量类型代码,用于标识通用 SQL 类型的名称。仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
此值的默认值为
HibernateOrmMapperOutboxPollingSettings.Defaults.COORDINATION_ENTITY_MAPPING_AGENT_UUID_TYPE。默认值:
"default" -
hibernate.search.coordination.entity.mapping.outboxevent.catalog -
要用于 outbox 事件表的数据库目录。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
默认值为 Hibernate ORM 中配置的默认目录。请参阅
MappingSettings.DEFAULT_CATALOG。 -
hibernate.search.coordination.entity.mapping.outboxevent.schema -
要用于 outbox 事件表的数据库模式。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
默认值为 Hibernate ORM 中配置的默认模式。请参阅
MappingSettings.DEFAULT_SCHEMA。 -
hibernate.search.coordination.entity.mapping.outboxevent.table -
outbox 事件表的名称。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
此值的默认值为 "HSEARCH_OUTBOX_EVENT"。
-
hibernate.search.coordination.entity.mapping.outboxevent.uuid_gen_strategy -
outbox 事件表使用的 UUID 生成器策略的名称,由
UuidGenerator使用。仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
-
hibernate.search.coordination.entity.mapping.outboxevent.uuid_type -
用于在 outbox 事件表中表示 UUID 的
Hibernate ORM 常量类型代码,用于标识通用 SQL 类型的名称。仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
-
hibernate.search.coordination.event_processor.batch_size -
在事件处理器中,单个事务最多处理的 outbox 事件数量。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
期望一个正的 Integer 值,例如
50,或可以解析为该 Integer 值的字符串。默认值:
50 -
hibernate.search.coordination.event_processor.enabled -
应用程序是否将处理实体更改事件。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。禁用事件处理器时,每当实体更改时,此应用程序节点仍会生成事件,但此应用程序节点不会进行索引,并假定在另一个节点上进行索引。
默认值:
true -
hibernate.search.coordination.event_processor.order -
在事件处理器中,出站事件的处理顺序。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
需要
OutboxEventProcessingOrder中定义的“外部表示”字符串之一。 -
hibernate.search.coordination.event_processor.polling_interval -
在事件处理器中,在一次查询没有返回任何事件后,等待再次查询出站事件表的时长,以毫秒为单位。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
如果上次轮询没有返回任何事件,Hibernate Search 会等待这段时间后再次轮询。
-
较高的值意味着实体更改与其在索引中的相应更新之间存在更高的延迟,但在没有事件要处理时,对数据库的压力较小。
-
较低的值意味着实体更改与其在索引中的相应更新之间存在更低的延迟,但在没有事件要处理时,对数据库的压力更大。
期望以毫秒为单位的正整数,例如
1000,或一个可以解析为该整数的字符串。默认值为
HibernateOrmMapperOutboxPollingSettings.Defaults.COORDINATION_EVENT_PROCESSOR_POLLING_INTERVAL。默认值:
100 -
-
hibernate.search.coordination.event_processor.pulse_expiration -
事件处理器“脉冲”在被认为代理断开连接并强制从集群中删除之前有效的时长,以毫秒为单位。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
每个代理都会在数据库表中注册自身。定期地,在轮询要处理的事件时,批量索引器代理执行一个
"脉冲":它会暂停正在执行的操作(以及其他事项),并更新其在表中的条目,以告知其他代理它仍然处于活动状态并防止过期。如果代理未能更新其条目超过过期间隔值,它将被视为断开连接:其他代理将强制删除其在表中的条目,并在必要时执行重新平衡(重新分配分片)。过期间隔必须设置为至少是
脉冲间隔的 3 倍。-
较低的值(更接近于脉冲间隔)意味着当节点由于崩溃或网络故障而突然离开集群时,浪费在不处理事件上的时间更少,但增加了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险。
-
较高的值(比脉冲间隔大得多)意味着当节点由于崩溃或网络故障而突然离开集群时,浪费在不处理事件上的时间更多,但减少了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险。
需要一个以毫秒为单位的正整数,例如
30000,或者一个可以解析为该整数的字符串。默认值为
HibernateOrmMapperOutboxPollingSettings.Defaults.COORDINATION_EVENT_PROCESSOR_PULSE_EXPIRATION。默认值:
30000 -
-
hibernate.search.coordination.event_processor.pulse_interval -
事件处理器在必须执行“脉冲”之前可以轮询事件的时长,以毫秒为单位。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
每个代理都会在数据库表中注册自身。定期地,在轮询要处理的事件时,事件处理器执行一个“脉冲”:
-
它会更新自身在表中的条目,以告知其他代理它仍然处于活动状态并防止过期。
-
它会删除表中任何过期的其他代理。
-
如果它注意到批量索引器正在运行,它会挂起自身。
-
如果参与后台索引的代理数量自上次脉冲以来发生了变化,它会执行重新平衡(重新分配分片)。
-
较低的值(更接近于轮询间隔)意味着当节点加入或离开集群时,浪费在不处理事件上的时间更少,并且减少了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险,但由于更频繁地检查代理列表,对数据库的压力更大。
-
较高的值(更接近于过期间隔)意味着当节点加入或离开集群时,浪费在不处理事件上的时间更多,并且增加了由于事件处理器被错误地视为断开连接而浪费在不处理事件上的时间的风险,但由于不那么频繁地检查代理列表,对数据库的压力更小。
需要一个以毫秒为单位的正整数,例如
2000,或者一个可以解析为该整数的字符串。默认值:
2000 -
-
hibernate.search.coordination.event_processor.retry_delay -
事件处理器在处理失败后,必须等待多长时间才能重新处理事件。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
需要一个以秒为单位的正整数,例如
10,或者一个可以解析为该整数的字符串。使用值
0可以立即重新处理失败的事件,无需延迟。默认值:
30 -
hibernate.search.coordination.event_processor.shards.assigned -
分配给此应用程序节点用于事件处理的分片的索引。
警告: 分片必须唯一地分配给一个且仅一个应用程序节点。如果未能做到这一点,某些事件可能无法处理,或者可能会被处理两次或以错误的顺序处理,从而导致错误和/或索引不同步。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
需要一个分片索引,即介于
0(包含)和总分片数量(不包含)之间的整数,或者一个可以解析为该分片索引的字符串,或者一个包含多个以逗号分隔的分片索引字符串的字符串,或者一个包含这些分片索引的Collection<Integer>。没有默认值:如果要使用静态分片,则必须显式提供。
-
hibernate.search.coordination.event_processor.shards.total_count -
跨所有应用程序节点用于事件处理的总分片数量。
警告: 此属性对于所有应用程序节点必须具有相同的值,并且绝不能更改,除非所有应用程序节点都已停止,然后重新启动。如果未能做到这一点,某些事件可能无法处理,或者可能会被处理两次或以错误的顺序处理,从而导致错误和/或索引不同步。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
需要一个至少为
2的整数,或者一个可以解析为该整数的字符串。没有默认值:如果要使用静态分片,则必须显式提供。
-
hibernate.search.coordination.event_processor.transaction_timeout -
在事件处理器中,处理出站事件的事务超时时间。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
仅在配置了 JTA 事务管理器时才有效。
需要一个以秒为单位的正整数,例如
10,或者一个可以解析为该整数的字符串。当使用 JTA 并且未设置此属性时,Hibernate Search 将使用 JTA 事务管理器中配置的任何默认事务超时时间。
-
hibernate.search.coordination.mass_indexer.polling_interval -
在批量索引器中,当主动等待事件处理器挂起自身时,等待再次查询代理表的时长,以毫秒为单位。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
当发现其他代理尚未挂起时,Hibernate Search 会等待这段时间后再次轮询。
-
较低的值将缩短批量索引器代理检测到事件处理器最终暂停自身所需的时间,但会增加批量索引器代理主动等待时对数据库的压力。
-
较高值将增加批量索引器代理检测到事件处理器最终暂停自身所需的时间,但会降低批量索引器代理主动等待时对数据库的压力。
期望以毫秒为单位的正整数,例如
1000,或一个可以解析为该整数的字符串。默认值:
100 -
-
hibernate.search.coordination.mass_indexer.pulse_expiration -
批量索引器代理“脉冲”在被认为代理断开连接并强制从集群中删除之前有效的时长,以毫秒为单位。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
每个代理都会在数据库表中注册自身。定期地,在轮询要处理的事件时,每个代理都会执行一个
"脉冲":它会暂停正在执行的操作(以及其他事项),并更新其在表中的条目,以告知其他代理它仍然处于活动状态并防止过期。如果代理未能更新其条目超过过期间隔值,它将被视为断开连接:其他代理将强制删除其在表中的条目,并将继续执行操作,就好像过期的代理不存在一样。过期间隔必须设置为至少是
脉冲间隔的 3 倍。-
较低的值(更接近脉冲间隔)意味着当批量索引器代理由于崩溃而终止时,事件处理器不会处理事件的浪费时间更少,但增加了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接。
-
较高值(远大于脉冲间隔)意味着当批量索引器代理由于崩溃而终止时,事件处理器不会处理事件的浪费时间更多,但降低了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接。
需要一个以毫秒为单位的正整数,例如
30000,或者一个可以解析为该整数的字符串。默认值:
30000 -
-
hibernate.search.coordination.mass_indexer.pulse_interval -
批量索引器在必须执行“脉冲”之前可以等待的时长,以毫秒为单位。
仅在 "hibernate.search.coordination.strategy" 为 "outbox-polling" 时可用。
每个代理都会在数据库表中注册自身。定期地,批量索引器执行一个“脉冲”:
-
它会更新自身在表中的条目,以告知其他代理它仍然处于活动状态并防止过期。
-
它会删除表中任何过期的其他代理。
-
较低的值(更接近轮询间隔)意味着降低了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接,但由于批量索引器代理在代理表中的条目更新更频繁,因此对数据库的压力更大。
-
较高值(更接近过期间隔)意味着增加了事件处理器在批量索引期间再次开始处理事件的风险,因为批量索引器代理被错误地认为已断开连接,但由于批量索引器代理在代理表中的条目更新频率较低,因此对数据库的压力较小。
需要一个以毫秒为单位的正整数,例如
2000,或者一个可以解析为该整数的字符串。默认值:
2000 -
-
hibernate.search.coordination.tenants -
特定于租户的协调属性的根属性,例如“hibernate.search.coordination.tenants.tenant1.something = somevalue”。
A.7. Hibernate Search Mapper - POJO 独立
-
hibernate.search.indexing.mass.default_clean_operation -
在批量索引期间应用的默认索引清理操作,除非显式配置。
期望一个
MassIndexingDefaultCleanOperation值,或该值的字符串表示形式。 -
hibernate.search.indexing.plan.synchronization.strategy -
如何在应用程序线程和由
SearchSession的索引计划触发的索引之间进行同步。需要
IndexingPlanSynchronizationStrategy中定义的字符串之一,或者对IndexingPlanSynchronizationStrategy类型的 Bean 的引用。 -
hibernate.search.mapping.build_missing_discovered_jandex_indexes -
Hibernate Search 是否应该自动为注册用于注解处理的类型(尤其是实体)构建 Jandex 索引,以确保这些 JAR 中的所有“根映射”注解(例如
ProjectionConstructor)都被考虑在内。期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值:
true -
hibernate.search.mapping.configurer -
Hibernate Search 映射的配置器。
期望类型为
StandalonePojoMappingConfigurer的单值或多值引用。默认值为无值。
-
hibernate.search.mapping.discover_annotated_types_from_root_mapping_annotations -
Hibernate Search 是否应该自动发现 Jandex 索引中存在的并用
根映射注解注解的类型。启用后,如果在 Jandex 索引中找到用
RootMapping元注解的注解,并且在 Jandex 索引中找到用该注解注解的类型(例如SearchEntity或ProjectionConstructor),则将自动扫描该类型以查找映射注解,即使该类型未被明确添加。期望一个 Boolean 值,例如
true或false,或一个可以解析为 Boolean 值的字符串。默认值为
StandalonePojoMapperSettings.Defaults.MAPPING_DISCOVER_ANNOTATED_TYPES_FROM_ROOT_MAPPING_ANNOTATIONS。默认值:
true -
hibernate.search.mapping.multi_tenancy.enabled -
启用或禁用多租户功能。
如果启用多租户功能,每个
session都需要分配一个租户标识符。期望一个布尔值。
默认值:
false -
hibernate.search.mapping.multi_tenancy.tenant_identifier_converter -
如何将租户标识符转换为字符串表示形式,以及从字符串表示形式转换为对象表示形式。
启用多租户功能时,如果使用非字符串租户标识符,则 **必须** 通过此属性提供自定义转换器。
默认值为
StandalonePojoMapperSettings.Defaults.MULTI_TENANCY_TENANT_IDENTIFIER_CONVERTER。 此转换器仅支持字符串租户标识符,如果使用其他类型的标识符,则会失败。 -
hibernate.search.schema_management.strategy -
模式管理策略,控制索引及其模式在启动和关闭时如何创建、更新、验证或删除。
期望一个
SchemaManagementStrategyName值或此值的字符串表示形式。